| Oracle® Database 2 Day DBA 10g Release 1 (10.1) Part Number B10742-02 |
|
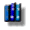





|
View PDF |
| Oracle® Database 2 Day DBA 10g Release 1 (10.1) Part Number B10742-02 |
|
|
View PDF |
Monitoring the health of a database and ensuring that it performs optimally is an important task for a database administrator. the This chapter discusses the features and functionality included in Oracle Database that make it easy to proactively monitor database health, identify performance problems, and implement any corrective actions.
The following topics are covered:
The Oracle Database makes it easy to proactively monitor the health and performance of your database. It monitors the vital signs (or metrics) related to database health, analyzes the workload running against the database, and automatically identifies any issues that need your attention as an administrator. The identified issues are either presented as alerts in Enterprise Manager or, if you prefer, can be sent you through email.
This section discusses the following topics:
Alerts help you monitor your database proactively. Most alerts are notifications when particular metrics thresholds are crossed. For each alert, you can set critical and warning threshold values. These threshold values are meant to be boundary values that when crossed indicate that the system is in an undesirable state. For example, when a tablespace becomes 97% full this can be considered undesirable and have Oracle generate a critical alert.
Other alerts correspond to database events such as Snapshot Too Old or Resumable Session suspended. These types of alerts indicate that the event has occurred.
In addition to notification, you can set alerts to perform some action such as running a script. Scripts that shrink tablespace objects can be useful for a Tablespace Usage warning alert.
By default, Oracle enables the following alerts: Table Space Usage (warning at 85% full, critical at 97% full), Snapshot Too Old, Recovery Area Low on Free Space, and Resumable Session Suspended. You can modify these alerts or enable others by setting their metrics.
Oracle Database includes a self-diagnostic engine called the Automatic Database Diagnostic Monitor (ADDM). ADDM makes it possible for the Oracle Database to diagnose its own performance and determine how any identified problems can be resolved.To facilitate automatic performance diagnosis using ADDM, Oracle Database periodically (once an hour by default) collects information about the database state and workload it is running. This information is gathered in form of snapshots, which is a statistical summary of the state of the system at any given point in time. These snapshots are stored in the Automatic Workload Repository, residing in the SYSAUX tablespace. The snapshots are stored in this repository for a set time (a week by default) before they are purged in order to make room for new snapshots.ADDM examines data captured in AWR and performs analysis to determine the major issues on the system on a proactive basis and in many cases recommends solutions and quantifies expected benefits.
Generally, the problems detected by ADDM include the following:
CPU Bottlenecks
Poor connection management
Excessive parsing
Lock contention
I/O capacity
Under sizing of Oracle memory structures such as the PGA, buffer cache, or log buffer
High load SQL statements
High PL/SQL and Java time
RAC specific issues
For more information about using ADDM, see "Diagnosing Performance Problems".
The Enterprise Manager home page enables you to monitor the health of your database. It provides a central place for general database state information and is updated periodically. This page reports information that is helpful for monitoring database state and workload.
The General section provides a quick view of the database, such as whether the database is Up or Down, the time the database was last started, instance name, host name, and the time of the most recent entry in the alert log.
The Host CPU section shows the percentage of CPU time used in the overall system. This chart breaks down CPU percentage into time used by the database and time used by other processes. If your database is taking up most of the CPU time, you can explore the cause further by looking at the Active Sessions summary. This summary tells you what the database processes are doing, such as which ones are using CPU, or waiting on I/O. You can drill down for more information by clicking a link, such as CPU.
If other processes are taking up most of your CPU time, this indicates that some other application running on the database machine may be the cause of the performance problems. To investigate this further, click the Host link under the General section. This link takes you to machine overview page where you can see some general information about the machine such as what operating system it is running, how long has the machine been up, and any potential problems. Clicking the Performance property page takes you to the machine performance summary page.
If you view the Performance Summary, you can see CPU utilization, memory utilization, and disk utilization over time. Below these graphs, you can also view the top ten processes in the CPU. The type of actions you can take to relieve this kind of load depends on your system, but can include eliminating unnecessary processes, adding memory, or adding CPUs.
On the Home page, the Diagnostic Summary summarizes the latest ADDM performance findings, This section also summarizes any critical or warning alerts listed in the Alerts section.
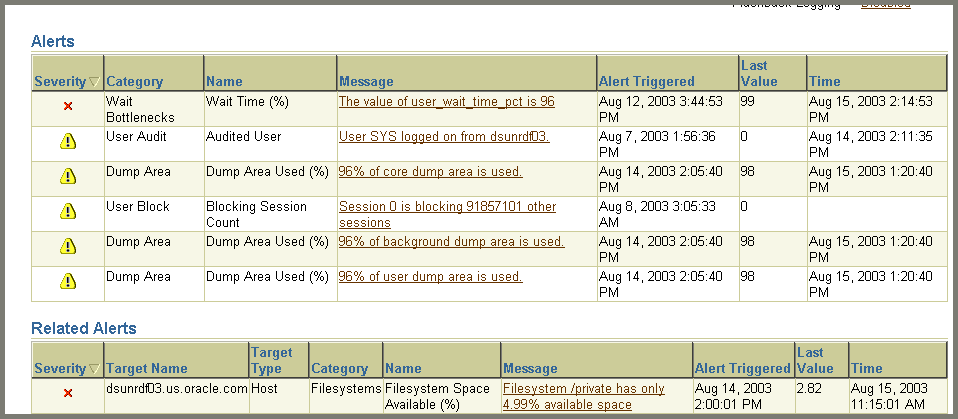
The Alerts table provides information about any alerts that have been issued along with the severity rating of each. An alert is a notification when a metric threshold is crossed. For example, an alert can be triggered when a tablespace is running out of space.
When an alert is triggered, the name of the metric causing it is displayed in the Name column. The severity icon (Warning or Critical) is displayed, along with time of alert, alert value, time the metric was last checked. You can click the message to learn more about the cause. For more information, see "Alerts".
The Performance Analysis section provides a quick summary of the latest ADDM findings, highlighting the issues that are causing the most significant performance impact. This analysis can identify problems such as SQL statements that are consuming significant database time. For more information, see "Performance Self-Diagnostics: Automatic Database Diagnostics Monitor ".
The following sections describe how to manage alerts.
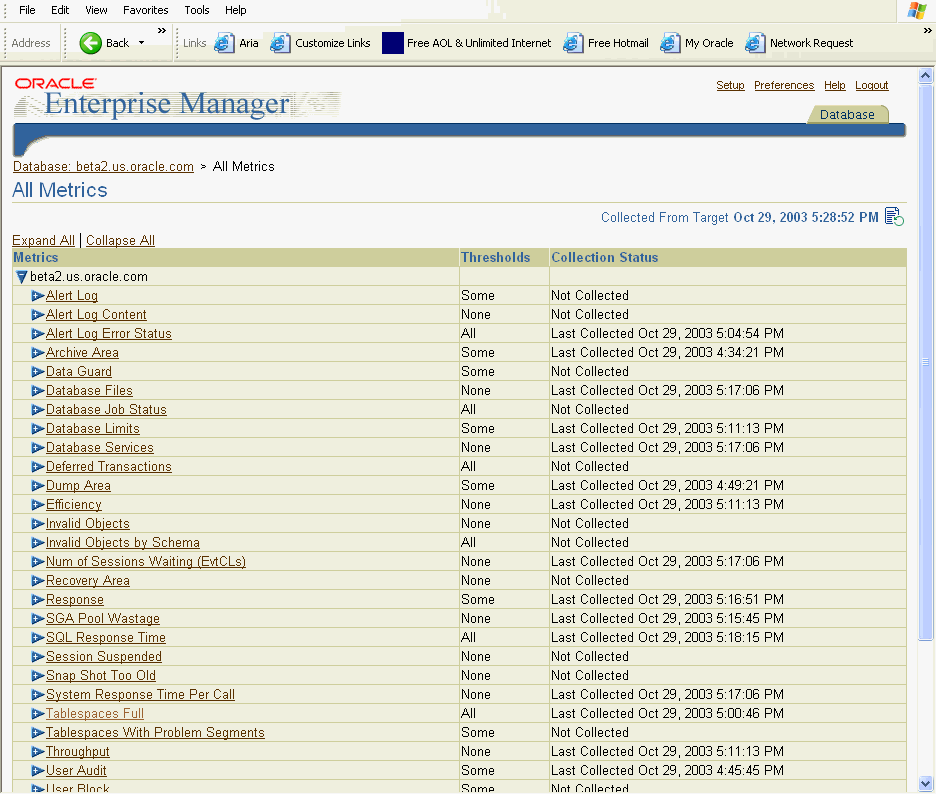
Metrics are a set of statistics for certain system attributes as defined by Oracle. They are computed and stored by the Automatic Workload Repository, and are displayed on the All Metrics page, which is viewable by clicking All Metrics under Related Links heading on the Database Home page (and some other pages). Figure 10-1 shows a portion of the All Metrics page, displaying some of the metrics that AWR computes. When you click a specific metric link, a detail page appears, with more information about the metric. Online help for this page gives you a description of the metric.
For each of these metrics, you are able to define warning and critical threshold values, and whenever the threshold is crossed, Oracle issues an alert.
Alerts are displayed on the Database Home page under the Alerts heading (or Related Alerts for non-database alerts such as a component of Oracle Net) as shown in Figure 10-2.
Setting thresholds is discussed in "Setting Metric Thresholds". Actions you might take to respond to alerts are discussed in "Responding to Alerts".
When the condition that triggered the alert is resolved and the metric's value is no longer outside the boundary, Oracle clears the alert. Metrics are important for measuring the health of the database and serve as input for self-tuning and recommendations made by Oracle advisors.
Oracle provides a set of predefined metrics, some of which initially have thresholds defined for them. There may be times when you want to set thresholds for other metrics, or you want to alter existing threshold settings.
One means of setting a threshold was introduced in "Creating a Tablespace", where you could set warning and critical thresholds on the amount of space consumed in a tablespace.
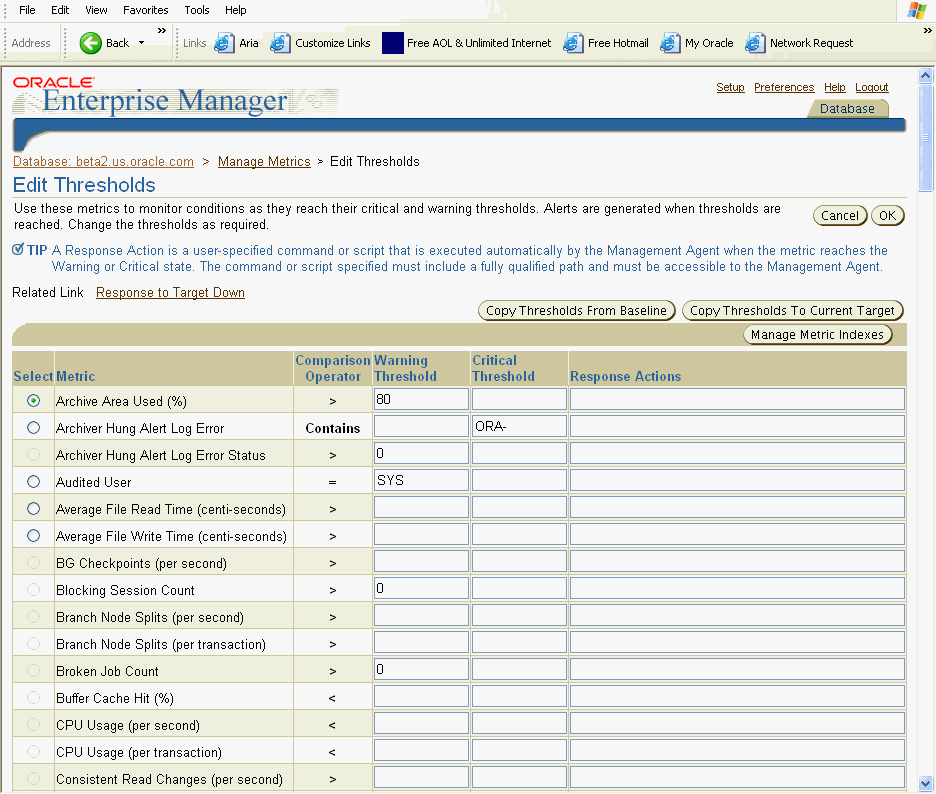
A more general means of setting thresholds is available using the Edit Thresholds page.
The following steps describe how to set metric thresholds:
From the Database Home page, click Manage Metrics under the Related Links heading.
The Manage Metrics page is displayed. It displays the existing thresholds for metrics and any response actions that have been specified. You cannot edit any thresholds on this page.
Click Edit Thresholds.
The Edit Thresholds page, shown in Figure 10-3, is displayed. On this page you can enter new Warning Threshold and Critical Threshold values, or you can modify existing values. In the Response Actions field, you can enter an operating system command or a script that you want executed when an alert is issued because a threshold has been crossed.
For example, to modify the warning threshold for Tablespace Space Used (%) metric, you can enter 87 as the percentage. Under Response Actions, you can optionally specify a fully qualified path to an operating system script that will cleanup or increase the size of the tablespace.
Oracle provides a host of alerts that are not enabled by default. You can enable them by specifying threshold values. For example, to enable the alert for Cumulative Logons (for each second), enter 10 for warning and 25 for critical. This will cause the system to warn you when the number of logons for each second exceeds 10.
You must click OK to save your changes.
For more comprehensive management of threshold settings for the different alerts, click the radio button in the Select column for that metric, then click Manage Metric Indexes.
The Manage Metric Indexes:metric_name page is displayed that enables you to add or delete specific metric threshold and response action settings.
For example, to set the Tablespace Space Used (%) metric thresholds for individual tablespaces, select this metric then click Manage Metric Indexes. Enter the tablespace name and its warning and critical values. Click OK.
You can optionally direct Enterprise Manager to provide notification when events that require your intervention arise. For example, if you specify that you want email notification for critical alerts, and you have a critical threshold set for the system response time for each call metric, then you could be sent an email containing a message similar to the following:
Host Name=mydb.us.mycompany.com Metric=Response Time per Call Timestamp=08-NOV-2003 10:10:01 (GMT -7:00) Severity=Critical Message=Response time per call has exceeded the threshold. See the lattest ADDM analysis. Rule Name= Rule Owner=SYSMAN
The host name is a link to the Database Home page and in the message there is a link to the latest ADDM analysis.
By default, alerts in critical state such as DB Down, Generic Alert Log Error Status, and Tablespace Used are set up for notification. However, to receive these notifications, you must set up your email information.You can do so as follows:
From any Database Control page, click the Setup link, which is visible in the header and footer area.
On the Setup page, select Notification Methods.
Enter the required information into the Mail Server portion of the Notifications Methods page. See the online help for assistance.
There are other methods of notification, including scripts and SNMP (Simplified Network Management Protocol) traps. The latter can be used to communicate with third-party applications.
|
Note: So far, this procedure has set up a method of notification, but has not set up an email address to receive the notification. You must also complete the following steps. |
From any Database Control page, click the Preferences link, which is visible in the header and footer area.
On the Preferences page, select General. Enter your email address in the E-mail Addresses section.
You can optionally edit notification rules, such as to change the severity state for receiving notification. To do so, select Notification Rules. The Notification Rules page appears. For more information about configuring notification rules, see Oracle Enterprise Manager Advanced Configuration.
When you receive an alert, follow any recommendations it provides, or consider running ADDM or another advisor, as appropriate to get more detailed diagnostics of system or object behavior.
For example, if you receive a Tablespace Space Usage alert, you might take a corrective measure by running the Segment Advisor on the tablespace to identify possible objects for shrinking. You can then shrink the objects to free space. See "Reclaiming Wasted Space" in Chapter 6, "Managing Database Storage Structures".
Additionally, as a response, you can set a corrective script to run as described in "Setting Metric Thresholds".
Most alerts such as an Out of Space are cleared automatically when the cause of the problem disappears. However, other alerts such as Generic Alert Log Error are sent to you for notification and need to be acknowledge by you, the system administrator.
After taking the necessary corrective measures, you can acknowledge an alert by clearing or purging it. Clearing an alert sends the alert to the Alert History, which is viewable from the home page under Related Links. Purging an Alert removes it from the Alert History.
To clear an alert such as Generic Alert Log Error, from the Home page under Alerts, click the alert link.The Alert Log Errors page appears. Select the alert to clear and click Clear. To purge an alert, select it and click Purge. You can also Clear Every Open Alert or Purge Every Alert using these buttons.
At times database performance problems arise that require your diagnosis and correction. Sometimes problems are brought to your attention by users who complain about slow performance. Other times you might notice performance spikes in the Host CPU chart on the home page.
In all cases, these problems are flagged by the Automatic Database Diagnostics Monitor (ADDM), which does a top-down system analysis every hour by default and reports its findings on the Oracle Enterprise Manager Home page.
ADDM runs automatically every hour to coincide with the snapshots taken by AWR. Its output consists of a description of each problem it has identified, and a recommended action.
Findings are displayed in two places on the home page:
Under the Performance Analysis section on the Database Home page, as shown in Figure 10-4.
You can drill down by clicking the finding. The Findings Details page appears describing the findings and recommended actions.
Below the Diagnostic Summary heading next to Performance Findings shows the number of findings if any. Clicking this link takes you to the ADDM page.
To respond to a performance finding, click the finding and follow the recommended actions, if any. A recommendation can include running an advisor.
For example, Figure 10-4 shows a performance finding of SQL statements consuming significant database time were found, with an impact of 76.53% and recommended summary of SQL Tuning.
Clicking this link takes you to the Performance Finding Details page. Here the recommended action is to run the SQL Advisor, which you can do by clicking Run Advisor Now. The advisor runs and gives a recommendation in the form of precise actions for tuning the SQL statements for better performance.
ADDM behavior and analysis is based on the Automatic Workload Repository (AWR), which collects system performance statistics and stores the data in the database. After default installation, the AWR captures data every hour and purges data over seven days old. You can modify both the snapshot frequency and the data retention period as desired.
You can view and alter these settings on the Workload Repository page:
The retention period for snapshots. This is initially set to 7 days.
The interval for snapshots. The default and recommended value is 30 minutes.
To navigate to this page, from the Database Administration page, under Workload, select Automatic Workload Repository.
To change either of these settings, click Edit on the Workload Repository page. The Edit Settings page appears. Enter a new Snapshot retention period or new System Snapshot Interval. Click OK.
By default Oracle runs ADDM every hour. Performance findings from the last snapshot are listed on the Oracle Enterprise Manager Home page. This is described in "Performance Self-Diagnostics: Automatic Database Diagnostics Monitor ".
You can also invoke ADDM manually. Reasons for doing so include running it as a recommended action associated with an alert, running it in the middle of a snapshot period, or running it across multiple snapshots.
|
Note: If you need more frequent ADDM reporting, you can also modify the default snapshot interval. To do so, see "Modifying Default ADDM Behavior ". |
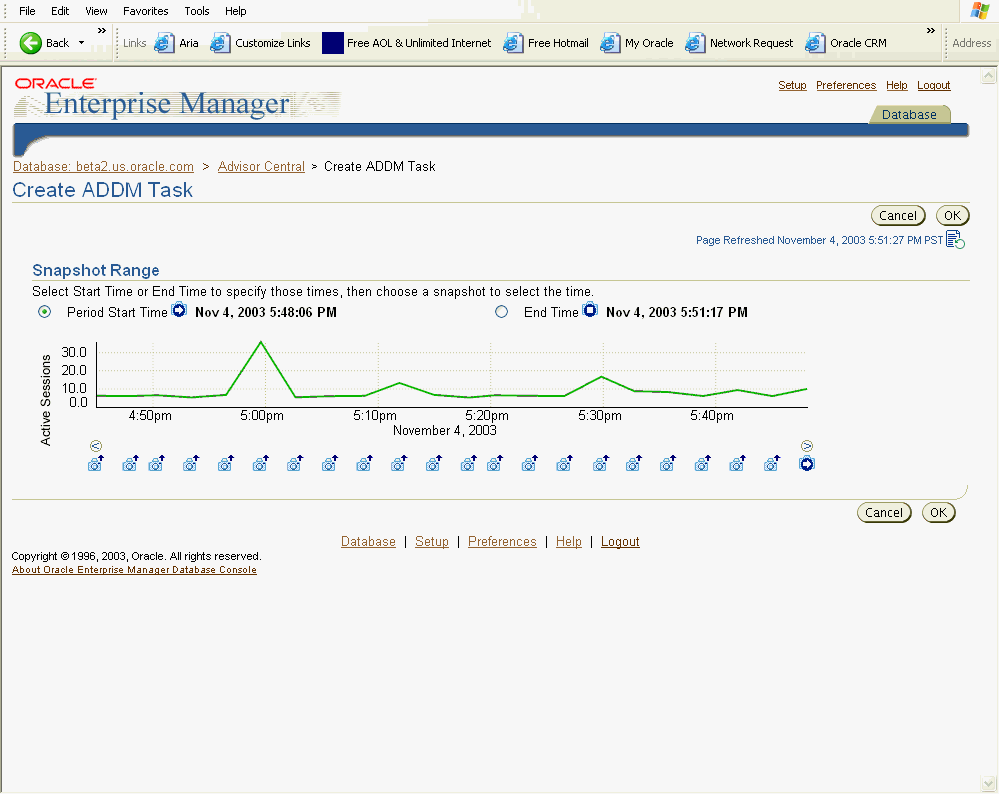
From the Home page, under Related links you can navigate to the ADDM page by clicking Advisor Central, then ADDM. The Create ADDM Task page appears.
Figure 10-5 is a screen shot of Create ADDM Task page.
Increased session activity shows up as peaks in the graph. To analyze a period across multiple snapshots, select a start time and click OK, then choose and end time and click OK. The ADDM Task page appears detailing any findings.
Advisors are powerful tools for database management. They provide specific advice on how to address key database management challenges, covering a wide range of areas including space, performance, and undo management. In general, advisors produce more comprehensive recommendations than alerts. This is because alert generation is intended to be low cost and have minimal impact on performance, whereas advisors are user-invoked, consume more resources and perform more detailed analysis. This along with the what-if capability of some advisors provides vital information for tuning that cannot be procured from any other source.
This chapter deals primarily with the advisors that can improve performance. These advisors include the SQL Tuning, SQL Access, and Memory Advisors. Table 10-1, "Performance Advisors" describes these advisors.
Other advisors such as the Undo and Segment Advisors are listed in Table 10-2, "Other Advisors".
For example, the shared pool memory advisor graphically displays the impact on performance of changing the size of this component of the SGA.
Examples of situations in which an advisor might be invoked include:
You want to resolve a problem in a specific area, for example, why a given SQL statement is consuming 50% of CPU time and what to do to reduce its resource consumption.You would use the SQL Tuning Advisor here.
During application development, you want to tune new schema and its associated SQL workload for optimal performance. You would use the SQL Access Advisor here.
You want to tune memory usage to find the optimum size for your memory structures such as the shared pool or buffer cache. You can use the memory advisors or ADDM here.
Table 10-1 describes the performance advisors that Oracle provides. These advisors are described in this chapter.
Table 10-1 Performance Advisors
| Advisor | Description |
|---|---|
| Automatic Database Diagnostic Monitor (ADDM) | ADDM makes it possible for the Oracle Database to diagnose its own performance and determine how any identified problems can be resolved.See "Performance Self-Diagnostics: Automatic Database Diagnostics Monitor " and "Diagnosing Performance Problems". |
| SQL Tuning Advisor | This advisor analyzes SQL statements and makes recommendations for improving performance. See "Using the SQL Tuning Advisor". |
| SQL Access Advisor | Use this advisor to tune schema to a given SQL workload. For example, the access advisor can provide recommendations for creating indexes and materialized views for a given workload. See "Using the SQL Access Advisor". |
Memory Advisor
|
The Memory Advisor is the main advisor for system memory and is responsible for optimizing memory on the instance as a whole. You have the option of having Oracle auto-tune memory. If you choose not to have Oracle auto-tune memory, then you can invoke the SGA Advisors or the PGA Advisor to obtain optimal settings for the components and total size of the SGA or PGA. See "Using the Memory Advisor". |
Table 10-2, "Other Advisors" describes other advisors Oracle provides. These are described elsewhere in this book.
Table 10-2 Other Advisors
| Advisor | Description |
|---|---|
| Segment Advisor | The Segment Advisor provides advice on whether an object is a good candidate for a shrink operation based on the level of space fragmentation within an object. The advisor also reports on the historical growth trend of segments. You can use this information for capacity planning and for arriving at an informed decision about which segments to shrink. See "Reclaiming Wasted Space" in Chapter 6, " Managing Database Storage Structures". |
| Undo Advisor | The Undo Advisor helps in identifying problems in the undo tablespace and assists in correctly sizing the undo tablespace. The Undo Advisor can also be used to set the low threshold value of the undo retention period for any flashback requirements. See "Using the Undo Advisor" in Chapter 6, "Managing Database Storage Structures". |
You can invoke an advisor from the Advisor Central home page that is displayed when you click Advisor Central under the Related Links heading on the Database Home page, or on other pages where it is listed. You can invoke advisors in other ways, often through recommendations from ADDM or alerts.
Use the SQL Tuning Advisor for tuning SQL statements. Typically, you can run this advisor in response to an ADDM performance finding recommending its use.
Additionally, you can run the SQL Tuning Advisor on the most resource intensive SQL statements, referred to as top SQL, from the cursor cache or the AWR, as well as on a user-defined SQL workload.
To run the SQL Tuning Advisor do the following:
On the Home Page, under Related Links, click Advisor Central, then click SQL Tuning Advisor. The SQL Tuning Advisor Links page appears.
The advisor can be run on one of the following sources
Top SQL---The consist of recently active top SQL statements from the cursor cache (Spot SQL) or historical top SQL from the AWR (Period SQL).
SQL Tuning Sets---These consist of SQL statements you provide. An STS can be created from SQL statements captured by AWR snapshots or from any SQL workload.
For example, you can select Top SQL. The Top SQL page appears. This page has two tabs, Spot SQL and Period SQL. Spot lists recent top SQL from the cursor cache, while Period SQL lists historical top SQL captured in the AWR. You must select an interval to analyze by dragging the shaded box over the period. You then select one or more SQL statements to analyze during the selected period.
Click Run SQL Tuning Advisor. The SQL Tuning Options page appears showing the SQL statements in the interval. Give your task a name and description, select the scope for the analysis (Comprehensive or Limited), and select a start time for the task. Click OK.
Navigate back to the Advisor Central page. The status of Advisor Tasks are listed under this heading in the results section. You must wait until your task status is COMPLETED. You can check the status by clicking your browser's Refresh button. Then, select your task and click View Result.
The SQL Tuning Result page appears. To view recommendations, select the SQL statement and click View Recommendations. The recommendation can include one or more of the following:
Create an index to offer alternate, faster access paths to the query optimizer.
Accept SQL profile, which contains additional SQL statistics specific to the statement that enables the query optimizer to generate a significantly better execution plan.
Gather optimizer statistics on objects with stale or no statistics
Advice on how to rewrite a query for better performance.
The SQL Access Advisor helps define appropriate access structures such as indexes and materialized views to optimize SQL queries. It takes a SQL workload as an input and recommends which indexes, materialized views, or logs to create, drop, or retain for faster performance. You can select your workload from different sources including current and recent SQL activity, a SQL repository, or a user-defined workload such as from a development environment.
The recommendations that this advisor makes include possible indexes, materialized views, or materialized view logs that can improve your query performance for the given workload.
To run this advisor, navigate to the Advisor Central page, and click SQL Access Advisor. This begins a wizard which starts by prompting you for your workload source. You then select if you want the advisor to recommend indexes, materialized views or both. You can select to run the advisor in limited or comprehensive mode. Limited mode runs faster by concentrating on highest cost statements.
You then schedule and submit your job. Results are posted on the Advisor Central page. The SQL Access Advisor recommendations are ordered by cost benefit. For example, a recommendation might consist of a a SQL script with one or more CREATE INDEX statements, which you can implement by clicking Schedule Implementation.
The Memory Advisor helps you tune the size of your memory structures. You can use this advisor only when automatic memory tuning is disabled.
The memory advisor comprises three advisors that give you recommendations on the following memory structures:
Shared pool in SGA
Buffer cache in SGA
PGA
To invoke the Memory Advisors, click Memory Advisor on the Advisor Central page. The Memory Parameters: SGA page appears. This page gives breakdown of memory usage for the system global area (SGA). This memory area is a group of shared memory structures that contain data and control information for a single Oracle instance. The shared pool and buffer cache are part of this area. For more information on these structures, click Help.
The Automatic Shared Memory Management setting should be disabled in order to run the advisor. To run either the shared pool advisor or the buffer cache advisor, click Advice next to the field.
For example, to run the advisor on the shared pool, click Advice next to this field. The Shared Pool Advice graph appears. Refer to Figure 10-6, "Shared Pool Size Advice".
Change in parse time saving is plotted against shared pool size. A higher number for parse time saving is better for performance. In this example, the graph tells us that a shared pool size larger than 80M will not improve performance by much. Thus 80M is the recommended optimal shared pool size.
Similarly, to run the advisor on the buffer cache, click Advice next to this field. The Buffer Cache Size Advice graph appears, plotting relative change in physical reads versus cache size. Since a bigger cache implies less disk reads, the smaller number for change in physical reads is better for performance. Like the shared pool memory, there is usually an optimal cache size above which performance improvement is negligible.
To run the PGA advisor, click the PGA property page. Running this advisor is similar to running the SGA advisors. Cache hit percentage is plotted against memory size. Higher hit ratios indicate better cache performance. The optimal zone for cache hit percentage is between 75 and 100%.
Oracle by Example (OBE) has a series on the Oracle Database 2 Day DBA book. This OBE steps you through the tasks in this chapter, and includes annotated screen shots.
To view the Monitoring OBE, point your browser to the following location:
http://otn.oracle.com/obe/2day_dba/monitoring/monitoring.htm