Release 2.4
A63820-01
Library |
Product |
Contents |
Index |
| Oracle8
ConText Cartridge Administrator's Guide
Release 2.4 A63820-01 |
|
![]()
![]()
This chapter introduces the concepts necessary for understanding
the indexing objects in the ConText data dictionary.
The following topics are discussed in this chapter:
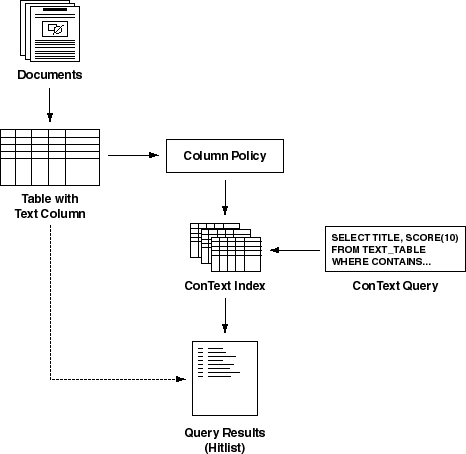
ConText indexes enable text and theme queries to be performed
against text columns. Figure 8-1 illustrates
the basic relationships between text tables, policies, ConText indexes,
and ConText queries.
In a typical ConText system, text is loaded into a text column
in a table, then a policy is created for the column.
The policy is used to create the ConText index, which resides
in separate database tables associated with the text column through the
policy. Once an index exists for a column, queries can be performed against
the column using any of the query methods supported by ConText.
When an query is issued against a text column that has a
ConText index, rather than scan the actual text to find documents that
satisfy the search criteria of the query, ConText searches the ConText
index tables to determine whether a document should be returned in the
results of the query.
The query results are then returned, in the form of a hitlist,
to the user that submitted the query. The query results can be returned
directly or can be combined with structured data from the base table to
refine the query or provide more information about the document that satisfy
the query.
| See
Also:
For more information about ConText indexes and the objects used to create them, see:
For more information about text loading, see "Text Loading" in Chapter 6, "Text Concepts". For more information about ConText queries, see Oracle8 ConText Cartridge Application Developer's Guide. |
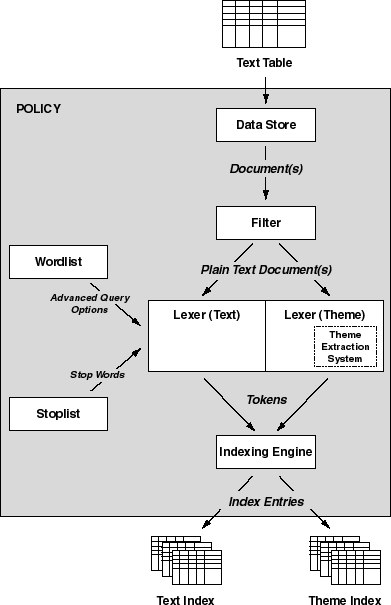
This section provides conceptual, as well as reference, information about policies:
To create a ConText index for text stored in a database column, ConText requires the following information about the text:
|
Note: ConText also provides a facility for specifying whether the text is compressed; however, this facility is not currently implemented. |
A policy provides this information for the column, in the
form of indexing preferences (one preference for each of the requirements).
Policies can be created by any ConText user with the CTXAPP role and are
stored in the ConText data dictionary.
|
Note: A policy must exist for a column before a ConText server can create a index for the column. |
In addition to the preferences for a policy, users specify
a name for the policy and the text column for the policy, and a number
of other policy attributes.
The policies created by a user must be unique for the user.
As such, the same policy for a user cannot be assigned to more than one
column.
A column policy is a policy that has a text column assigned
to it. Only column policies can be used to create ConText indexes.
| See
Also:
For examples of creating policies, see "Creating a Column Policy" in Chapter 9, "Setting Up and Managing Text". |
A template policy is a policy that does not have a text column
assigned to it. Template policies are used as source policies when creating
column policies or other template policies. The source policy for a policy
specifies the preferences (one for each requirement) to be used as defaults
in the policy.
For example, ConText provides a template policy, DEFAULT_POLICY,
that is the default source policy for all column and template policies.
Any of the preferences provided in a template policy can
be overwritten with other preferences (of the same type) by explicitly
naming the preference during creation of the new policy.
ConText provides a number of predefined template policies,
owned by CTXSYS. Users can create their own template policies or use the
predefined template policies when creating policies.
Multiple policies, as long as they are unique for the user,
can be assigned to a column. As a result, a column can have more than one
index. When a query is performed, you can specify a policy name to indicate
the index that is used to process the query.
This feature is particularly useful if you have English-language
documents for which you want to enable both text and theme queries. To
enable text and theme queries, you must create both a text indexing policy
and a theme indexing policy on the column containing the documents and
create a ConText index for each policy.
| See
Also:
For more information about text and theme queries, see "Text/Theme Queries" in Chapter 6, "Text Concepts". For more information about text indexing and theme indexing policies, see "Text Lexers" and "Theme Lexer" in this chapter. For a complete discussion of text and theme queries, see Oracle8 ConText Cartridge Application Developer's Guide. |
Consider a table with two text columns: one holds Microsoft
Word documents and the other holds (plain text) comments for the documents.
The table structure is:
To create a text index for both the comment and doc
columns in doc_and_comment, a policy must be defined for each column.
The following example illustrates two policies named i_doc and i_comments
that could be created:
To create a theme index for the doc column, a theme
indexing policy must be defined. The following example illustrates a policy
named i_theme that could be created for the table:
ConText provides the following template policies (listed in alphabetical order):
This template policy uses all of the default preferences.
It can be used to create a policy with the following characteristics:
|
Note: DEFAULT_POLICY is the default for source_policy in both CTX_DDL.CREATE_POLICY and CTX_DDL.CREATE_TEMPLATE_POLICY. |
This template policy uses the AUTOB
predefined Lexer preference and all the remaining preferences from DEFAULT_POLICY.
It can be used to create a column policy for a text column that contains
documents in any of the formats supported by the ConText internal filters.
This template policy uses the following predefined preferences
and can be used to create a column policy which enables basic section searching
for a text column containing HTML documents:
This template policy uses the same preferences as DEFAULT_POLICY.
It can be used to create a policy for indexing basic text stored in a text
column.
This template policy uses the NO_STOPLIST
predefined Stoplist preference and all the remaining preferences from DEFAULT_POLICY.
It can be used to create a policy that does not use a stoplist during indexing.
This template policy uses the DEFAULT_STOPLIST
predefined Stoplist preference and all the remaining preferences from DEFAULT_POLICY.
It can be used to create a policy that uses the default stoplist (English)
during indexing.
This template policy uses the MD_TEXT
predefined Data Store preference and all the remaining preferences from
DEFAULT_POLICY. It can be used to create a
policy for indexing text stored in the detail column in a master-detail
table.
This template policy uses the MD_BINARY
predefined preference and all the remaining preferences from DEFAULT_POLICY.
It can be used to create a policy for indexing text stored in the detail
column in a master-detail table.
This template policy uses the WW6B
predefined preference and all the remaining preferences from DEFAULT_POLICY.
It can be used to create a policy for indexing text in Microsoft Word for
Windows 6 format.
This section provides conceptual, as well as reference, information for indexing preferences:
Indexing preferences specify the options that ConText uses to create ConText indexes. Each preference represents one (and only one) indexing option and is grouped into one of six categories or types, which correspond to the information ConText requires for creating indexes:
When creating a policy, six preferences are specified, one
for each of the six types. If one of the preference is not specified when
the policy is created, the preference (for that type) from the DEFAULT_POLICY
template policy is used.
A preference can be used in more than one policy; however,
two preferences of the same type cannot be used in the same policy.
Tiles are the objects in the ConText data dictionary that
provide ConText with information about how text is managed in the system,
as well as indexing instructions. Each Tile specifies a distinct indexing
option within the ConText framework.
A Tile is the main component of a preference. Each Tile may
have none, one, or many attributes that are used to define preferences.
The attributes identify which indexing options are active for the preference.
You define one of the types of preferences by setting the
attributes with the desired values for the appropriate Tile, then creating
the preference. While a type is not explicitly assigned to a preference,
it is implied through the association of the Tile with the preference.
ConText provides a number of predefined preferences (owned
by CTXSYS) for each type. These predefined preferences can be used by any
ConText user with the CTXAPP role to create policies without having to
first create preferences.
ConText users with the CTXAPP role can create their own preferences
by setting the required attributes for one of the Tiles provided by ConText,
then calling CTX_DDL.CREATE_PREFERENCE and
specifying the name of the Tile.
ConText provides the following predefined Data Store preferences:
This preference calls the DIRECT
Tile, which is used to indicate that text is stored directly in the text
column of a text table.
This preference calls the OSFILE
Tile, which is used to indicate that text is stored as files in a file
system,
DEFAULT_OSFILE uses the path attribute and a hardcoded
set of dummy directory paths to indicate the directories in which the text
files are located.
The hardcoded paths, delimited by colons are: /oracle/data,
/oracle/data2, /oracle/data3.
|
Note: If the locations of your files do not match the hardcoded paths, do not use the DEFAULT_OSFILE preference in a policy. |
This preference calls the URL
Tile which is used to indicate that text is stored as URLs.
DEFAULT_URL uses all of the attribute defaults for the URL Tile:
This preference calls the MASTER
DETAIL Tile which is used to indicate text is stored in a master detail
table.
MD_BINARY uses the binary attribute and a value of
YES to indicate that the text in the table is stored in binary format (newline
characters do not indicate end of line).
This preference calls the MASTER
DETAIL Tile which is used to indicate text is stored in a master detail
table.
MD_TEXT uses the binary attribute and a value of NO
to indicate that the text in the table is stored in plain text format (newline
characters indicate end of line).
ConText provides the following predefined Filter preferences:
This preference calls the BLASTER
FILTER Tile which specifies an internal filter used to extract text
from formatted documents in a text column.
AUTOB uses the format attribute and a value of 997
to indicate that ConText uses the autorecognize filter to extract text.
It can be used to filter text in a column that contains the following document
formats:
This preference is identical to the HTML_FILTER predefined preference, except the keep_tag attribute is set with the following values to support basic section searching in HTML documents:
This preference calls the FILTER
NOP Tile which indicates that the text column in a text table contains
plain, unformatted (ASCII) text and does not require filtering for indexing
and highlighting.
This preference calls the HTML FILTER
Tile and can be used to filter documents in a column that contains only
HTML-formatted documents.
This preference calls the BLASTER
FILTER Tile and specifies a value of 11 for the format attribute
to indicate ConText uses the Word for Windows 6 filter to extract text.
It can be used in a column that contains only Word for Windows 6-formatted
documents.
ConText provides the following predefined Lexer preferences:
This preference is identical to DEFAULT_LEXER,
except the startjoins and endjoins attributes for the BASIC
LEXER Tile are set with '</' and '>' respectively to support basic section
searching in HTML documents.
This preference calls the BASIC LEXER
Tile, which indicates the lexer settings used to identify word and sentence
boundaries for text indexing and text queries.
DEFAULT_LEXER uses the following Tile attributes and values
to indicate the lexer settings:
This preference calls the KOREAN
LEXER Tile and can be used for parsing Korean text. Because the KOREAN
LEXER Tile does not have any attributes, no attributes are set for this
preference.
This preference calls the THEME LEXER
Tile, which indicates the preference can be used in a column policy to
create theme indexes for a column.
The THEME_LEXER preference does not set any attributes because
the THEME LEXER preference doesn't have any attributes.
This preference call the CHINESE
V-GRAM LEXER Tile, which indicates the preferences can be used for
parsing Chinese text.
The 1 or 2 indicates that the preference uses either method
1 or 2 for identifying tokens in Chinese text (hanzi_indexing attribute).
This preference call the JAPANESE
V-GRAM LEXER Tile which indicates the preferences can be used for parsing
Japanese text.
The 1 or 2 indicates that the preference uses either method
1 or 2 for identifying tokens in Japanese text (kanji_indexing attribute).
ConText supplies a single predefined Engine preference, DEFAULT_INDEX.
This preference calls the GENERIC
ENGINE Tile which is used to specify the amount of memory reserved
for indexing.
DEFAULT_INDEX uses the index_memory attribute to allocate
the following amount of memory for indexing: 12582912 bytes.
ConText provides the following predefined Wordlist preferences, which all use the GENERIC WORD LIST Tile:
This preference is identical to the NO_SOUNDEX
preference, except the section_group attribute has a value of 'BASIC_HTML_SECTION',
which is a predefined section group provided by ConText for basic section
searching of HTML text.
This preference specifies a value of 0 for the soundex_at_index
attribute to indicate that ConText does not generate Soundex word mappings
during text indexing.
This preference specifies a value of 1 for the soundex_at_index
attribute to indicate that ConText generates Soundex word mappings during
text indexing.
This preference specifies a value 3 for the fuzzy_match
attribute to ensure fuzzy matching is not enabled for Korean.
This preference specifies a value 4 for the fuzzy_match
attribute to ensure fuzzy matching is not enabled for Chinese.
This preference specifies a value 2 for the fuzzy_match
attribute to enable fuzzy matching for Japanese.
ConText provides the following predefined Stoplist preferences for creating text indexes:
|
Note: All of the Stoplist preferences call the GENERIC STOP LIST Tile. |
This preference defines a list of English terms treated as
stop words during indexing.
In addition to the English stoplist in DEFAULT_STOPLIST,
ConText supplies stoplists for many European languages. These stoplists
are not provided as predefined Stoplist preferences; they are provided
as SQL scripts which can be used to create Stoplist preferences for the
languages.
| See
Also:
For a complete list of the stop words in DEFAULT_STOPLIST, as well as the list of stop words for each supplied stoplist, see Appendix A, "Supplied Stoplists". |
This preference specifies that no list of stop words is used
during text indexing. All words that ConText encounters are stored in the
text index.

ConText supports four methods of storing text in a column:
|
Note: The tables illustrated in the following sections are examples only. The column names and definitions for actual tables used to store text will vary depending on the needs of your application. |
With direct storage, text for documents is stored directly
in a database column. The following table description illustrates a table
in which text is stored directly in a column:
The requirements for storing text directly in a column are
relatively straightforward. The text is physically stored in a text column
and the policy for the text column contains a Data Store preference that
utilizes the DIRECT Tile.
Master-detail storage is for documents stored directly in
a text column, similar to direct storage; however, each document consists
of one or more rows which are indexed as a single row.
In a master-detail relationship, the master table contains
the textkey column and the detail table contains the text column, the line
number column, and a foreign key to a primary or unique key column in the
master table.
The foreign key and the line number columns comprise the
primary key for the detail table, which is used to store the text.
The following table description illustrates two tables with
a master-detail relationship:
The following query illustrates the relationship between the two tables:
select DETAIL.TEXT from DETAIL where DETAIL.FK = MASTER.PK order by DETAIL.LINENO
ConText supports two methods of creating policies for text columns in master-detail tables:
With this method, the MASTER DETAIL
NEW Tile is used to create Data Store preferences, which are used in
the policy assigned to one of the columns in the master table. The column
to which the policy is assigned (i.e. the text column) can be any column
in the master table, except the column that serves as the textkey
column for the policy.
|
Note: The contents of the text column are not actually indexed. The text column only serves as a place-holder for the policy. |
The detail table name and attributes, including the name
of the column that contains the text to be indexed, are specified in the
Data Store preference.
Using the tables described above, the textkey for the policy
would be pk in master. The text column for the policy could
be either author or title.
The Data Store preference for the policy would identify detail
as the detail table, lineno as the line number column, and text
as the column containing the text to be indexed.
| See
Also:
For an example of creating a policy on a master table column, see"Creating a Data Store Preference for a Master Table" in Chapter 9, "Setting Up and Managing Text" |
This method has the following advantages:
For example:
exec ctx_query.contains('MY_POL','Oracle','ctx_temp', struct_query=>'author=''SMITH''');
This method has the following limitations:
With this method, the policy is created on the detail table,
rather than on the master table, and the MASTER
DETAIL Tile is used instead of the MASTER DETAIL NEW Tile, to create
Data Store preferences.
The textkey column and text column for the detail table,
along with the line number column, are specified in the policy. The textkey
column and the line number column together uniquely identify rows in the
detail table.
Using the tables described above, the textkey for the policy
would be fk in detail. The text column for the policy would
be text.
This method has the following disadvantages:
With operating system storage, the text column does not contain
the actual text of the document, but rather stores a pointer (file name)
to the operating-system file that contains the text of the document. The
Data Store preference for the column policy uses the OSFILE
Tile and specifies the location of the file.
The following table description illustrates a table that
uses external data storage:
In this example, the only difference between a table used
to store text internally and externally is the datatype of the text column.
In an external table, the text column would typically be assigned a datatype
of VARCHAR2, rather than LONG, because the column contains a pointer to
a file rather than the contents of the file (which requires more space
to store).
The names of the external text files are stored in the text
column.
The directory path(s) where the external text files are located
can be stored in the text column as part of the file name or in the Data
Store preference that you create for the OSFILE
Tile.
|
Note: If the preference does not contain the directory path for the files, ConText requires the directory path to be included as part of the file name stored in the text column. |
All the external files referenced in the text column must
be accessible from the server machine on which the ConText server is running.
This can be accomplished by storing the files locally in the file system
for the server machine or by mounting the remote file system to the server
machine.
File permissions for external files in which text is stored
must be set accordingly to allow ConText to access the files. If the file
permissions are not set properly for a file and ConText cannot access the
file, the file cannot be indexed or retrieved by ConText.
For text stored in external World Wide Web files, the complete
address for each file must be stored as a Uniform Resource Locator (URL)
in the text column and the URL Tile must be
utilized in the Data Store preference for the column policy.
A URL consists of the access scheme for the Web file and the address of the file, in the following format:
access_scheme://file_address
The ConText URL Tile supports three access scheme protocols in URLs:
If a URL uses HTTP, the file address contains the host name
of the Web server where the file is located and, optionally, the URL path
for the file on the Web server.
For example:
http://my_server.com/welcome.html http://www.oracle.com
|
Note: The file address may also (optionally) contain the port on which the Web server is listening. |
In this context, a Web server is any host machine that is
running an HTTP daemon, which accepts requests for files and transfers
the files to the requestor.
If a URL uses FTP, the file address contains the host name
of the Web server where the file is located and, optionally, the directory
path for the file on the Web server.
For example:
ftp://my_server.com/code/samples/sample1.tar.Z
|
Note: The file address may also (optionally) contain a username/password for accessing the host machine. |
In this context, a Web server is any host machine that is
running an FTP daemon, which accepts requests for files and transfers the
files to the requestor.
If a URL uses the file protocol, the address for the file
contains the absolute directory path for the location of the file on the
local file system.
For example:
file://private/docs/html/intro.html
The file referenced by a URL using the file protocol must
reside locally on a file system that is accessible to the machine running
ConText.
Because the file is accessed through the operating system,
the machine on which the file is located does not need to be configured
as a Web server. However, the same requirements that apply to text stored
as file names apply to text stored as URLs which use the file protocol.
If the requirements are not met, ConText returns one or more
error messages.
| See
Also:
For more information, see "External Storage (URLs)" in this chapter. For the error messages returned by the URL data store, see Oracle8 Error Messages. |
Through HTTP and FTP, the URL Tile can be used to index files
in an intranet, as well as files on any publicly-accessible Web servers
on the World Wide Web.
Intranets are private networks that use the Internet to link
machines in the network, but are protected from public access on the Internet
via a gateway proxy server which acts as a firewall.
Outside a firewall, a URL request for a Web file is processed
directly by the host machine identified in the URL. Within a firewall,
requests are processed by the proxy server, which passes the request to
the appropriate host machine and transfers the response back to the requestor.
For security reasons, access to an intranet is generally
restricted to machines within the firewall; however, machines in an intranet
can access the World Wide Web through the gateway proxy server if they
have the appropriate permission and security clearance.
When HTTP or FTP is used in a URL stored in the database,
ConText acts as a client, submitting a request to a Web server for the
file (document) referenced by the URL. If the request is successful, the
Web server returns the file to ConText where it can be indexed for querying
or highlighted for viewing.
If the document to be accessed is located on the World Wide
Web outside a firewall and the machine on which ConText is installed is
inside the firewall, a host machine that serves as the proxy (gateway)
for the firewall must be specified as an attribute for the URL
Tile.
A single machine can be specified as the proxy for handling
HTTP and FTP requests or two separate machines can be specified, one for
each protocol. If network traffic is expected to be heavy or a large number
of FTP requests are expected, separate proxies should be specified for
HTTP and FTP, since FTP is generally used for accessing large, binary files
which may affect performance on the proxy server.
In addition to specifying proxy servers, a sub-string of
host or domain names, which identify all or most of the machines internal
to the firewall, should be specified. Access to these machines does not
require going through the proxy server, which helps reduce the request
load that your proxy server(s) have to process.
In a single-threaded environment, a request for a URL blocks
all other requests until a response to the request is returned. Because
a response may not be returned for a long time, a single-threaded environment
in any text system using HTTP or FTP to access files could create a bottleneck.
To prevent this type of bottleneck, the URL Tile supports
multi-threading. With multi-threading, while one thread is blocked, waiting
to communicate with a Web server, another thread can retrieve a document
from another Web server.
The response to a request to retrieve a URL may be a new
(redirected) document to retrieve. The URL Tile supports this type of redirection
by automatically processing the redirection to retrieve the new document.
However, to avoid infinite loops, the URL Tile limits the number of redirections
that it attempts to process to three (3).
The time necessary to retrieve a URL using HTTP may vary
widely, depending on where the Web server is geographically located. The
Web server may even be temporarily unreachable.
To allow control over the length of time an application waits
for a response to an HTTP request for a URL, the URL data store supports
specifying a maximum timeout.
When using URLs as your data store, a number of exceptions
can occur when a file is accessed. These exceptions are written as errors
to the CTX_INDEX_ERRORS view.
The URL data store returns error messages for the following exceptions:
| See
Also:
For the error messages returned by the URL data store, see Oracle8 Error Messages. |
ConText provides the following Tile(s) for creating Data
Store preferences:
The DIRECT Tile is used for text stored directly in the database.
It has no attributes.
The MASTER DETAIL Tile is used for text stored directly in
the database in master-detail tables, with the textkey column located in
the detail table. The column policy is assigned to this column.
The MASTER DETAIL Tile has the following attribute(s):
| Attribute | Attribute Values |
|---|---|
|
binary |
0 (plain text) |
|
|
1 (binary text) |
The binary attribute specifies whether text is in
plain text format (0) or binary format (1) in the detail table in a master-detail
relationship.
Text in plain text format uses newline characters at the
end of each line to indicate the end of the line. Text in binary format
does not use newline characters to indicate the end of the line.
The MASTER DETAIL NEW Tile is used for text stored directly
in the database in master-detail tables, with the textkey column located
in the master table. The column policy is assigned to this column and all
detail information is stored in the Data Store preference, rather than
the column policy.
MASTER DETAIL NEW has the following attribute(s):
The binary attribute specifies whether the text in a master detail table is in plain text format (0) or binary format (1).
The detail_table attribute specifies the name of the detail table in the master-detail relationship.
The detail_key attribute specifies the name of the foreign key column in the detail table.
The detail_lineno attribute specifies the name of the column in the detail table that identifies rows in the table.
The detail_text attribute specifies the name of the
text column in the detail table.
The OSFILE Tile is used for text stored in files accessed
through the local file system.
OSFILE has the following attribute(s):
| Attribute | Attribute Values |
|---|---|
|
path |
path1:path2:...:pathn |
The path attribute specifies the location of text
files that are stored externally in a file system.
Multiple paths can be specified for path, with each
path separated by a colon (:). File names are stored in the text column
in the text table. If path is not used to specify a path for external
files, ConText requires the path to be included in the file names stored
in the text column.
The URL Tile is used for text stored:
URL has the following attribute(s):
The timeout attribute specifies the length of time,
in seconds, that a network operation such as 'connect' or 'read' waits
before timing out and returning a timeout error to the application. The
valid range for timeout is 0 to 3600 and the default is 30.
|
Note: Since timeout is at the network operation level, the total timeout may be longer than the time specified for timeout. |
The maxthreads attribute specifies the maximum number
of threads that can be running at the same time. The valid range for maxthreads
is 1 to 1024 and the default is 8.
The maxurls attribute specifies the maximum number of rows that the internal buffer can hold for HTML documents (rows) retrieved from the text table. The valid range for maxurls is 1 to 4294967295 and the default is 256.
The urlsize attribute specifies the maximum length,
in bytes, that the URL data store supports for URLs stored in the database.
If a URL is over the maximum length, an error is returned. The valid range
for urlsize is 32 to 65535 and the default is 256.
The maxdocsize attribute specifies the maximum size, in bytes, that the URL data store supports for accessing HTML documents whose URLs are stored in the database. The valid range for maxdocsize is 1 to 4294967295 and the default is 200000 (2 Mb).
The http_proxy attribute specifies the fully-qualified name of the host machine that serves as the HTTP proxy (gateway) for the machine on which ConText is installed. This attribute must be set if the machine is in an intranet that requires authentication through a proxy server to access Web files located outside the firewall.
The ftp_proxy attribute specifies the fully-qualified name of the host machine that serves as the FTP proxy (gateway) for the machine on which ConText is installed. This attribute must be set if the machine is in an intranet that requires authentication through a proxy server to access Web files located outside the firewall.
The no_proxy attribute specifies a string of domains
(up to sixteen, separate by commas) which are found in most, if not all,
of the machines in your intranet. When one of the domains is encountered
in a host name, no request is sent to the machine(s) specified for ftp_proxy
and http_proxy. Instead, the request is processed directly by the
host machine identified in the URL.
For example, if the string 'us.oracle.com, uk.oracle.com'
is entered for no_proxy, any URL requests to machines that contain
either of these domains in their host names are not processed by your proxy
server(s).
The following example creates a preference named doc_ref for the OSFILE Tile:
begin ctx_ddl.set_attribute ('PATH', '/private/mydocs'); ctx_ddl.create_preference ('DOC_PREF', 'Path my for my documents' 'OSFILE'); end;
|
Note: This example illustrates usage of OSFILE for documents stored in a UNIX-based environment. The directory path syntax may be different for other environments. |

ConText supports both plain text and formatted text (i.e.
Microsoft Word, WordPerfect). In addition, ConText supports text that contains
hypertext markup language (HTML) tags.
Regardless of the format, ConText requires text to be filtered
for the purposes of indexing the text or processing the text through the
Linguistics, as well as highlighting the text for viewing.
This section discusses the following topics relevant to text filtering:
| See
Also:
For more information about Linguistics and text highlighting, see Oracle8 ConText Cartridge Application Developer's Guide. |
ConText provides internal filters for:
In addition, ConText provides the Autorecognize
Filter, an internal filter for columns containing mixed formats.
Plain text requires no filtering because the text is already
in the format that ConText requires for identifying tokens.
ConText provides an internal filter that supports English
and Japanese text with HTML tags for versions 1, 2, and 3.
|
Note: For non-English and non-Japanese documents that contain HTML tags, an external filter must be used. |
The HTML filter processes all text that is delimited by the
standard HTML tag characters (angle brackets).
All HTML tags are either ignored or converted to their representative
characters in the ASCII character set. This ensures that only the text
of the document is processed during indexing or by the Linguistics.
ConText provides internal filters for filtering English and
Western European text in a number of proprietary word processing formats.
|
Note: For Japanese, Korean, and Chinese formatted text, external filters must be used. |
The filters extract plain, ASCII text from a document, then
pass the text to ConText, where the text is indexed or processed through
the Linguistics. The following document formats are supported by the internal
filters:
For those formats not supported by the internal filters,
user can define/create their own external filters.
Autorecognize is an internal filter that automatically recognizes
the document formats of all the supported internal filters, as well as
plain text (ASCII) and HTML formats, and extracts the text from the document
using the appropriate filters.
|
Note: Microsoft Word for Windows 7.0 documents are not recognized by Autorecognize. As a result, ConText does not support storing Microsoft Word for Windows 7.0 documents in mixed-format columns. |
ConText provides a framework for users to plug-in user-defined and/or third-party filters to extract plain text from documents. These external filters can be used for a number of purposes, including:
For example, the Linguistics rely on text that is grouped
into logical paragraphs. If the text stored in the database does not contain
clearly-identified paragraphs, the quality of the output generated by the
Linguistics may be poor.
An external filter that outlines the paragraph boundaries
according to ConText standards could be created to ensure that the Linguistics
are provided with an ordered, logical text feed.
|
Note: External filters do not support WYSIWYG viewing in the ConText viewers provided with the ConText Workbench. For more information about the ConText viewers, see Oracle8 ConText Cartridge Workbench User's Guide. . |
An external filter can be any executable (e.g. shell script,
C program, perl script) that processes an input file and produces a plain
text output file. The text in the output file then can be indexed.
If the document is in a proprietary format, the executable
must recognize the format tags for the document and be able to convert
the formatted text into plain (ASCII) text.
In addition, the executable must be able to run from the operating system command-line and accept two system-supplied arguments:
The external filter does not need to provide the values for
these arguments; Context provides the values as part of its external filter
processing.
|
Note: The name of the executable cannot be larger than 64 bytes. In addition, the name cannot contain blank spaces or any of the following illegal characters: ! @ # $ % ^ & * ( ) ~ \ Q ' , ^ : " ; , |
Performance is dependent on the external filter; ConText
cannot begin processing a document until the entire document has been filtered.
The external filter that performs the filtering should be tuned/optimized
accordingly.
The process model for using external filters is:
The Tile you use to create the preference depends on whether you use the column to store documents in a single format or mixed formats.
| See
Also:
For examples of creating Filter preferences for external filters, see "Creating Filter Preferences" in Chapter 9, "Setting Up and Managing Text". |
ConText provides a number of external filters for filtering
many of the most popular word processing and desktop publishing formats
on a number of platforms.
| See
Also:
For a complete list of the external filters supplied by ConText, as well as instructions for setting up and using the filters, see "Supplied External Filters" in Appendix D, "External Filter Specifications". |

For columns that store documents in only one format, a single
filter is specified in the Filter preference for the column policy. The
filtering method for the column is determined by whether the format is
supported by the internal or external filters.
Figure 8-5 illustrates the different
filtering methods for single-format columns.
| See
Also:
For examples of creating Filter preferences for single-format columns, see "Creating Filter Preferences" in Chapter 9, "Setting Up and Managing Text". |

For columns that store documents in mixed formats, the filtering
method is determined by whether the formats are supported by the internal
filters, external filters, or both.
Figure 8-6 illustrates the different
filter specification methods for mixed-format columns.
| See
Also:
For examples of creating Filter preferences for mixed-format columns, see "Creating Filter Preferences" in Chapter 9, "Setting Up and Managing Text". For a complete list of supported formats for mixed-format columns, see "Supported Formats for Mixed-Format Columns" in Appendix D, "External Filter Specifications". |
Filter Tiles are used to create preferences which determine
how text is filtered for indexing and highlighting. Filters allow word
processor and formatted documents, as well as ASCII and HTML text documents,
to be indexed and highlighted by ConText.
For formatted documents, ConText stores documents in their
native format and uses filters to build temporary ASCII versions of the
documents. ConText indexes the temporary ASCII text of the formatted document.
ConText also uses the ASCII version to highlight query terms.
ConText provides internal filters for processing many of
the popular document formats, including Microsoft Word, WordPerfect, and
AmiPro.
In addition, ConText allows users to specify external filters
for filtering documents in formats not supported by the internal filters
provided with ConText.
External filters can also be used to perform operations,
such as cleaning up or converting text, before the text is filtered for
indexing and highlighting.
ConText provides the following Tile(s) for creating Filter
preferences:
The BLASTER FILTER Tile is used to specify either:
BLASTER FILTER has the following attribute(s):
The executable attribute specifies the external filters that are used to filter text stored in a mixed-format text column. It has three values that must be specified:
|
Note: format and executable are mutually exclusive. |
| See
Also:
For a list of the format IDs supported by the executable attribute, see "Supported Formats for Mixed-Format Columns" in Appendix D, "External Filter Specifications". |
The format attribute specifies the internal filter
used for filtering text stored in a text column.
The FILTER NOP Tile is used to specify that plain text is
stored in the text column and no filtering needs to be performed. It has
no attributes.
The HTML FILTER Tile is used to specify that the internal
HTML filter is used to filter plain text that contains HTML tags.
HTML_FILTER has the following attribute(s):
| Attribute | Attribute Values |
|---|---|
|
code_conversion |
0 (disabled) |
|
|
1(enabled) |
|
keep_tag |
tag (string), sequence (number) |
The code_conversion attribute specifies whether code
conversion is enabled for documents which contain Japanese ASCII text with
HTML tags.
Code conversion is required for Japanese HTML documents if
the documents use more than one of the three character sets supported for
HTML text in Japanese. If code conversion is enabled, all Japanese HTML
documents are converted to a single, common character set before indexing.
The default for code_conversion is 0 (disabled).
The keep_tag attribute takes two values: the HTML
tag to retain during indexing and a sequence number that uniquely identifies
the tag.
The following rules apply to keep_tag:
For example, keep_tag is set to BODY and the following string occurs in a document:
<HTML><BODY BGCOLOR=#ffffff>hello</BODY></HTML>
ConText translates the string to:
<BODY>hello</BODY>
This string is passed to the HTML filter, which ignores the HTML tags, then to the lexer, which indexes the token hello as belonging to the BODY section.
The USER FILTER Tile is used to specify an external filter
for filtering documents in a column.
USER FILTER has the following attribute(s):
| Attribute | Attribute Values |
|---|---|
|
command |
filter executable |
The command attribute specifies the executable for
the single external filter used to filter all text stored in a column.
If more than one document format is stored in the column, the external
filter specified for command must recognize and handle all such
formats, otherwise the BLASTER FILTER Tile
(with the executable attribute) should be used instead of the USER
FILTER Tile.
The following section provides two Filter preference examples.
| See
Also:
For more examples of creating Filter preferences, see "Creating Filter Preferences" in Chapter 9, "Setting Up and Managing Text". |
The following example creates a preference named word6 for the BLASTER FILTER Tile:
begin ctx_ddl.set_attribute ('FORMAT', '11'); ctx_ddl.create_preference ('WORD6', 'Microsoft Word docs', 'BLASTER FILTER'); end;
The following example creates a preference named sect_filt_pref for the HTML FILTER Tile:
begin ctx_ddl.set_attribute('KEEP_TAG', 'TITLE', 1); ctx_ddl.set_attribute('KEEP_TAG', 'HEAD', 1); ctx_ddl.set_attribute('KEEP_TAG', 'BODY', 1); ctx_ddl.set_attribute('KEEP_TAG', 'H1', 1); ctx_ddl.create_preference('sect_filt_pref','sect search filt','HTML FILTER'); end;
In this example, the <TITLE>, </TITLE>, <HEAD>,
</HEAD>, <BODY>, </BODY>, <H1>, and </H1> HTML tags are
retained by the HTML filter during filtering, provided the startjoins
and endjoins attributes for the BASIC LEXER
Tile are set appropriately.
|
Note: When using keep_tag to specify tags to be retained, you do not need to specify the angle bracket or forward slash characters in the tag strings. |
| See
Also:
For more information about document sections, see "Document Sections" in Chapter 6, "Text Concepts". |

A lexer parses text and identifies tokens for indexing. ConText supports two types of lexers:
The text lexer provided for English and other single-byte, space-delimited languages supports the following features:
English and other single-byte languages, including most European
languages, can use the same lexer because tokens (words) in those languages
are delimited by blank spaces and standard punctuation (commas, periods,
question marks, etc.).
Japanese, Chinese, and many other Asian languages are pictorial
(multi-byte) languages that cannot be tokenized in the same manner as single-byte
languages.
ConText includes a single lexer (BASIC
LEXER Tile) for all of the single-byte, space-delimited languages,
such as English (7-bit character set) and other European languages (8-bit
character sets). The basic lexer also works with languages such as Greek,
which have different alphabets, but still utilize blank spaces to delimit
words.
ConText provides three separate lexers for processing Japanese,
Chinese, and Korean text.
The Chinese (CHINESE V-GRAM LEXER
Tile) and Japanese (JAPANESE V-GRAM LEXER Tile)
lexers do not rely on finding token boundaries within text; instead, they
uses a dictionary of terms to match and index patterns of characters at
user-specified, variable points of length.
The Japanese and Chinese lexers also work with languages
that use a 7-bit character set, such as English. As a result, ConText supports
indexing and querying Japanese and Chinese text that also contains English
text.
|
Note: Languages that use an 8-bit character set, such as many of the European languages, are not supported by the Japanese and Chinese lexers. |
The Korean lexer (KOREAN LEXER
Tile), works similarly to the Japanese and Chinese lexers by finding character
patterns in the text and matching the patterns to a dictionary of terms.
However, due to the significant morphological transformations that Korean
verbs undergo, the Korean lexer only indexes nouns and noun phrases.
By specifying one of the text lexers in the Lexer preference
for a policy, you designate the policy as a text indexing policy.
Once a text index is created for the policy, any text requests,
including text queries, on the policy will result in the text index being
accessed.
| See
Also:
For more information about text indexing, see "Text Indexes" in Chapter 6, "Text Concepts". |
For English-language text, a separate lexer (THEME
LEXER Tile) is provided for creating theme indexes. This lexer breaks
text into tokens; however, the tokens are not stored in the theme index.
The tokens are passed to the ConText linguistic core where they are analyzed
within the context of the sentences and paragraphs in which they appeared
to determine whether they are content-bearing words. The linguistic core
then generates themes, which are stored in the theme index.
The themes generated by ConText are based on, but are not
identical to, the content-bearing tokens in the text.
By specifying the THEME LEXER Tile in the Lexer preference
for a policy, you designate the policy as a theme indexing policy.
Once a theme index is created for the policy, any text requests,
including theme queries, on the policy will result in the theme index being
accessed.
| See
Also:
For more information about theme indexing, see "Theme Indexes" in Chapter 6, "Text Concepts". |
For text indexes created on text columns containing languages
that use an 8-bit (single-byte) character set, you can specify whether
extended characters encountered in tokens are converted to their base-letter
representation before their tokens are stored in the text index. Extended
characters include special characters and characters with diacritical marks
(e.g. accents, umlauts).
Base-letter conversion is an attribute that you can set when
creating a Lexer preference using the BASIC LEXER
Tile.
If base-letter conversion is enabled for the Lexer preference
in a policy, during text indexing, all characters containing diacritical
marks are converted to their base form in the text index. The original
text is not affected.
Base-letter conversion requires that the database character
set is a subset of the NLS_LANG character set.
For example, suppose the NLS_LANG environment variable is set to French_France.WE8ISO8859P1 and base-letter conversion is enabled. The following string of text is encountered:
La référence de session doit être égale à 'name'
The sentence is indexed as:
la reference de session doit etre egale a name
| See
Also:
For more information about National Language Support and the NLS_LANG environment variable, see Oracle8 Reference Manual. |
In a text query on a column with base-letter conversion enabled,
the query terms are automatically converted to match the base-letter conversion
that was performed during text indexing.
|
Note: Base-letter conversion works with all of the query operators (logical, control, expansion, thesaurus, etc.), except the STEM expansion operator. |
| See
Also:
For more information about text queries and the query operators, see Oracle8 ConText Cartridge Application Developer's Guide. . |
The BASIC LEXER Tile supports
all NLS-compliant character sets, including the AL24UTFFSS (UTF-8) character
set. UTF-8 is a character set that recognizes the characters from most
single-byte and multi-byte character sets.
Users with multilingual environments, such as multinational
companies, can specify UTF-8 for a database and use the database to store
documents that use any one of the character sets supported by UTF-8. ConText
supports indexing all documents stored in a UTF-8 database and queries
to the database from clients running any of the UTF-8 supported character
sets.
The BASIC LEXER Tile currently supports the UTF-8 character
set only for space-delimited, single-byte languages, which includes English
and other Western European languages.
The BASIC LEXER Tile does not support UTF-8 for the multi-byte
languages, nor do the Japanese, Chinese, and Korean lexers currently support
UTF-8.
The BASIC LEXER Tile does not require any setup to enable
it to handle UTF-8 or other NLS-compliant character sets; however, the
NLS_LANG environment variable must be set to the appropriate language/territory/character
set. In addition, the ORA_NLS32 and ORA_NLS environment variables must
be set to the directories containing the appropriate NLS data.
The lexer has the following limitations when UTF-8 is the character set specified for the database:
For German or Dutch text, the BASIC
LEXER Tile provides an attribute for enabling composite word indexing.
With composite word indexing, tokens that are compound words (specifically
nouns) are divided into their constituent (root) nouns, including inflected
forms of the roots, and the roots are stored in the ConText index along
with the entry for the compound word.
For example, if the word Hauptbahnhof is encountered
in a German-language document during composite word indexing, the following
entries are created in the index: HAUPTBAHNHOF, HAUPT, BAHN, BAHNEN,
HOF.
Composite word indexing supports both single-byte and multi-byte
character sets, specifically WE8ISO8859P9 (extended, single-byte) and AL24UTFFSS
(multi-byte).
Composite indexes have the following limitations:
Composite word indexing enables text queries to return all
documents that contain either the query term itself or the query term as
a root of a compound word; however, queries for phrases that contain one
or more compound words return only the documents that contain the exact
phrase.
| Note:
For more information about composite word queries, see Oracle8 ConText Cartridge Application Developer's Guide. . |
ConText provides the following Tile(s) for creating Lexer
preferences:
The BASIC LEXER Tile is used to identify tokens for creating
text indexes for English and all other supported single-byte languages.
It is also used to enable base-letter conversion for single-byte languages
that have extended character sets and composite word indexing for German
and Dutch text.
BASIC LEXER has the following attribute(s):
continuation specifies the characters that indicate a word continues on the next line and should be indexed as a single token. The most common continuation characters are hyphen '-' and backslash '\'.
numgroup specifies the characters that, when they
appear in a string of digits, indicate that the digits are groupings within
a larger single unit.
For example, comma ',' or period '.' may be defined as numgroup characters because they often indicate a grouping of thousands when they appear in a string of digits.
numjoin specifies the characters that, when they appear
in a string of digits, cause ConText to index the string of digits as a
single unit or word.
For example, period '.' or comma ',' may be defined as numjoin
characters because they often serve as decimal points when they appear
in a string of digits.
printjoins specifies the non-alphanumeric characters
that, when they appear anywhere in a word (beginning, middle, or end),
are processed by ConText as alphanumeric and included with the token in
the text index. This includes printjoins that occur consecutively.
For example, if the hyphen '-' and underscore '_' characters
are defined as printjoins, terms such as pseudo-intellectual
and _file_ are stored in the text index as pseudo-intellectual
and _file_.
punctuations specifies the non-alphanumeric characters
that, when they appear at the end of a word, indicate the end of a sentence.
The defaults are period '.', question mark '?', and exclamation point '!'.
Characters that are defined as punctuations are removed
from a token before text indexing; however, if a punctuations character
is also defined as a printjoins character, the character is only
removed if it is the last character in the token and it is immediately
preceded by the same character.
For example, if the period (.) is defined as both a printjoins
and a punctuations character, the following transformations take
place during indexing and querying as well:
| Token | Indexed Token |
|---|---|
|
.doc |
.doc |
|
dog.doc |
dog.doc |
|
dog..doc |
dog..doc |
|
dog. |
dog |
|
dog... |
dog.. |
In addition, BASIC LEXER uses punctuations characters in conjunction with newline and whitespace characters to determine sentence and paragraph deliminters for sentence/paragraph searching.
skipjoins specifies the non-alphanumeric characters
that, when they appear within a word, identify the word as a single token;
however, the characters are not stored with the token in the text index.
For example, if the hyphen character '-' is defined as a
skipjoins, the word pseudo-intellectual is stored in the
text index as pseudointellectual.
|
Note: printjoins and skipjoins are mutually exclusive. The same characters cannot be specified for both attributes. |
startjoins specifies the characters that, when encountered
as the first character in a token, explicitly identify the start of the
token. The character, as well as any other startjoins characters
that immediately follow it, is included in the ConText index entry for
the token. In addition, the first startjoins character in a string
of startjoins characters implicitly end the previous token.
endjoins specifies the characters that, when encountered
as the last character in a token, explicitly identify the end of the token.
The character, as well as any other startjoins characters that immediately
follow it, is included in the ConText index entry for the token.
The following rules apply to both startjoins and endjoins:
|
Note: Defining startjoins and endjoins characters is particularly useful for creating document sections that enable section searching in a column. For examples of creating sections and section groups, see "Managing User-defined Document Sections" in Chapter 9, "Setting Up and Managing Text". For more information about sections, see "Document Sections" in Chapter 6, "Text Concepts". For more information about section searching, see Oracle8 ConText Cartridge Application Developer's Guide. . |
whitespace specifies the characters that are treated
as blank spaces between tokens. BASIC LEXER uses whitespace characters
in conjunction with punctuations and newline characters to
identify character strings that serve as sentence delimiters for sentence/paragraph
searching.
The predefined, default values for whitespace are 'space' and 'tab'; these values cannot be changed. Specifying characters as whitespace characters adds to these defaults.
newline specifies the characters that indicate the
beginning of a new line of text. BASIC LEXER uses newline characters
in conjunction with punctuations and whitespace characters to identify
character strings that server as paragraph delimiters for sentence/paragraph
searching.
The only valid values for newline are '\n' and '\r' (for carriage returns) and the default is '\n'.
sent_para enables (1) or disables (0) sentence/paragraph searching. The default is '0'.
base_letter specifies whether characters that have diacritical marks (umlauts, cedillas, acute accents, etc.) are converted to their base form before being stored in the text index. The default is 0 (base-letter conversion disabled).
mixed_case specifies whether the lexer converts the
tokens in text index entries to all uppercase or stores the tokens exactly
as they appear in the text. The default is 0 (tokens converted to all uppercase).
The composite attribute specifies whether composite
word indexing is disabled (0) or enabled for either German (1) or Dutch
(2) text. The default is 0 (composite word indexing disabled).
|
Note: The composite and mixed_case attributes are mutually exclusive; Composite indexes do not support case-sensitivity. |
| See
Also:
For more information, see "Composite Word Indexing" in this chapter. |
The CHINESE V-GRAM LEXER Tile is used for identifying tokens
for creating text indexes for Chinese text.
CHINESE V-GRAM LEXER has the following attribute(s):
| Attribute | Attribute Values |
|---|---|
|
hanzi_indexing |
1 |
|
|
2 |
The hanzi_indexing attribute specifies the number
of characters used for pattern matching while indexing.
A value of 1 indicates that the Chinese lexer examines each
character individually to determine token boundaries.
A value of 2 indicates that the lexer examines characters
in pairs to determine token boundaries. Pattern matching using pairs is
generally faster than matching individual characters, resulting in faster
index creation.
The JAPANESE V-GRAM LEXER Tile is used for identifying tokens
for creating text indexes for Japanese text.
JAPANESE V-GRAM LEXER has the following attribute(s):
| Attribute | Attribute Values |
|---|---|
|
kanji_indexing |
1 |
|
|
2 |
The kanji_indexing attribute specifies the number
of characters used for pattern matching while indexing.
A value of 1 indicates that the Japanese lexer examines each
character individually to determine token boundaries.
A value of 2 indicates that the lexer examines pairs of characters
to determine token boundaries. Pattern matching using pairs is generally
faster than matching individual characters, resulting in faster index creation.
The KOREAN LEXER Tile is used for identifying tokens for
creating text indexes for Korean text. It has no attributes.
The THEME LEXER Tile is used in theme indexing policies to
create theme indexes for English-language text. It has no attributes.
| See
Also:
For an example of creating a theme indexing policy, see "Creating a Column Policy for Theme Indexing" in Chapter 9, "Setting Up and Managing Text". |
The following section provides two Lexer preference examples
that both use the BASIC LEXER Tile.
The following example creates a preference named doc_link:
begin ctx_ddl.set_attribute ('PRINTJOINS', '.-@&$#/'); ctx_ddl.create_preference ('DOC_LINK', 'numerous joins', 'BASIC LEXER' ); end;
In this example, the '.', '-', '@', '&', '$', '#', and
'/' characters are all defined as printjoins characters.
Characters such as the dollar sign '$' and number sign '#'
are useful if you want to index tokens that may contain these characters,
such as sums of money and numbers.
The following example creates a preference named section_pref:
exec ctx_ddl.set_attribute(`startjoins','</'); exec ctx_ddl.set_attribute(`endjoins','>'); exec ctx_ddl.set_attribute(`printjoins','_@-&$#.'); ... exec ctx_ddl.create_preference(`sect_lex_pref','basic lexing + sections','BASIC LEXER');
In this example, the characters `<` and '/' are defined
as startjoins characters. The character `>' is defined as an endjoins
character.
The open and closed angle brackets '< >' and the forward
slash '/' are useful for identifying HTML tags for document sections.
| See
Also:
For more information about sections, see "Document Sections" in Chapter 6, "Text Concepts" |
The indexing engine is the ConText component that creates
a ConText index for a text column. A ConText index is required before text
in a column can be queried.
ConText supplies a single engine that creates index entries
for Context indexes, independent of the format, location, language, and
character set of the text.
In particular, the engine determines the amount of memory
used to create ConText indexes and where in the database the indexes are
stored.
| See
Also:
For more information about creating an Engine preference, see "Creating an Engine Preference" in Chapter 9, "Setting Up and Managing Text". |
ConText provides the following Tile(s) for creating Engine
preferences:
| Tile | Description |
|---|---|
|
No engine used for indexing (Not implemented - DO NOT USE) |
|
|
Indexing engine used to create index entries and store in database tables comprising the ConText index. |
The ENGINE NOP Tile specifies that no engine is used for
indexing. This Tile is currently not implemented and should not
be used to create Engine preferences for indexing.
The GENERIC ENGINE Tile specifies that the indexing engine
provided by ConText is used for indexing.
In particular, the GENERIC ENGINE Tile attributes specify
the amount of memory allocated for indexing, and the tablespace(s) and
creation parameters for the database tables and indexes that constitute
a ConText index.
| See
Also:
For descriptions of the ConText index tables and indexes, see "Appendix C, "ConText Index Tables and Indexes". |
GENERIC ENGINE has the following attribute(s):
index_memory specifies the amount of memory, in bytes,
allocated for indexing.
optimize_default specifies the type of optimization used when CTX_DDL.OPTIMIZE_INDEX is called without an optimization type. If no value is specified for optimize_default, the default is DEFRAGMENT_TO_NEW_TABLE.
i1t_tablespace, ktb_tablespace, and lst_tablespace
specify the tablespaces used for the ConText index tables created during
indexing.
sqr_tablespace specifies the tablespace used for the
stored query expression result (SQR) table that is created, but not populated,
during indexing. The SQR table for a policy stores the results of stored
query expressions for the policy.
i1i_tablespace, kid_tablespace, kik_tablespace,
and lix_tablespace specify the tablespaces used for the Oracle
indexes generated for each ConText index table.
sri_tablespace specifies the tablespace used for the
Oracle index generated for each SQR table.
i1t_storage, ktb_storage, and lst_storage
specify the STORAGE clauses used to create the ConText index tables during
ConText indexing.
sqr_storage specifies the STORAGE clause used to create
the stored query expression result (SQR) table during ConText indexing.
i1i_storage, kid_storage, kik_storage, and
lix_storage specify the STORAGE clauses used to create the Oracle
indexes for each ConText index table.
sri_storage specifies the STORAGE clause used to create
the Oracle index for each SQR table.
| See
Also:
For more information about the STORAGE clause, see the CREATE TABLE and CREATE INDEX commands in Oracle8 SQL Reference. |
i1t_other_parms, ktb_other_parms, and lst_other_parms
specify any additional parameters used to create the ConText index tables
during ConText indexing.
sqr_other_parms specifies any additional parameters
used to create the stored query expression result (SQR) table during ConText
indexing.
i1i_other_parms, kid_other_parms, kik_other_parms,
and lix_other_parms specify any additional parameters used to
create the Oracle indexes for each ConText index table.
sri_other_parms specifies any additional parameters
used to create the Oracle index for each SQR table.
|
Note: In particular, the xxx_other_parms attributes are used to specify a value for the PARALLEL clause in the CREATE TABLE|INDEX command. The PARALLEL clause determines the degree of parallelism used by the Oracle parallel query option for operations such as generating Oracle indexes. For more information about the PARALLEL clause in CREATE TABLE and CREATE INDEX, as well as the other parameters that can be used to create database tables and indexes, see Oracle8 SQL Reference. For more information about the parallel query option in Oracle, see Oracle8 Tuning. |
| See
Also:
For more information about SQEs, see Oracle8 ConText Cartridge Application Developer's Guide. . |
The following example creates a preference named doc_engine for the GENERIC ENGINE Tile:
begin ctx_ddl.set_attribute ('INDEX_MEMORY', 30000000 ); ctx_ddl.set_attribute ('I1T_TABLESPACE', 'DOCUMENTS' ); ctx_ddl.set_attribute ('I1T_STORAGE',' initial 10M next 2M maxextents 10'); ctx_ddl.set_attribute ('I1T_OTHER_PARMS',' pctfree 20'); ctx_ddl.set_attribute ('I1I_OTHER_PARMS',' parallel 2'); ctx_ddl.create_preference ('DOC_ENGINE', 'Test case', 'GENERIC ENGINE' ); end;
ConText provides advanced query (Wordlist) options for expanding text queries using the following methods:
ConText also provides an option for refining text queries
using user-defined document sections.
| See
Also:
For more information about expanding and refining text queries, see Oracle8 ConText Cartridge Application Developer's Guide. For more information about user-defined sections for refining queries, see "User-Defined Sections" in Chapter 6, "Text Concepts". |
Stemming expands a text query by deriving variations (verb
conjugation, noun, pronoun, and adjective inflections) of the search token(s)
in the query.
For example, a stem search on the verb buy expands
to include its alternate verb forms, such as buys, buying,
and bought, but not on the noun buyer. A search on the noun
buyer would expand only to include its plural form buyers.
Since different languages have different stemming rules,
stemming is language-dependent and uses term lists that define the relationships
between the words in a given language
ConText provides a stemmer, licensed from Xerox Corporation,
that utilizes Xerox Lexical Technology to support inflectional and derivational
stemming in English and inflectional stemming in a number of Western European
languages.
For all the supported languages, the stemmers return standard
inflected forms of a word, such as the plural form (e.g. department
--> departments).
For English, an additional stemmer is provided which returns
standard inflected forms and derived forms (e.g. department -->
departments, departmentalize).
Fuzzy matching expands queries by including terms that are
spelled similar to the search token in the query. This type of expansion
can be useful in queries for text that contains frequent misspellings or
has been scanned using OCR software.
For example, a fuzzy matching query for the term cat
expands to include cats, calc, case.
The number of expansions generated by fuzzy matching depends
on the tokens that ConText identified during indexing; results can vary
significantly according to the tokens that were identified and indexed
by ConText for the column. As such, fuzzy matching depends on how tokens
are delimited in a given language.
|
Note: Fuzzy matching is designed primarily for English-language documents, but can be used, with varying degrees of success with many of the Western European languages. |
During text indexing of a column, Soundex, if enabled, creates
a list of all the words that sound alike and assigns one or more IDs to
each word to identify the other words in the list that sound like the word.
|
Note: Soundex is designed primarily to look for matches in phonetic spellings used in English, but can be used, with varying degrees of success with many of the other Western European languages. |
The Soundex wordlist is stored in the DR_nnnnn_I1W
ConText index table, where nnnnn is the identifier of the policy
for the text index.
If Soundex is enabled for a text column, users can call Soundex
in a query to expand the query. Soundex expands a query by searching the
I1W table for terms that sound similar to the specified query term.
For example, a Soundex search on the name Smith would
also find the names Smythe and Smit.
|
Note: Soundex in ConText uses the same algorithm as the SOUNDEX function in SQL. For more information about the SOUNDEX function in SQL, see Oracle8 SQL Reference. |
ConText provides a single Tile, GENERIC WORD LIST, for creating
Wordlist preferences.
The GENERIC WORD LIST Tile is used to enable the advanced
query options (stemming, fuzzy matching, Soundex, and user-defined section
searching) for text indexes.
| See
Also:
For more information about expansion methods in queries, see Oracle8 ConText Cartridge Application Developer's Guide. |
GENERIC WORD LIST has the following attribute(s):
The stclause attribute specifies the STORAGE clause used to create the Soundex wordlist table during ConText indexing. The Soundex wordlist table is only created if Soundex is enabled through the soundex_at_index attribute.
The instclause attribute specifies the STORAGE clause used to create the Oracle index for the Soundex wordlist table.
The soundex_at_index attribute specifies whether ConText generates Soundex word mappings and stores them in the Soundex wordlist table during text indexing. If Soundex word mappings are not generated and stored in the wordlist table during indexing, queries that use Soundex are not expanded.
The stemmer attribute specifies the stemmer used for word stemming in text queries. The default for stemmer is 1 (inflectional English)
The fuzzy_match attribute specifies which fuzzy matching
routines are used for the column. Fuzzy matching is currently supported
for English, Japanese, and, to a lesser extent, the Western European languages.
The default for fuzzy_match is 1.
|
Note: The fuzzy_match attribute values for Chinese and Korean are dummy attribute values that prevent the English and Japanese fuzzy matching routines from being used on Chinese and Korean text. |
The section_group attribute specifies the name of the section group to assign to a text column. The following rules apply to section_group:
| See
Also:
For more information about section groups, see "Document Sections" in Chapter 6, "Text Concepts". |
The following example creates a preference named soundex_yes for the GENERIC WORD LIST Tile:
begin ctx_ddl.set_attribute('SOUNDEX_AT_INDEX', '1'); ctx_ddl.create_preference('SOUNDEX_YES', 'Will build the soundex mapping during indexing', 'GENERIC WORD LIST'); end;
To manage the size of text indexes, ConText supports defining
stop words. Stop words are common terms that you do not want to include
in a text index.
The collection of stop words for a text column is called
a stoplist, as defined in a Stoplist preference. You can define up to 4095
stop words for a stoplist.
ConText does not create index entries for words defined as
stop words; however, it does record the stop words, up to eight, that proceed
and follow an indexed term. This enables text queries for phrases which
contain stop words.
To conserve space in the text index, ConText does not record
the actual stop words in the index entries. Instead, ConText records code
numbers, called sequences, that correspond to the stop words. Sequence
numbers are assigned to stop words by the user when a stoplist is defined.
For example, the words he, is, at, the, and of
are defined as stop words and each stop word is assigned a sequence by
the user. During indexing, the string "he is at the top of the class" is
encountered.
Index entries are created only for the words top and
class; however, the words he, is, at, the, and top
are stored as preceding and following stop words for the index entries.
As a result, users can query phrases such as 'he is at the
top' and 'top of the class'.
Stoplists for case-sensitive text indexes are automatically
case-sensitive, meaning that words in the text are only indexed as stop
words if they exactly match the case of the stop words in the stoplist.
As a result, when creating a Stoplist preference for a column
on which you want create a case-sensitive text index, you should specify
a stop word entry for each commonly occurring variation (i.e. lowercase,
initial uppercase, all-uppercase) that may occur for a stop word. For example,
some articles, such as a and the in English, often appear
at the beginning of sentences. As a result, the initial uppercase form
of the articles (A and The) should be included in the stoplist.
ConText provides a single Tile, GENERIC STOP LIST, for creating
Stoplist preferences.
The GENERIC STOP LIST Tile specifies the terms that should
not be included in the text index.
GENERIC STOP LIST has the following attribute(s):
| Attribute | Attribute Values |
|---|---|
|
stop_word |
word (string), sequence (number) |
The stop_word attribute has two values that must be specified:
The following example creates a preference named mini_stoplist for the GENERIC STOP LIST Tile:
begin ctx_ddl.set_attribute ('STOP_WORD', 'a', 1); ctx_ddl.set_attribute ('STOP_WORD', 'A', 2); ctx_ddl.set_attribute ('STOP_WORD', 'the', 3); ctx_ddl.set_attribute ('STOP_WORD', 'The', 4); ctx_ddl.set_attribute ('STOP_WORD', 'and', 5); ctx_ddl.set_attribute ('STOP_WORD', 'And', 6); ctx_ddl.create_preference ('MINI_STOPLIST', 'minilist', 'GENERIC STOP LIST' ); end;