

|
|
This article presents a brief description of the nature and perception of sound, how to deal with sound as an object in a computer and the available software for streaming audio.
by Siome Goldenstein
With the recent popularization of multimedia and the ever decreasing cost of hardware, the use of sound by developers in new applications is becoming more appealing each day. Sound can flavor a game, help in the user interface of a word processor, and more, making using a computer more fun and/or more effective.
There are two different forms of sound generation in the common sound boards. The first one is used primarily for music, through a MIDI interface and FM generators. The idea is to synthesize, artificially or by some previous recording samples, the occurrence of different instruments at different times. The second approach is to use digital audio signals, which can represent any sound, from a bird chirp to a human voice--even musical signals.
The human auditory system perceives differences in the pressure of the air that reaches it. When we pluck a guitar string, for example, it starts to vibrate. This movement propagates through the air in waves of compression and decompression, just as we can see waves over a lake's surface when we throw a small rock into it.
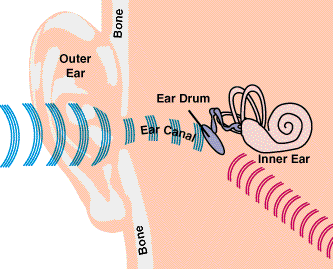
Figure 1 shows a detailed representation of the human auditory system, which processes and decomposes the incoming sound before sending the information to the brain. There is a lot of literature about processing human speech (see References 1 and 2), however, I'll give just a little of the basics rather than going into too much detail about the bio-medical considerations.
We ``understand'' fast oscillations of the air as sharp sounds and slow oscillations as bass sounds. When different oscillations are mixed together, we may lose this ``musical'' connotation. It is hard to classify the sound of a gun or the crash of a glass. Nevertheless, there are some mathematical tools able to decompose an arbitrary sound into a set of simple oscillations (e.g., Fourier Analysis), but these tools are quite beyond the scope of this article (see Reference 3).
A simple mathematical method for the representation of a sound phenomenon is the use of a function that describes it. This function is responsible for relating the intensity of the air pressure over a period of time. This approach is commonly called temporal representation and is also obtained when using electronic transducers (like microphones), which map electric voltages instead of air pressures over time. At the end of electronic processing, such as recording or amplifying, another transducer (a speaker, for example) is responsible for obtaining the air pressures from the electric intensities so that we can hear them.
For analog electronics this model is good enough; however, for the use of modern digital computers or DSPs (special devices for signal processing), there is one problem--how to keep and process the infinite information, contained in even a small interval of a function, in a limited amount of memory.
We have to work with digital audio, obtained from the continuous mathematic functional model, through two steps: sampling and quantization. The sampling step represents the domain of the function with only a limited number of points. This is usually done through uniform punctual sampling; in other words, we keep the value of the function only at some points, equally spaced from each other. It is clear that some loss of information may occur if by any chance the function varies too much between two adjacent samples (see Figure 2).
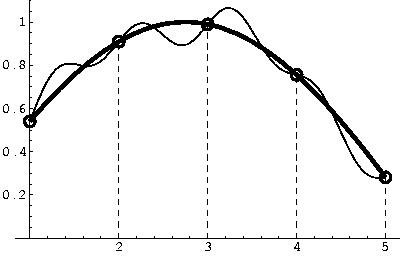
The number of samples taken at each second, the sampling rate, should be chosen with care. The Shannon Theorem states that if the sampling is done twice as fast as the ``fastest oscillation'' of the signal then it is possible to recover the original sound; this is called the Nyquist frequency sampling rate.
It is important to have a good idea of the type of signal that you are processing, in order to choose an appropriate sampling rate. Large sampling rates give better quality, but also require more memory and computer power to process and store.
The quantization step sets the value of the function at each discrete sample. A simple approach would be to use a float, thus requiring four bytes per sample. In general this is far beyond the required quality, and people use either one byte (unsigned character) or two byte samples (signed word).
Let's compare two concrete examples to see how these choices can dramatically change the required amount of memory to keep and process the sounds. On a compact disk the audio is stereo (two different tracks, left and right), at 44,100 samples per second, using two bytes to keep each sample. One minute of it will require: 2 X (60 X 44,100) X 2 = 10.5MB of storage.
In the case of voice mail or a telephone-based system where the controlling computer requires playback to the user, these numbers are quite different. There is no need for so many samples, since the phone lines have a serious quality limitation, usually these systems take 8000 samples per second, use only one channel (mono) and keep only one byte per sample. In the same way, for one minute we will need: 1 X (60 X 8000) X 1, about 480KB of information.
Since it is important to have your sound device fully functional, many configuration details should be checked, such as the sound support in the kernel (you can compile as a kernel module). Check the SOUND-HOWTO by Jeff Tranter (Jeff_Tranter@mitel.com) at http://confused.ume.maine.edu/mdw/HOWTO/Sound-HOWTO.html--it's a good reference.
Once we have the digital audio signal in hand it is important to encode it. There are many types of sound files (au, wav, aiff, mpeg), each with its pros and cons. Some of them simply stack the samples in a vector, byte after byte, while others try to compress the signal through transformations and sometimes heavy computations.
Fortunately, on sunsite (http://sunsite.unc.edu/) you can find AFsp, from Peter Kabal (kabal@tsp.ee.mcgill.ca), a library that reads and writes these files for you. I have not used it, since by the time I found it, I had already written some code to do the same operations. AFsp is very well documented.
There are many good sources of information around the Web on how to program the input and output of sound in Linux. The first you should check out is the Programmer's Guide to OSS at http://www.4front-tech.com/pguide/index.html. It contains all the information you need for the control and manipulation of different aspects of your audio hardware, like MIDI, mixing capabilities and, of course, digital audio.
In Linux the sound hardware is generally controlled through a device (normally /dev/audio). You have to activate it, with a call to open and set some parameters (sample rate, quantization method and mono or stereo) using ioctl (I/O control). These basic steps for playing or recording are well illustrated in the ``Basic Audio'' section of the guide mentioned above.
Playing is accomplished by a write operation of the vector of samples on the device, while the recording is done through a read. There are some subtle details that are being skipped, like the order in which these operations are to be done, for the sake of simplicity.
If you are planning to create applications that require real-time interaction (for example, a game engine) and have to continuously stream an audio sequence, there are some important measures to take to ensure that the audio buffer is neither overflowed nor underflowed.
The first case, overflows, can be solved by knowing a bit more about the OSS implementation (check the ``Making Audio Complicated'' page of the OSS Programmer's Guide). The buffer is partitioned in a number of equal pieces, and you can fill one of them while the others are in line for playing. Some ioctl calls will give you information about the total available space in the buffer, so that you can avoid blocking. You can also use IPC (Inter-Process Communication) techniques and create a different process responsible only for buffer manipulation.
When you send the audio to the output at a slower rate than the device plays, the buffer gets empty before you send more data causing an underflow. The resulting effect is disturbing and sometimes difficult to diagnose as an underflow problem. One possible solution is to output the audio at a slower rate, thus giving the computer more time to process the data.
Looking at how other people write their programs helps to understand the inner difficulties of the implementation problems. So, I looked around the Net to see what was available and was quite impressed by both the quantity and the quality of the software I found.
A good, simple example of a ``sound-effect server'' is sfxserver by Terry Evans (tevans@cs.utah.edu), available on sunsite. It takes control of the audio device and receives commands (currently only from stdin) like ``load a new effect'', starts playing the loaded effect, etc. In the same place you can also find sfxclient, an example of a program client.
Generic network audio systems have taken the approach of keeping the high-level, application development far away from the hardware and device manipulation. The Network Audio System (nas) is one implementation of this paradigm, having the same idea and framework of the X Windows system. It runs on many architectures such as Sun, SGI, HPUX and Linux. Through it you can write applications that take advantage of sound across the network, without worry about where you are actually working--the network layer takes care of everything for you. nas comes with documentation and many client examples. You can download it from sunsite along with a pre-compiled rpm package. Some games like XBoing and xpilot already support it.
Another network transportation implementation is netaudio (http://www.bitgate.com/netaudio/). It is not intended to work as an intermediate layer between applications and devices like nas and is only responsible for real-time transmission of data along the Net, allowing some interesting properties like rebroadcasting. The great advantage I saw was its compactness: the gzipped, tar file is around 6 KB. The basic idea is to use another program in a pipe-like structure to enable playing after reception (or recording for transmission). The README file gives examples of how to compress the audio with other programs to reduce the required amount of bandwidth thus becoming a free, real-time audio alternative for the Web.
A similar package, using LPC compressing methods (designed for voice only) is Speak Freely for Unix from John Walker (http://www.fourmilab.ch/).
Another interesting example of an audio streaming application is mpeg audio playing. The compression achieved by this method is incredible, making high-quality audio on demand possible through the Internet. Unfortunately a fast machine is required for real-time playing.
Again, looking at your sunsite mirror, you will find some implementations. One that is fast, interesting and attention-getting is mpg123 from Michael Hipp (Michael.Hipp@student.uni-tuebingen.de) and Oliver Fromme (oliver.fromme@heim3.tu-clausthal.de). The official web page is located at http://www.sfs.nphil.uni-tuebingen.de/~hipp/mpg123.html.
It is very important to have the basic, digital-audio concepts clear in mind during the implementation process of an application, otherwise there is the risk of a misconception or tiny mistakes that are difficult to locate.
The great number of programs available around the net show that this kind of resource is appealing, and they also provide you with a base at which to begin programming, so you do not have to start from scratch.
I have purposely left the implementation details out of this article, since it would be impossible to keep it both concise and accurate, as well as helpful. Again, I suggest to those interested in the inner details to go to the links mentioned and download some of the existing applications to learn how they were coded.
Siome Klein Goldenstein is an Electronic Engineer and has a MS in Computer Science (Graphics). By the time of printing he will be starting a PhD in Computer Science at University of Pennsylvania.

