Release 8.0
A58396-01
Library |
Product |
Contents |
Index |
| Oracle8 Backup and Recovery Guide Release 8.0 A58396-01 |
|
![]()
![]()
This chapter describes the structures comprising a database, as well as key backup and recovery concepts, and includes the following topics:
Recovery processes vary depending on the type of failure that occurred, the structures affected, and the type of backups available for performing recovery. If no files are lost or damaged, recovery may amount to no more than restarting an instance.
Several structures of an Oracle database safeguard data against possible failures. This chapter briefly introduce each of these structures and their use in backup and recovery.
Every instance of an Oracle database has an associated online redo log to protect the database in case the database experiences an instance failure. An online redo log consists of two or more pre-allocated files that store all changes made to the database as they occur.
|
Note: Oracle does not recommend backing up the online redo log. See "Online Redo Log Backups Not Recommended" for more information. |
Online redo log files are filled with redo entries. Redo entries record data that can be used to reconstruct all changes made to the database, including the rollback segments. Therefore, the online redo log also protects rollback data.
Redo entries are buffered in a "circular" fashion in the redo log buffer of the SGA and are written to one of the online redo log files by the Oracle background process Log Writer (LGWR). Whenever a transaction is committed, LGWR writes the transaction's redo entries from the redo log buffer of the system global area (SGA) to an online redo log file, and a system change number (SCN) is assigned to identify the redo entries for each committed transaction.
However, redo entries can be written to an online redo log file before the corresponding transaction is committed. If the redo log buffer fills, or another transaction commits, LGWR flushes all of the redo log entries in the redo log buffer to an online redo log file, even though some redo entries may not be committed.
The online redo log of a database consists of two or more online redo log files. Oracle requires two files to guarantee that one is always available for writing while the other is being archived, if desired.
LGWR writes to online redo log files in a circular fashion; when the current online redo log file is filled, LGWR begins writing to the next available online redo log file. When the last available online redo log file is filled, LGWR returns to the first online redo log file and writes to it, starting the cycle again. Figure 2-1 illustrates the circular writing of the online redo log file. The numbers next to each line indicate the sequence in which LGWR writes to each online redo log file.
Filled online redo log files are "available" to LGWR for reuse depending on whether archiving is enabled:
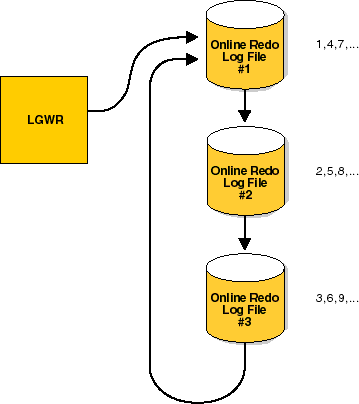
At any given time, Oracle uses only one of the online redo log files to store redo entries written from the redo log buffer. The online redo log file actively being written by LGWR is called the current online redo log file.
Online redo log files that are required for instance recovery are called active online redo log files. Online redo log files that are not required for instance recovery are called inactive.
If archiving is enabled, an active online log file cannot be reused or overwritten until its contents are archived. If archiving is disabled, when the last online redo log file fills, writing continues by overwriting the first available active file.
The point at which Oracle ends writing to one online redo log file and begins writing to another is called a log switch. A log switch always occurs when the current online redo log file is completely filled and writing must continue to the next online redo log file. The database administrator can also force log switches.
Oracle assigns each online redo log file a new log sequence number every time that a log switch occurs and LGWR begins writing to it. If online redo log files are archived, the archived redo log file retains its log sequence number. The online redo log file that is cycled back for use is given the next available log sequence number.
Each redo log file (including online and archived) is uniquely identified by its log sequence number. During instance or media recovery, Oracle properly applies redo log files in ascending order by using the log sequence number of necessary archived and online redo log files.
An event called a checkpoint occurs when the Oracle background process, DBW0 writes all the modified database buffers in the SGA, including both committed and uncommitted data, to the data files. Checkpoints are implemented for the following reasons:
Though some overhead is associated with a checkpoint, Oracle does not halt activity nor are current transactions affected. Because DBW0 continuously writes database buffers to disk, a checkpoint does not necessarily require many data blocks to be written all at once. Rather, the completion of a checkpoint simply guarantees that all data blocks modified since the previous checkpoint are actually written to disk.
Checkpoints occur whether or not filled online redo log files are archived. If archiving is disabled, a checkpoint affecting an online redo log file must complete before the online redo log file can be reused by LGWR. If archiving is enabled, a checkpoint must complete and the filled online redo log file must be archived before it can be reused by LGWR.
Checkpoints can occur for all datafiles of the database (called database checkpoints) or can occur for only specific datafiles. The following list explains when checkpoints occur and what type happens in each situation:
Incremental checkpointing improves the performance of crash and instance recovery (but not media recovery). An incremental checkpoint records the position in the redo thread (log) from which crash/instance recovery needs to begin. This log position is determined by the oldest dirty buffer in the buffer cache. The incremental checkpoint information is maintained periodically with minimal or no overhead during normal processing.
Recovery performance is roughly proportional to the number of buffers that had not been written to the database prior to the crash. You can influence the performance of crash or instance recovery by setting the parameter DB_BLOCK_MAX_DIRTY_TARGET, which specifies an upper bound on the number of dirty buffers that can be present in the buffer cache of an instance at any moment in time. Thus, it is possible to influence recovery time for situations where the buffer cache is very large and/or where there are stringent limitations on the duration of crash/instance recovery. Smaller values of this parameter impose higher overhead during normal processing since more buffers have to be written. On the other hand, the smaller the value of this parameter, the better the recovery performance, since fewer blocks need to be recovered.
Incremental checkpoint information is maintained automatically by the Oracle8 server without affecting other checkpoints (such as log switch checkpoints and user-specified checkpoints). In other words, incremental checkpointing occurs independently of other checkpoints occurring in the instance.
Incremental checkpointing is beneficial for recovery in a single instance as well as a multi-instance environment.
|
Note: Checkpoints also occur at other times if the Oracle Parallel Server is used; see Oracle8 Parallel Server Concepts and Administrationfor more information. |
When a checkpoint occurs, the checkpoint background process (CKPT) remembers the location of the next entry to be written in an online redo log file and signals the database writer background process (DBW0) to write the modified database buffers in the SGA to the datafiles on disk. CKPT then updates the headers of all control files and datafiles to reflect the latest checkpoint.
When a checkpoint is not happening, DBW0 only writes the least-recently-used database buffers to disk to free buffers as needed for new data. However, as a checkpoint proceeds, DBW0 writes data to the data files on behalf of both the checkpoint and ongoing database operations. DBW0 writes a number of modified data buffers on behalf of the checkpoint, then writes the least recently used buffers, as needed, and then writes more dirty buffers for the checkpoint, and so on, until the checkpoint completes.
Depending on what signals a checkpoint to happen, the checkpoint can be either "normal" or "fast." With a normal checkpoint, DBW0 writes a small number of data buffers each time it performs a write on behalf of a checkpoint. With a fast checkpoint, DBW0 writes a large number of data buffers each time it performs a write on behalf of a checkpoint.
Therefore, by comparison, a normal checkpoint requires more I/Os to complete than a fast checkpoint. Because a fast checkpoint requires fewer I/Os, the checkpoint completes very quickly. However, a fast checkpoint can also detract from overall database performance if DBW0 has a lot of other database work to complete. Events that trigger normal checkpoints include log switches and checkpoint intervals set by initialization parameters; events that trigger fast checkpoints include online tablespace backups, instance shutdowns, and database administrator-forced checkpoints.
Until a checkpoint completes, all online redo log files written since the last checkpoint are needed in case a database failure interrupts the checkpoint and instance recovery is necessary. Additionally, if LGWR cannot access an online redo log file for writing because a checkpoint has not completed, database operation suspends temporarily until the checkpoint completes and an online redo log file becomes available. In this case, the normal checkpoint becomes a fast checkpoint, so it completes as soon as possible.
For example, if only two online redo log files are used, and LGWR requires another log switch, the first online redo log file is unavailable to LGWR until the checkpoint for the previous log switch completes.
|
Note: The information that is recorded in the datafiles and control files as part of a checkpoint varies if the Oracle Parallel Server configuration is used; see Oracle8 Parallel Server Concepts and Administration. |
You can set the initialization parameter LOG_CHECKPOINTS_TO_ALERT to determine if checkpoints are occurring at the desired frequency. The default value of NO for this parameter does not log checkpoints. When you set the parameter to YES, information about each checkpoint is recorded in the ALERT file.
Oracle provides the capability to multiplex an instance's online redo log files to safeguard against damage to its online redo log files. With multiplexed online redo log files, LGWR concurrently writes the same redo log information to multiple identical online redo log files, thereby eliminating a single point of online redo log failure.
|
Note: Oracle recommends that you multiplex your redo log files; the loss of the log file information can be catastrophic if a recovery operation is required. |
Figure 2-2 illustrates duplexed (two sets of) online redo log files.
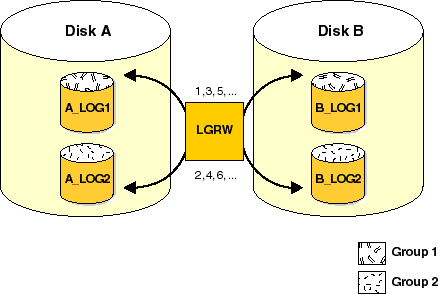
The corresponding online redo log files are called groups. Each online redo log file in a group is called a member. Notice that all members of a group are concurrently active (concurrently written to by LGWR), as indicated by the identical log sequence numbers assigned by LGWR. If a multiplexed online redo log is used, each member in a group must be the exact same size.
LGWR always addresses all members of a group, whether the group contains one or many members. For example, after a log switch, LGWR concurrently writes to all members of the next group, and so on. LGWR never writes concurrently to one member of a given group and one member of another group.
LGWR reacts differently when certain online redo log members are unavailable, depending on the reason for the file(s) being unavailable:
Whenever LGWR cannot write to a member of a group, Oracle marks that member as stale and writes an error message to the LGWR trace file and to the database's ALERT file to indicate the problem with the inaccessible file(s).
To safeguard against a single point of online redo log failure, a multiplexed online redo log should be completely symmetrical: all groups of the online redo log should have the same number of members. However, Oracle does not require that a multiplexed online redo log be symmetrical. For example, one group can have only one member, while other groups can have two members. Oracle allows this behavior to provide for situations that temporarily affect some online redo log members but leave others unaffected (for example, a disk failure). The only requirement for an instance's online redo log, multiplexed or non-multiplexed, is that it be comprised of at least two groups. Figure 2-3 shows a legal and illegal multiplexed online redo log configuration. The second configuration is illegal because it has only one group.
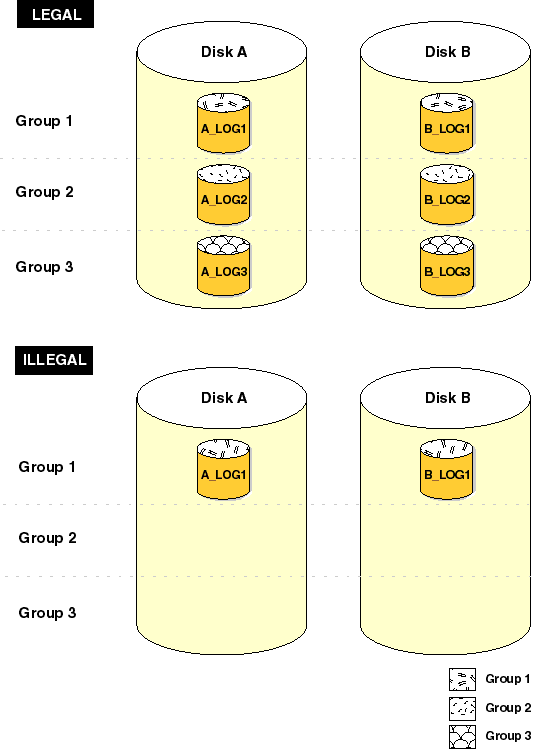
Each database instance has its own online redo log groups. These online redo log groups, multiplexed or not, are called an instance's "thread" of online redo. In typical configurations, only one database instance accesses an Oracle database, thus only one thread is present. However, when running the Oracle Parallel Server, two or more instances concurrently access a single database; each instance in this type of configuration has its own thread.
This manual describes how to configure and manage the online redo log when the Oracle Parallel Server is not used. The thread number can be assumed to be 1 in all discussions and examples of commands. For complete information about configuring the online redo log with the Oracle Parallel Server, see Oracle8 Parallel Server Concepts and Administration.
Oracle allows the optional archiving of filled groups of online redo log files, which creates archived (offline) redo logs. The archiving of filled groups has two key advantages relating to database backup and recovery options:
The choice of whether or not to enable the archiving of filled groups of online redo log files depends on the availability and reliability requirements of the application running on the database. If you cannot afford to lose any data in your database in the event of a disk failure, you must use ARCHIVELOG mode. However, the archiving of filled online redo log files can require the database administrator to perform extra administrative operations.
Depending on how you configure archiving, the mechanics of archiving redo log groups are performed by either the optional Oracle background process ARCH (when automatic archiving is used) or the user process that issues a SQL statement to archive a group manually.
ARCH can archive a group after the group becomes inactive and the log switch to the next group has completed. The ARCH process can access any members of the group, as needed, to complete the archiving of the group. If ARCH attempts to open or read a member of a group and it is not accessible (for example, due to a disk failure), ARCH automatically tries to use another member of the group, and so on, until it finds a member of the group that is available for archiving. If ARCH is archiving a member of a group, and the information in the member is detected as invalid or a disk failure occurs as archiving proceeds, ARCH automatically switches to another member of the group to continue archiving the group where it was interrupted.
A group of online redo log files does not become available to LGWR for reuse until ARCH has archived the group. This restriction is important because it guarantees that LGWR cannot accidentally write over a group that has not been archived, which would prevent the use of all subsequent archived redo log files during a database recovery.
When archiving is used, an archiving destination is specified by setting the parameter LOG_ARCHIVE_DEST. This destination is usually a storage device separate from the disk drives that hold the datafiles, online redo log files, and control files of the database. Typically, the archiving destination is another disk drive of the database server. This way, archiving does not contend with other files required by the instance and completes quickly so the group can become available to LGWR. Ideally, archived redo log files (and corresponding database backups) should be moved permanently to inexpensive offline storage media, such as tape, that can be stored in a safe place, separate from the database server.
At log switch time, when no more information will be written to a redo log, a record is created in the database's control file. Each record contains the thread number, log sequence number, low SCN for the group, and next SCN after the archived log file; this information is used during database recovery in Parallel Server configurations to automate the application of redo log files.
A record is also created whenever a log is successfully archived. This record contains the name of the archived log as well as the low and high SCN, and log sequence number.
See Also: See Oracle8 Parallel Server Concepts and Administration for additional information.
An archived redo log file is a simple copy of the identical filled members that constitute an online redo log group. Therefore, an archived redo log file includes the redo entries present in the identical members of a group at the time the group was archived. The archived redo log file also preserves the group's log sequence number.
If archiving is enabled, LGWR is not allowed to reuse an online redo log group until it has been archived. Therefore, it is guaranteed that the archived redo log contains a copy of every group (uniquely identified by log sequence numbers) created since archiving was enabled.
It is possible to write out two copies of an online redo log group to archive. Many sites may choose to do this in order to further protect the archived redo log against media failure.
The parameter LOG_ARCHIVE_DUPLEX_DEST determines the second location. Any time a redo log file is archived, it will be archived to both LOG_ARCHIVE_DEST and LOG_ARCHIVE_DUPLEX_DEST.
If set, the parameter LOG_ARCHIVE_MIN_SUCCEED_DEST determines the number of archive log destinations that a redo log group must be successfully archived to. For additional information see the Oracle8 Reference.
A database can operate in two distinct modes: NOARCHIVELOG mode (media recovery disabled) or ARCHIVELOG mode (media recovery enabled).
If a database is used in NOARCHIVELOG mode, the archiving of the online redo log is disabled. Information in the database's control file indicates that filled groups are not required to be archived. Therefore, once a filled group becomes inactive and the checkpoint at the log switch completes, the group is available for reuse by LGWR.
NOARCHIVELOG mode protects a database only from instance failure, not from disk (media) failure. Only the most recent changes made to the database, stored in the groups of the online redo log, are available for instance recovery.
If an Oracle database is operated in ARCHIVELOG mode, the archiving of the online redo log is enabled. Information in a database control file indicates that a group of filled online redo log files cannot be reused by LGWR until the group is archived. A filled group is immediately available to the process performing the archiving once a log switch occurs (when a group becomes inactive); the process performing the archiving does not have to wait for the checkpoint of a log switch to complete before it can access the inactive group for archiving. Figure 2-4 illustrates how the database's online redo log files are used in ARCHIVELOG mode and how the archived redo log is generated by the process archiving the filled groups (for example, ARCH in this illustration).
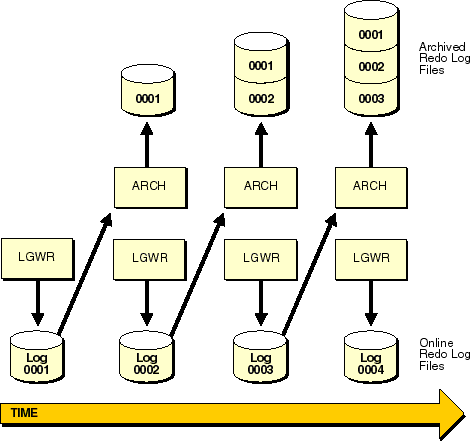
ARCHIVELOG mode permits complete recovery from disk failure as well as instance failure, because all changes made to the database are permanently saved in an archived redo log.
An instance can be configured to have an additional background process, Archiver (ARCH), automatically archive groups of online redo log files once they become inactive. Therefore, automatic archiving frees the database administrator from having to keep track of, and archive, filled groups manually. For this convenience alone, automatic archiving is the choice of most database systems that have an archived redo log.
If you request automatic archiving at instance startup by setting the LOG_ARCHIVE_START initialization parameter, Oracle starts ARCH during instance startup. Otherwise, ARCH is not started during instance startup.
However, the database administrator can interactively start or stop automatic archiving at any time. If automatic archiving was not specified to start at instance startup, and the administrator subsequently starts automatic archiving, the ARCH background process is created. ARCH then remains for the duration of the instance, even if automatic archiving is temporarily turned off and turned on again.
ARCH always archives groups in order, beginning with the lowest sequence number. ARCH automatically archives filled groups as they become inactive. A record of every automatic archival is written in the ARCH trace file by the ARCH process. Each entry shows the time the archive started and stopped. This information is also recorded in the database's control file, and can be viewed by querying the view V$ARCHIVED_LOG.
If ARCH encounters an error when attempting to archive a group (for example, due to an invalid or filled destination), ARCH continues trying to archive the group. An error is also written in the ARCH trace file and the ALERT file. If the problem is not resolved, eventually all online redo log groups become full, yet not archived, and the system halts because no group is available to LGWR. Therefore, if problems are detected, you should either resolve the problem so that ARCH can continue archiving (such as by changing the archive destination) or manually archive groups until the problem is resolved.
If a database is operating in ARCHIVELOG mode, the database administrator can manually archive the filled groups of inactive online redo log files, as necessary, regardless of whether automatic archiving is enabled or disabled. If automatic archiving is disabled, the database administrator is responsible for archiving all filled groups.
For most systems, automatic archiving is chosen because the administrator does not have to watch for a group to become inactive and available for archiving. Furthermore, if automatic archiving is disabled and manual archiving is not performed fast enough, database operation can be suspended temporarily whenever LGWR is forced to wait for an inactive group to become available for reuse.
The manual archiving option is provided so that the database administrator can:
When a group is archived manually, the user process issuing the statement to archive a group actually performs the process of archiving the group. Even if the ARCH background process is present for the associated instance, it is the user process that archives the group of online redo log files.
The control file of a database is a small binary file necessary for the database to start and operate successfully. A control file is updated continuously by Oracle during database use, so it must be available for writing whenever the database is mounted. If for some reason the control file is not accessible, the database will not function properly.
Each control file is associated with only one Oracle database.
A control file contains information about the associated database that is required for the database to be accessed by an instance, both at startup and during normal operation. A control file's information can be modified only by Oracle; no database administrator or end-user can edit a database's control file.
Among other things, a control file contains information such as:
The database name and timestamp originate at database creation. The database's name is taken from either the name specified by the initialization parameter DB_NAME or the name used in the CREATE DATABASE statement.
Each time that a datafile or an online redo log file is added to, renamed in, or dropped from the database, the control file is updated to reflect this physical structure change. These changes are recorded so that:
Therefore, if you make a change to your database's physical structure, you should immediately make a new backup of your control file.
Control files also record information about checkpoints. When a checkpoint starts, the control file records information to remember the next entry that must be entered into the online redo log. This information is used during database recovery to tell Oracle that all redo entries recorded before this point in the online redo log group are not necessary for database recovery; they were already written to the datafiles.
As with online redo log files, Oracle allows multiple, identical control files to be open concurrently and written for the same database. By storing multiple control files for a single database on different disks, you can safeguard against a single point of failure with respect to control files. If a single disk containing a control file crashes, the current instance fails when Oracle attempts to access the damaged control file. However, if the control file is multiplexed, other copies of the current control file are available on different disks. This allows the instance to be restarted easily without the need for database recovery.
The permanent loss of all copies of a database's control file is a serious problem to safeguard against. If any copy of a control file fails during operation, the instance is aborted and media recovery is required. If the control file is not multiplexed, then the recovery procedure will be more complex. Therefore, it is strongly recommended that multiplexed control files be used with each database, with each copy stored on a different physical disk.
This section defines and describes the following types of backups:
Logical Backups, also known as Exports, are described in detail in Oracle8 Utilities.
A whole database backup contains the control file, and all database files which belong to that database. Whole database backups are the most common type of backups performed by database administrators. Before performing whole database backups (or any other type of backup), you should first be familiar with your enterprise's backup strategy. Specifically, you should be aware of the implications of backing up when in ARCHIVELOG mode and NOARCHIVELOG mode
During a whole database backup, all datafiles and control files belonging to that database are backed up (you should not need to back up the online redo logs).
Whole database backups do not require the database to be operated in a specific archiving mode; they can be taken whether a database is operating in ARCHIVELOG or NOARCHIVELOG mode.
If the database is in ARCHIVELOG mode, you can choose to back up the database while it is open or closed. A database running in NOARCHIVELOG mode should only be backed up when it is closed by a clean shutdown (for example, a shutdown using the immediate or normal options). A backup of a database running in NOARCHIVELOG mode and not shutdown cleanly is useless. In such cases, the backed up files are inconsistent with respect to a point-in-time, and because the database is in NOARCHIVELOG mode, there are no logs available to make the database consistent. Recovery Manager does not allow you to back up a database that has been running in NOARCHIVELOG mode and shutdown abnormally, because the backup is not usable for recovery.
You should always back up the parameter files associated with the database, as well as the instance's password file (if the instance uses password files) whenever they are modified.
There are two types of whole database backups: consistent and inconsistent.
A consistent whole database backup is a backup where all files (datafiles and control files) are consistent to the same point in time (for example, checkpointed at the same SCN). The only tablespaces in a consistent backup that are allowed to have older timestamps (SCNs) are read-only and offline normal tablespaces, which are still consistent with the other datafiles in the backup.
You can open the set of files resulting from a consistent whole database backup without applying redo logs because the data is already consistent; no action is required to make the data in the restored datafiles correct.
A consistent whole database backup is the only valid backup option for databases running in NOARCHIVELOG mode. The only way to take a consistent whole database backup is to shut down the database cleanly and take the backup while the database is closed.
To make a consistent database backup current (or to take it to a later point in time) you will either need to apply redo to it, or, if you are using Recovery Manager to perform your backups, you may have the option of applying a combination of incremental backups and redo. The redo is located in the archived logs, and the online logs (if you are recovering to the current time).
If a database is not shut down cleanly (for example, an instance failure occurred, or a SHUTDOWN ABORT statement was issued), the database's datafiles will most likely be inconsistent.
If you are in a situation where your database must be up and running 24 hours a day, 7 days a week, you will need to perform inconsistent whole database backups. A backup of an open database is inconsistent because portions of the database (hence, datafiles in the database) are being modified and written to disk while the backup is progressing. The database must be in ARCHIVELOG mode to be able to perform open backups.
Deciding whether or not to perform an open backup depends only upon the availability requirements of your data-open backups are the only choice if the data being backed up must always be available.
Inconsistent backups are also created if a database is backed up after a system crash failure or shutdown abort. This type of backup is valid if the database is running in ARCHIVELOG mode, because all logs are available to make the backup consistent.
After open (also called "hot") or inconsistent closed backups, you should always archive the current online log file. Archive the current online log by issuing the SQL command ALTER SYSTEM ARCHIVE ALL. After archiving the current log file, back up all archivelogs produced since the backup began; this ensures that you can use the backup. If you do not have all archived logs produced during the backup, the backup cannot be recovered (because you do not have all the logs necessary to make the it consistent).
Unless you are taking a consistent whole database backup, you should back up your control file using the ALTER DATABASE command with the BACKUP CONTROLFILE option. A database must be consistent before it can be opened. Inconsistent whole database backups are made consistent by applying incremental backups and redo logs (archived and online).
A tablespace backup is a backup of a subset of the database.
Tablespace backups are only valid if the database is operating in ARCHIVELOG mode. The only time a tablespace backup is valid for a database running in NOARCHIVELOG mode is when that tablespace (and all datafiles in that tablespace), is read-only or offline-normal.
A datafile backup is a backup of a single datafile. Database administrators usually take tablespace backups rather than datafile backups, because the tablespace is a logical unit of a database to back up.
Datafile backups are only valid if the database is operating in ARCHIVELOG mode. The only time a datafile backup is valid for a database running in NOARCHIVELOG mode is if that datafile is the only file in a tablespace. For example, the backup is a tablespace backup, but the tablespace only contains one file and is read-only or offline-normal.
A control file backup is a backup of a database's control file. If the database is open you can issue the following statement:
ALTER DATABASE BACKUP CONTROLFILE to `location';
You can also use Recovery Manager to back up the control file.
If you are going to take an O/S backup of the control file, you must shut down the database first.
If a database is operating in ARCHIVELOG mode, online logs are archived to the LOG_ARCHIVE_DEST, from where they are typically backed up to tertiary storage (such as magnetic tape).
Some sites require very fast recovery times, so they may make a copies of their archivelogs to another disk filesystem, as well as to tertiary storage. You can set the parameter LOG_ARCHIVE_DUPLEX_DEST so that it will archive a second copy of each online log to this location. The on-disk archivelog copies are typically kept for a short time (for example, 48 hours) before being deleted.
See Also: "Duplexing the Archived Redo Log".
The frequency of archivelog backups depends on:
The best way to back up the contents of the current online log is to archive it, then back up the archived log.
Oracle recommends you do not copy a current online log, because when you do so, and then restore that copy, the copy will appear as the end of the redo thread. However, additional redo may have been generated in the thread. If you ever attempt to execute recovery supplying the redo log copy, recovery will erroneously detect the end of the redo thread and prematurely terminate, possibly corrupting the database.
Each of the backup types described in the preceding sections can be made in the following formats:
Backup sets are created using the Recovery Manager backup command, and can contain either archive logs or datafiles, but not both.
An Oracle server process reads the datafiles being backed up and creates the backup set. This is why backup sets of open database files (made by Recovery Manager) do not need to be preceded by the ALTER TABLESPACE BEGIN BACKUP statement.
For additional information see "Fractured Block Detection During Open Database Backups in Recovery Manager".
Backup sets are written out in an Oracle proprietary format. Files in a backup set cannot be used by an Oracle instance until they are restored to an instance-usable (usually datafile) format by Recovery Manager. For example, a tablespace backup in a backup set is a compressed version of each file in the tablespace and the Recovery Manager command restores the datafiles from the backup set to an instance-usable format.
You can back up any logical unit of an Oracle database in a backup set:
You can also direct Recovery Manager to include a control file backup in any datafile backup set.
A datafile copy is created using the Recovery Manager copy command.
An Oracle server process reads the datafile and writes the copy out to disk, not an O/S routine. This is why datafile copies of open database files (made by Recovery Manager) do not need to be preceded by the ALTER TABLESPACE BEGIN BACKUP statement.
See Also: "Fractured Block Detection During Open Database Backups in Recovery Manager".
Datafile copies can be used immediately by an Oracle instance--they are already in an instance-usable (usual datafile) format.
Operating system (O/S) backups are created using an operating system command. O/S backups can be written to disk or tape in any format that your O/S utilities support.
Recovery Manager can catalog and use O/S backups that are image backups on disk.
Logical backups store information about the schema objects created for a database. You can use the Export utility to write data from an Oracle database to operating system files that have an Oracle database format.
Because the Oracle Export utility can selectively export specific objects or portions of an object (for example, partitioned tables), you might consider exporting portions or all of a database for supplemental protection and flexibility in a database's backup strategy. Database exports are not a substitute for physical backups and cannot provide the same complete recovery advantages that the built-in functionality of Oracle offers.
See Also: For more information about the Export Utility, see the Oracle Server Utilities Guide.