

|
|
 Los Alamos National Laboratory and Caltech obtain gigaflops
performance on parallel Linux machines running free software and built
from commodity parts costing less than $55,000 each (in September
1996). Now, you can probably build a similar machine for about
$25,000.
Los Alamos National Laboratory and Caltech obtain gigaflops
performance on parallel Linux machines running free software and built
from commodity parts costing less than $55,000 each (in September
1996). Now, you can probably build a similar machine for about
$25,000.
by Jim Hill, Michael Warren and Patrick Goda
As much as we might like to own a supercomputer, high cost is still a deterrent. In a market with almost no economy of scale, buyers find themselves relying on the vendors for specialty hardware, specialty software and expensive support contracts while hoping that the vendors don't join the long list of bankrupt former supercomputer vendors. The limited number of sale opportunities force vendors to try satisfying all customers, with the usual result that no one is really happy. There is simply no way to provide highly specialized software (such as a parallelizing compiler) and simultaneously keep costs out of the stratosphere.
On the other end of the market, however, sits the generic buyer. More correctly, tens of millions of generic buyers, all spending vast sums for fundamentally simple machines with fundamentally simple parts. What the vendors lose in profit margin, they make up for in volume. The result? Commodity computer components are increasingly faster, cheaper and smaller. It is now possible to take these off-the-shelf parts and assemble machines which run neck-and-neck with the ``big boys'' of supercomputing, and in some instances, surpass them.
Intel's x86 series of processors, especially the Pentium and Pentium Pro, offer excellent floating-point performance at ever-increasing clock speeds. The recently released Pentium II has a peak clock speed of 300 MHz, while Digital's best Alpha processors compute merrily along at 500 MHz and higher.
The PCI bus allows the processors to communicate with peripherals at rates in excess of 100MB/sec. Because it is a processor-independent bus, undertaking processor upgrades (e.g., from the Pentium Pros to 500MHz DEC Alphas) requires replacing only the processors and motherboards. Further, parts replaced by an upgrade can be expected to have a significant resale value.
The development of Fast Ethernet technology makes possible point-to-point communication in excess of 10MB/sec. Switches which allow multiple machines to use this bandwidth in full are readily available, which gives the Beowulf-class (see below) machine a bandwidth and latency which rivals the larger IBM SP-2 and the Thinking Machines CM-5. While the Beowulf machines don't yet scale easily to hundreds of processors, their performance in smaller networks of 16 or 32 processors is outstanding.
The Linux operating system is robust, largely POSIX-compliant and available to varying degrees of completeness for Intel x86, DEC Alpha and PowerPC microprocessors. Thanks to the untiring efforts of its legions of hackers, auxiliary hardware (network and disk drivers) is supported almost as soon it becomes available and the occasional bug is corrected when found, often the same day. GNU's compilers and debuggers coupled with free message-passing implementations make it possible to use Linux boxes for parallel programming and execution without spending money on software.
The Beowulf Project studies the advantages of using interconnected PCs built from mass-market components and running free software. Rather than raw computational power, the quantities of interest derive from the use of these mass-market components: performance/price, performance/processor and so on. They provide an informal ``nonstandard'' by loosely defining a ``Beowulf-class'' machine. Minimal requirements are:
Figure 1. View of Loki from the Front
Figure 2. View of Loki from the Back
Loki is a 16-node parallel machine with 2GB RAM and 50GB disk space. Most of the components were obtained from Atipa International (www.atipa.com). Each node is essentially a Pentium Pro computer optimized for number crunching and communication:
The list purchase price of Loki's parts in September 1996 was just over $51,000.
The nodes are connected to one another through the four-port Quartet adapters into a fourth-degree hypercube. Each node is also connected via the SMC adapter to one of two eight-port 3Com SuperStack II Switch 3000 TX 8-port Fast Ethernet switches, which serve the dual purpose of bypassing multi-hop routes and providing a direct connection to the system's front end, a dream machine with the following components:
It is also possible for the nodes to communicate exclusively through their SMC-SuperStack connections as a fast, switched array topology. At Supercomputing '96, Loki was connected to Caltech's Hyglac and the two were run as a single fast switched machine.
Like Loki, Hyglac is a 16-node Pentium Pro computer with 2GB RAM. At the time of its construction, it had 40GB disk space, though that has since been doubled by adding a second hard drive of the type listed below to each node.
Each node is connected to a 16-way Bay Networks 28115 Fast Ethernet Switch in a fast switched topology. Video output is directed to a single monitor through switches; the node which is directly connected to the monitor also supports a second Ethernet card and a floppy drive. The list purchase price of Hyglac in September 1996 was just over $48,500. Most of the components have since decreased in price by about 50%, and the highest single-cost item (a 16-port Fast Ethernet Switch) can now be obtained for less than $2500!
Both Loki and Hyglac run Red Hat Linux on all nodes, with GNU's gcc 2.7.2 as the compiler.
The 200MHz Pentium Pros that drive both systems supply a real-time clock with a 5 nanosecond tick, providing precise timing for message passing. More advanced timing and counting routines are available as well, so that profiling data like cache hits and misses are directly supported. A relatively simple interface to the hardware performance monitoring counters on the CPU has been developed at LANL called perfmon, which is available at the Loki URL listed in the Resources.
Figure 3. Parallel Linux Cluster Logo
Internode communication is accomplished via the Message Passing Interface (MPI). While multiple implementations of MPI are freely available, none was specifically written to take advantage of a Fast Ethernet-based system and, as usual, maximum portability leads to a decidedly less than maximum efficiency. Accordingly, a minimal implementation was written from scratch which incorporated the 20 or so most common and basic MPI functions. This specialized MPI library runs the treecode discussed in the next section as well as the NAS parallel benchmarks for Version 2 MPI, while nearly doubling the message bandwidth obtained from the LAM (Ohio State's version of MPI) and MPICH (from Argonne National Laboratory and Mississippi State University) implementations.
Because of its use in astrophysics, Loki has been used to compute results for an N-body, gravitational-interaction problem using a parallelized hashed oct-tree library. (oct-tree is a three-dimensional tree data structure, where each cubical cell is recursively divided into eight daughter cells. treecode is a numerical algorithm which uses tree data structures to increase the efficiency of N-body simulations. For details on the treecode, see the URL listed in Resources.) The code is not machine-specific, so comparing the performance of the commodity machines to traditional supercomputers is free of porting issues (with the exception that the Intel i860 and the Thinking Machines CM-5 have an inner loop coded in assembly).
At Supercomputing '96, Loki and Hyglac were connected via $3,000 of additional Ethernet cards and cables) to perform as a single 32-node machine with a purchase cost of just over $100,000. Running the N-body benchmark calculation with 10 million particles, Loki+Hyglac achieved 2.19 billion floating-point operations per second (GFLOPS), more than doubling the per-processor performance of a Cray T3D and almost matching that of an IBM SP-2 (see Table 1).
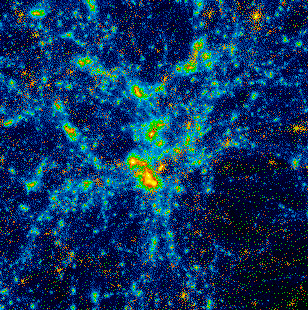
Figure 4. Intermediate stage of a gravitation N-body simulation of galaxy formation using 9.75 million particles. It took about three days to compute on Loki at a sustained rate of about 1GFLOP.
As a stand-alone machine at LANL, Loki has performed an N-body calculation with just over 9.75 million particles. This calculation was ``real work'' and not ``proof-of-principle'', so it was tuned to optimize scientific results rather than machine performance. Even with that condition, the performance and results are striking. The total simulation required 10 days (less a few hours) to step through 750 time steps, performed 6.6x1014 floating-point operations to compute 1.97x1013 particle interactions and produced just over 10GB of output data.
For the entire simulation, Loki achieved an average of 879MFLOPS, yielding a price/performance figure of $58/MFLOP. Contemporary machines such as SGI's Origin are capable of price/performance in this range, but scaling an Origin to the memory and disk necessary to perform a calculation of this magnitude quickly becomes prohibitive; at list price, 2GB of Origin's memory alone costs more than the entire Loki assembly.
The nature of the treecode is such that later time steps have greater overhead in spanning the tree than in performing floating-point arithmetic, so the average flop rate steadily decreases the longer the code is run. When the first 30 time steps of the simulation are taken into consideration, 1.15x1012 particle interactions in 10.25 hours provide a throughput of 1.19 GFLOPS. This figure actually is a better estimate of the amount of useful work than that given for the total simulation, since the treecode's purpose is to avoid floating-point calculations whenever possible.
Loki has also been used to simulate the fusion of two vortex rings. The simulation began with 57,000 vortex particles in two discrete smoke rings, though re-meshing caused the simulation to be tracking 360,000 particles by the final time step. Each processor sustained just over 65 MFLOPS during the simulation for a total system performance of 950 MFLOPS.
Hyglac has been used to perform photo-realistic rendering using a Monte Carlo implementation of the rendering equation. Images of some of the rendered images are available at http://www.cacr.caltech.edu/research/beowulf/rendering.html. In a direct comparison with an IBM SP-2, Hyglac completed the renderings anywhere from 12% to 20% faster than an IBM SP-2, a machine with a price tag twenty times that of Hyglac.
Even the most blazingly fast system is useless if it can't perform without crashing. System reliability is therefore crucial, especially in the case of a machine like Loki which may need several days without interruption to complete a large-scale calculation. During the burn-in period, a bad SIMM and a handful of bad hard drives were replaced under their warranty terms. The warranties on commodity parts make these commodity supercomputers particularly appealing. Warranties on specialty machines like the Origin tend to be 90 days or less, whereas readily available parts such as Loki's innards generally have warranties ranging from a year to life. In September 1997, most of the Loki nodes had uptimes of over 4 months without a reboot. The only hardware problems encountered have been three ATX power supply fans which failed, resulting in node shutdowns due to overheating. Those nodes were easily swapped with a spare, and the fans replaced in a few minutes.
In Table 2, we summarize the price/performance of several machines capable of running the NAS (Numerical Aerospace Simulation Facility at NASA Ames Research Center) Class B benchmarks: Loki, the SGI Origin 2000, the IBM SP-2 P2SC and the DEC AlphaServer 8400/440.
A gravitational N-body simulation won LANL's Michael Warren and Caltech's John Salmon a Gordon Bell Performance Prize in 1992. A scant five years later, that same calculation can be run on a $50,000 machine. Technology continues to advance (Warren and Salmon recently achieved 170 sustained GFLOPS while running the N-body code with over 320 million particles on half of the nearly 10,000 processors of the Teraflops ``ASCI Red'' machine at Sandia National Laboratory), but the cost of the ever-improving ``high-end'' supercomputers keeps them beyond the reach of all but a lucky few. Even those lucky few must compete with one another for processor time in the never-ending game of large-scale computation. Commodity parts provide an opportunity for a handful of users to have a significant share of processor cycles on a machine which is capable of solving enormous computational problems in a reasonable time. Linux and the free software movement provide the software to take full advantage of the hardware's capabilities.
Jim Hill (jlhill@lanl.gov) is a graduate research assistant at Los Alamos National Laboratory who's thinking about renaming one of his two Linux boxes a zeroth-degree hypercube.

Michael S. Warren (mswarren@lanl.gov) received a B.S. in Physics and in Engineering and Applied Science from the California Institute of Technology in 1988 and a Ph.D. in Physics from the University of California, Santa Barbara in 1994. He is currently developing treecode algorithms for problems in cosmology and hydrodynamics as a technical staff member in the Theoretical Astrophysics group at Los Alamos National Laboratory. He has been involved with parallel computing since 1986 and with Linux since 1993.

Patrick Goda (pgoda@lanl.gov) is currently employed at Los Alamos National Lab in the Theoretical Astrophysics group. When he's not building clusters or hacking Linux software, he actually uses Linux to do real research in Meteoritics (like smashing simulated asteroids into a simulated Earth and seeing how grim the situation would be).


{kind=link}
{kind=link}
{kind=link}
{kind=link}