| Oracle® Database Administrator's Guide 10g Release 1 (10.1) Part Number B10739-01 |
|
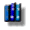





|
View PDF |
| Oracle® Database Administrator's Guide 10g Release 1 (10.1) Part Number B10739-01 |
|
|
View PDF |
This chapter describes aspects of managing clusters. It contains the following topics relating to the management of indexed clusters, clustered tables, and cluster indexes:
A cluster provides an optional method of storing table data. A cluster is made up of a group of tables that share the same data blocks. The tables are grouped together because they share common columns and are often used together. For example, the emp and dept table share the deptno column. When you cluster the emp and dept tables (see Figure 17-1), Oracle Database physically stores all rows for each department from both the emp and dept tables in the same data blocks.
Because clusters store related rows of different tables together in the same data blocks, properly used clusters offer two primary benefits:
Disk I/O is reduced and access time improves for joins of clustered tables.
The cluster key is the column, or group of columns, that the clustered tables have in common. You specify the columns of the cluster key when creating the cluster. You subsequently specify the same columns when creating every table added to the cluster. Each cluster key value is stored only once each in the cluster and the cluster index, no matter how many rows of different tables contain the value.
Therefore, less storage might be required to store related table and index data in a cluster than is necessary in nonclustered table format. For example, in Figure 17-1, notice how each cluster key (each deptno) is stored just once for many rows that contain the same value in both the emp and dept tables.
After creating a cluster, you can create tables in the cluster. However, before any rows can be inserted into the clustered tables, a cluster index must be created. Using clusters does not affect the creation of additional indexes on the clustered tables; they can be created and dropped as usual.
You should not use clusters for tables that are frequently accessed individually.
|
See Also:
|
The following sections describe guidelines to consider when managing clusters, and contains the following topics:
Specify the Space Required by an Average Cluster Key and Its Associated Rows
Estimate Cluster Size and Set Storage Parameters
|
See Also:
|
Use clusters for tables for which the following conditions are true:
The tables are primarily queried--that is, tables that are not predominantly inserted into or updated.
Records from the tables are frequently queried together or joined.
Choose cluster key columns carefully. If multiple columns are used in queries that join the tables, make the cluster key a composite key. In general, the characteristics that indicate a good cluster index are the same as those for any index. For information about characteristics of a good index, see "Guidelines for Managing Indexes".
A good cluster key has enough unique values so that the group of rows corresponding to each key value fills approximately one data block. Having too few rows for each cluster key value can waste space and result in negligible performance gains. Cluster keys that are so specific that only a few rows share a common value can cause wasted space in blocks, unless a small SIZE was specified at cluster creation time (see "Specify the Space Required by an Average Cluster Key and Its Associated Rows ").
Too many rows for each cluster key value can cause extra searching to find rows for that key. Cluster keys on values that are too general (for example, male and female) result in excessive searching and can result in worse performance than with no clustering.
A cluster index cannot be unique or include a column defined as long.
By specifying the PCTFREE and PCTUSED parameters during the creation of a cluster, you can affect the space utilization and amount of space reserved for updates to the current rows in the data blocks of a cluster data segment. PCTFREE and PCTUSED parameters specified for tables created in a cluster are ignored; clustered tables automatically use the settings specified for the cluster.
|
See Also: "Managing Space in Data Blocks" for information about setting thePCTFREE and PCTUSED parameters |
The CREATE CLUSTER statement has an optional clause, SIZE, which is the estimated number of bytes required by an average cluster key and its associated rows. The database uses the SIZE parameter when performing the following tasks:
Estimating the number of cluster keys (and associated rows) that can fit in a clustered data block
Limiting the number of cluster keys placed in a clustered data block. This maximizes the storage efficiency of keys within a cluster.
SIZE does not limit the space that can be used by a given cluster key. For example, if SIZE is set such that two cluster keys can fit in one data block, any amount of the available data block space can still be used by either of the cluster keys.
By default, the database stores only one cluster key and its associated rows in each data block of the cluster data segment. Although block size can vary from one operating system to the next, the rule of one key for each block is maintained as clustered tables are imported to other databases on other machines.
If all the rows for a given cluster key value cannot fit in one block, the blocks are chained together to speed access to all the values with the given key. The cluster index points to the beginning of the chain of blocks, each of which contains the cluster key value and associated rows. If the cluster SIZE is such that more than one key fits in a block, blocks can belong to more than one chain.
If you have the proper privileges and tablespace quota, you can create a new cluster and the associated cluster index in any tablespace that is currently online. Always specify the TABLESPACE clause in a CREATE CLUSTER/INDEX statement to identify the tablespace to store the new cluster or index.
The cluster and its cluster index can be created in different tablespaces. In fact, creating a cluster and its index in different tablespaces that are stored on different storage devices allows table data and index data to be retrieved simultaneously with minimal disk contention.
The following are benefits of estimating cluster size before creating the cluster:
You can use the combined estimated size of clusters, along with estimates for indexes and redo log files, to determine the amount of disk space that is required to hold an intended database. From these estimates, you can make correct hardware purchases and other decisions.
You can use the estimated size of an individual cluster to better manage the disk space that the cluster will use. When a cluster is created, you can set appropriate storage parameters and improve I/O performance of applications that use the cluster.
Whether or not you estimate table size before creation, you can explicitly set storage parameters when creating each nonclustered table. Any storage parameter that you do not explicitly set when creating or subsequently altering a table automatically uses the corresponding default storage parameter set for the tablespace in which the table resides. Clustered tables also automatically use the storage parameters of the cluster.
To create a cluster in your schema, you must have the CREATE CLUSTER system privilege and a quota for the tablespace intended to contain the cluster or the UNLIMITED TABLESPACE system privilege.
To create a cluster in another user's schema you must have the CREATE ANY CLUSTER system privilege, and the owner must have a quota for the tablespace intended to contain the cluster or the UNLIMITED TABLESPACE system privilege.
You create a cluster using the CREATE CLUSTER statement. The following statement creates a cluster named emp_dept, which stores the emp and dept tables, clustered by the deptno column:
CREATE CLUSTER emp_dept (deptno NUMBER(3)) PCTUSED 80 PCTFREE 5 SIZE 600 TABLESPACE users STORAGE (INITIAL 200K NEXT 300K MINEXTENTS 2 MAXEXTENTS 20 PCTINCREASE 33);
If no INDEX keyword is specified, as is true in this example, an index cluster is created by default. You can also create a HASH cluster, when hash parameters (HASHKEYS, HASH IS, or SINGLE TABLE HASHKEYS) are specified. Hash clusters are described in Chapter 18, " Managing Hash Clusters".
To create a table in a cluster, you must have either the CREATE TABLE or CREATE ANY TABLE system privilege. You do not need a tablespace quota or the UNLIMITED TABLESPACE system privilege to create a table in a cluster.
You create a table in a cluster using the CREATE TABLE statement with the CLUSTER clause. The emp and dept tables can be created in the emp_dept cluster using the following statements:
CREATE TABLE emp ( empno NUMBER(5) PRIMARY KEY, ename VARCHAR2(15) NOT NULL, . . . deptno NUMBER(3) REFERENCES dept) CLUSTER emp_dept (deptno); CREATE TABLE dept ( deptno NUMBER(3) PRIMARY KEY, . . . ) CLUSTER emp_dept (deptno);
|
Note: You can specify the schema for a clustered table in theCREATE TABLE statement. A clustered table can be in a different schema than the schema containing the cluster. Also, the names of the columns are not required to match, but their structure must match. |
|
See Also: Oracle Database SQL Reference for syntax of theCREATE TABLE statement for creating cluster tables |
To create a cluster index, one of the following conditions must be true:
Your schema contains the cluster.
You have the CREATE ANY INDEX system privilege.
In either case, you must also have either a quota for the tablespace intended to contain the cluster index, or the UNLIMITED TABLESPACE system privilege.
A cluster index must be created before any rows can be inserted into any clustered table. The following statement creates a cluster index for the emp_dept cluster:
CREATE INDEX emp_dept_index ON CLUSTER emp_dept TABLESPACE users STORAGE (INITIAL 50K NEXT 50K MINEXTENTS 2 MAXEXTENTS 10 PCTINCREASE 33) PCTFREE 5;
The cluster index clause (ON CLUSTER) identifies the cluster, emp_dept, for which the cluster index is being created. The statement also explicitly specifies several storage settings for the cluster and cluster index.
|
See Also: Oracle Database SQL Reference for syntax of theCREATE INDEX statement for creating cluster indexes |
To alter a cluster, your schema must contain the cluster or you must have the ALTER ANY CLUSTER system privilege. You can alter an existing cluster to change the following settings:
Physical attributes (PCTFREE, PCTUSED, INITRANS, and storage characteristics)
The average amount of space required to store all the rows for a cluster key value (SIZE)
The default degree of parallelism
Additionally, you can explicitly allocate a new extent for the cluster, or deallocate any unused extents at the end of the cluster. The database dynamically allocates additional extents for the data segment of a cluster as required. In some circumstances, however, you might want to explicitly allocate an additional extent for a cluster. For example, when using Real Application Clusters, you can allocate an extent of a cluster explicitly for a specific instance. You allocate a new extent for a cluster using the ALTER CLUSTER statement with the ALLOCATE EXTENT clause.
When you alter data block space usage parameters (PCTFREE and PCTUSED) or the cluster size parameter (SIZE) of a cluster, the new settings apply to all data blocks used by the cluster, including blocks already allocated and blocks subsequently allocated for the cluster. Blocks already allocated for the table are reorganized when necessary (not immediately).
When you alter the transaction entry setting INITRANS of a cluster, the new setting for INITRANS applies only to data blocks subsequently allocated for the cluster.
The storage parameters INITIAL and MINEXTENTS cannot be altered. All new settings for the other storage parameters affect only extents subsequently allocated for the cluster.
To alter a cluster, use the ALTER CLUSTER statement. The following statement alters the emp_dept cluster:
ALTER CLUSTER emp_dept PCTFREE 30 PCTUSED 60;
You can alter clustered tables using the ALTER TABLE statement. However, any data block space parameters, transaction entry parameters, or storage parameters you set in an ALTER TABLE statement for a clustered table generate an error message (ORA-01771, illegal option for a clustered table). The database uses the parameters of the cluster for all clustered tables. Therefore, you can use the ALTER TABLE statement only to add or modify columns, drop non-cluster-key columns, or add, drop, enable, or disable integrity constraints or triggers for a clustered table. For information about altering tables, see "Altering Tables".
You alter cluster indexes exactly as you do other indexes. See "Altering Indexes".
|
Note: When estimating the size of cluster indexes, remember that the index is on each cluster key, not the actual rows. Therefore, each key appears only once in the index. |
A cluster can be dropped if the tables within the cluster are no longer needed. When a cluster is dropped, so are the tables within the cluster and the corresponding cluster index. All extents belonging to both the cluster data segment and the index segment of the cluster index are returned to the containing tablespace and become available for other segments within the tablespace.
To drop a cluster that contains no tables, and its cluster index, use the DROP CLUSTER statement. For example, the following statement drops the empty cluster named emp_dept:
DROP CLUSTER emp_dept;
If the cluster contains one or more clustered tables and you intend to drop the tables as well, add the INCLUDING TABLES clause of the DROP CLUSTER statement, as follows:
DROP CLUSTER emp_dept INCLUDING TABLES;
If the INCLUDING TABLES clause is not included and the cluster contains tables, an error is returned.
If one or more tables in a cluster contain primary or unique keys that are referenced by FOREIGN KEY constraints of tables outside the cluster, the cluster cannot be dropped unless the dependent FOREIGN KEY constraints are also dropped. This can be easily done using the CASCADE CONSTRAINTS clause of the DROP CLUSTER statement, as shown in the following example:
DROP CLUSTER emp_dept INCLUDING TABLES CASCADE CONSTRAINTS;
The database returns an error if you do not use the CASCADE CONSTRAINTS clause and constraints exist.
To drop a cluster, your schema must contain the cluster or you must have the DROP ANY CLUSTER system privilege. You do not need additional privileges to drop a cluster that contains tables, even if the clustered tables are not owned by the owner of the cluster.
Clustered tables can be dropped individually without affecting the cluster, other clustered tables, or the cluster index. A clustered table is dropped just as a nonclustered table is dropped, with the DROP TABLE statement. See "Dropping Table Columns ".
|
Note: When you drop a single table from a cluster, the database deletes each row of the table individually. To maximize efficiency when you intend to drop an entire cluster, drop the cluster including all tables by using theDROP CLUSTER statement with the INCLUDING TABLES clause. Drop an individual table from a cluster (using the DROP TABLE statement) only if you want the rest of the cluster to remain. |
A cluster index can be dropped without affecting the cluster or its clustered tables. However, clustered tables cannot be used if there is no cluster index; you must re-create the cluster index to allow access to the cluster. Cluster indexes are sometimes dropped as part of the procedure to rebuild a fragmented cluster index. For information about dropping an index, see "Dropping Indexes".
The following views display information about clusters:
| View | Description |
|---|---|
DBA_CLUSTERS
|
DBA view describes all clusters in the database. ALL view describes all clusters accessible to the user. USER view is restricted to clusters owned by the user. Some columns in these views contain statistics that are generated by the DBMS_STATS package or ANALYZE statement. |
DBA_CLU_COLUMNS
|
These views map table columns to cluster columns |
|
 Copyright © 2001, 2003 Oracle Corporation All Rights Reserved. |
|