Release 8.0
A58238-01
Library |
Product |
Contents |
Index |
| Oracle8 Parallel Server Concepts & Administration Release 8.0 A58238-01 |
|
![]()
![]()
This chapter explains space management concepts:
See Also: Chapter 17, "Using Free List Groups to Partition Data", for a description of space management procedures.
This section provides an overview of how Oracle handles free space. It contains the following sections:
Oracle Parallel Server enables transactions running on separate instances to insert and update data in the same table concurrently, without contention to locate free space for new records.
To take advantage of this capability, you must actively manage free space in your database using several structures which are defined in this chapter.
For each database object (a table, cluster, or index), Oracle keeps track of blocks with space available for inserts (or for updates which may cause rows to exceed space available in their original block). A user process that needs free space can look in the master free list of blocks that contain free space. If the master free list does not contain a block with enough space to accommodate the user process, Oracle allocates a new extent.
New extents that are automatically allocated to a table add their blocks to the master free list. This can eventually result in contention for free space among multiple instances on a parallel server because the free space contained in automatically allocated extents cannot be reallocated to any group of free lists. You can have more control over free space if you specifically allocate extents to instances; in this way you can minimize contention for free space.
This section describes basic structures of database storage:
A segment is a unit of logical database storage. Oracle allocates space for segments in smaller units called extents. An extent is a specific number of contiguous data blocks allocated for storing a specific type of information.
A segment thus comprises a set of extents allocated for a specific type of data structure. For example, each table's data is stored in its own data segment, while each index's data is stored in its own index segment.
The extents of a segment are all stored in the same tablespace; they may or may not be contiguous on disk. The segments can span files, but individual extents cannot.
Note that although you can allocate additional extents, the blocks themselves are allocated separately. If you allocate an extent to a specific instance, the blocks are immediately allocated to the free list. However, if the extent is not allocated to a specific instance, then the blocks themselves are allocated only when the high water mark moves.
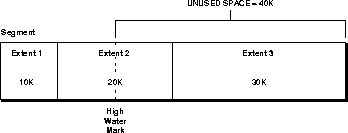
The high water mark is the boundary between used and unused space in a segment. As requests are received for new free blocks (which cannot be satisfied by existing free lists), the block to which the high water mark points becomes a used block, and the high water mark is advanced to the next block. In other words, the segment space to the left of the high water mark is used, and the space to the right of it is unused.
Figure 11-2 shows a segment which consists of three extents containing 10K, 20K, and 30K of space, respectively. The high water mark is in the middle of the second extent, thus the segment contains 20K of used space (to the left of the high water mark), and 40K of unused space (to the right of the high water mark.
See Also: Oracle8 Concepts for further information about segments and extents.
Oracle uses the following structures to manage free space:
Process free lists are used to relieve contention for free space among processes inside the instance, even if multiple instances can hash to a single free list group. Free list groups are used to relieve forced reads/writes between instances. Process free lists and free list groups are supported on all database objects alike: tables, indexes, and clusters.
A transaction free list is a list of blocks made free by uncommitted transactions. They exist by default.
When transactions are committed, the freed blocks eventually go to the master free list (described below).
A process free list (also termed simply a "free list" in this documentation) is a list of free data blocks that can be drawn from a number of different extents within the segment.
Blocks in free lists contain free space greater than PCTFREE (the percentage of a block to be reserved for updates to existing rows). In general, blocks included in process free lists for a database object must satisfy the PCTFREE and PCTUSED constraints described in the chapter "Data Blocks, Extents, and Segments" in Oracle8 Concepts.
Process free lists must be specifically enabled by the user. You can specify the number of process free lists desired by setting the FREELISTS parameter when you create a table, index or cluster. The maximum value of the FREELISTS parameter depends on the Oracle block size on your system. In addition, for each free list, you need to store a certain number of bytes in a block to handle overhead.
Note: The reserved area and the number of bytes required per free list depend upon your platform. For more information, see your Oracle system-specific documentation.
A free list group is a set of free lists you can specify for use by one or more particular instances. Each free list group provides free data blocks to accommodate inserts or updates on tables and clusters, and is associated with instance(s) at startup.
A parallel server has multiple instances, and process free lists alone cannot solve the problem of contention. Free list groups, however, effectively reduce pinging between instances.
When enabled, free list groups divide the set of free lists into subsets. Descriptions of process free lists are stored in separate blocks for the different free list groups. Each free list group block points to the same free lists, except that every instance gets its own. (Or, in the case of more instances than free list groups, multiple instances hash into the same free list group.) This ensures that the instances do not compete for the same blocks
Attention: In Oracle Parallel Server, you should always use free list groups, along with process free lists.
The master free list is a repository of blocks which contain available space, drawn from any extent in the table. It exists by default, and includes:
If free list groups exist, each group has its own master free list. There is, in addition, a central master free list which is mostly used for parallel operations.
A highly concurrent environment has potential contention for the segment header, which contains the master free list.
In a single instance environment, multiple process free lists help to solve the problem of many users seeking free data blocks by easing contention on segment header blocks.
In a multi-instance environment, as illustrated in Figure 11-3, process free lists provide free data blocks from available extents to different instances. You can partition multiple free lists so that extents are allocated to specific database instances. Each instance hashes to one or more free list groups, and each group's header block points to process free lists.
If no free list groups are allocated, however, the segment header block of a file points to the process free lists. Without free list groups, every instance must read the segment header block in order to access the free lists.
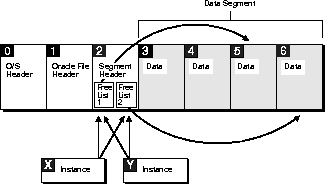
Figure 11-4 shows the blocks of a file in which the master free list is stored in the segment header block. Three instances are forced to read this block in their effort to obtain free space. Because there is only one free list, there is only one insertion point. Process free lists can help to reduce this contention by spreading this insertion point over multiple blocks, each of which will be accessed less often.
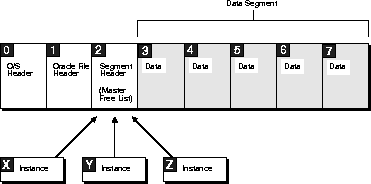
Figure 11-5 illustrates the division of free space for a table into a master free list and two free list groups, each of which contains three free lists. This example concerns a well-partitioned application in which deletes occur. The master free list pictured is the master free list for this particular free list group.
The table was created with one initial extent, after which extents 2 and 5 were allocated to instance X, extents 3 and 4 were allocated to instance Y, and extent 6 was allocated automatically (not to a particular instance). Notice the following:
Each user process running on instance X uses one of the free lists in group X, and each user process on instance Y uses one of the free lists in group Y. If more instances start up, their user processes share free lists with instance X or Y.
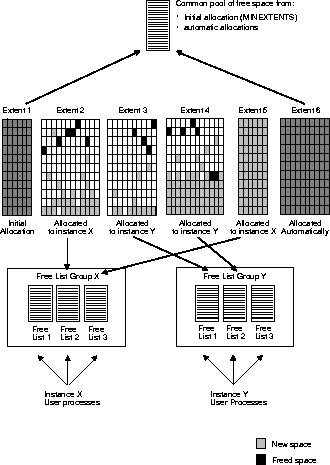
The simple case in Figure 11-5 becomes more complicated when you consider that extents are not allocated to instances permanently, and that space allocated to one instance cannot be used by another instance. Each free list group has its own master free list. After allocation, some blocks go onto the master free list for the group, some to a process free list, and some do not belong to a free list. If the application is totally partitioned, then once blocks are allocated to a given instance, they stay with that instance. However, blocks can move from one instance to another if the application is not totally partitioned.
Consider a situation in which instance Y fills a block, takes it off the free list, and then instance X frees the block. The block then goes to the free list of instance X, the instance which freed it. If instance Y needs space, it cannot reclaim this block. Instance Y can only obtain free space from its own free list group.
Several SQL options enable you to allocate process free lists and free list groups for tables, clusters, and indexes. You can explicitly specify that new space for an object be taken from a specific datafile. You can also associate free space with particular free list groups, which can then be associated with particular instances.
The SQL statements include:
CREATE TABLE [CLUSTER, INDEX]
ALTER TABLE [CLUSTER, INDEX]
You can use these SQL options with the initialization parameter INSTANCE_NUMBER to associate data blocks with instances.
See Also: Oracle8 SQL Reference for complete syntax of these statements.
This section describes:
You can partition free space for individual tables, clusters (other than hash clusters), and indexes into multiple process free lists. Multiple free lists allow a process to search a specific pool of blocks when space is needed, thus reducing contention among users for free space. Within an instance, using free lists can reduce contention if multiple processes are inserting into the same table.
Each table has a master free list of blocks with available space, and can also contain multiple free lists. Before looking in the master free list, a user process scans the appropriate free list to locate a block that contains enough space.
The separation of free space into groups can improve performance by reducing contention for free data blocks during concurrent inserting by multiple instances on a parallel server. You can thus create groups of process free lists for a parallel server, each of which can contain multiple free lists for a table, index, or cluster. You can use free list groups to partition data by allocating extents to particular instances.
In general, all tables should have the same number of free list groups, but the number of free lists within a group may vary, depending on the type and amount of activity of each table.
Partitioning free space can particularly improve the performance of applications that have a high volume of concurrent inserts, or updates requiring new space, from multiple instances. Performance improvements also depend, of course, on your operating system, hardware, data block size, and so on.
Note: In a multi-instance environment, information about multiple free lists and free list groups is not preserved upon import. If you use Export and Import to back up and restore your data, it will be difficult to import the data so that it is partitioned again.
Figure 11-6 illustrates the way in which free lists and free list groups are assigned to instances.
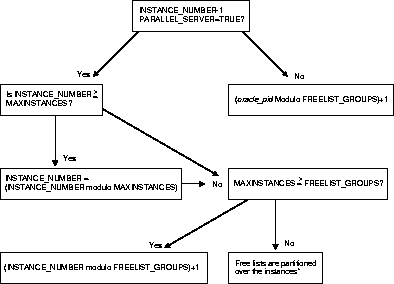
Note: Using the statement ALTER SESSION INSTANCE_NUMBER you can alter the instance number to be larger than the value of MAXINSTANCES. The figure shows how this possibility is taken into account: for the purposes of the internal calculation whereby free list groups are assigned, the instance number is brought back within the boundaries of MAXINSTANCES.
* Free lists are partitioned as follows: If there are 3 instances and 35 free list groups, then instance 1 will handle the first twelve free list groups, instance 2 the next twelve, and instance 3 the remaining eleven. The actual free list group block is determined by hashing oracle_pid by the number of free list groups.
This section describes:
A table can have separate groups of process free lists that are assigned to particular instances. Each group of free lists can be associated with a single instance, or several instances can share one group of free lists. All instances also have access to the master free list of available space.
Groups of free lists allow you to associate instances with different sets of data blocks for concurrent inserts and updates requiring new space. This reduces contention for the segment header block, which contains information about the master free list of free blocks. For tables that do not have multiple free list groups, the segment header also contains information about free lists for user processes. You can use free list groups to locate the data that an instance inserts and accesses frequently in extents allocated to that instance.
Data partitioning can reduce contention for data blocks. Often the PCM locks that cover blocks in one free list group tend to be held primarily by the instance using that free list group, because an instance that modifies data is usually more likely to reuse that data than other instances. However, if multiple instances take free space from the same extent, they are more likely to contend for blocks in that extent if they subsequently modify the data that they inserted.
If MAXINSTANCES is greater than the number of free list groups in the table or cluster, then an instance number maps to the free list group associated with:
instance_number modulo number_of_free_list_groups
Note: "Modulo" (or "rem" for "remainder") is a formula for determining which free list group should be used by calculating a remainder value. In the following example there are 2 free list groups and 10 instances. To determine which free list group instance 6 will use, the formula would read 6 modulo 2 = 0. Six divided by 2 is 3 with zero remainder, so instance 6 will use free list group 0. Similarly, instance 5 would use free list group 1 because 5 modulo 2 = 1. Five is divisible by 2 with a remainder of 1.
If there are more free list groups than MAXINSTANCES, then a different hashing mechanism is used.
If multiple instances share one free list group, they share access to every extent specifically allocated to any instance sharing that free list group.
In a system with relatively few nodes, such as a clustered system, the FREELIST GROUPS option for a table should generally have the same value as the MAXINSTANCES option of CREATE DATABASE, which limits the number of instances that can access a database concurrently.
In a massively parallel system, however, MAXINSTANCES could be many times larger than FREELIST GROUPS so that many instances share one group of free lists.
See Also: "Associating Instances, Users, and Locks with Free List Groups" on page 17-9.
User processes are associated with process free lists based on their Oracle process IDs. Each user process has access to only one free list in the free list group for the instance on which it is running. Every user process also has access to the master free list of free blocks.
If a table has multiple free lists but does not have multiple free list groups, or has fewer free list groups than the number of instances, then each free list is shared by user processes from different instances.
If each extent in the table is in a separate datafile, you can use the GC_FILES_TO_LOCKS parameter to allocate specific ranges of PCM locks to each extent, so that each set of PCM locks is associated with only one group of free lists.
Figure 11-7 shows multiple extents in separate files. The GC_FILES_TO_LOCKS parameter allocates 10 locks to files 8 and 10, and 10 locks to files 9 and 11. Extents A and C are in the same free list group, and extents B and D are in another free list group. One set of PCM locks is associated with files 8 and 10, and a different set of PCM locks is associated with files 9 and 11. You do not need separate locks for files which are in the same free list group (such as files 8 and 10, or files 9 and 11).
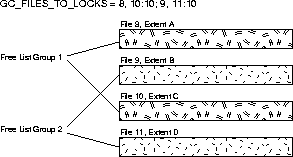
This example assumes total partitioning for reads as well as for writes. If more than one instance is to update blocks, then it would still be desirable to have more than one lock per file in order to minimize forced reads and writes. This is because even with a shared lock, all blocks held by a lock are subject to forced reads when another instance tries to read even one of the locked blocks.
See Also: "Setting GC_FILES_TO_LOCKS: PCM Locks for Each Datafile" on page 15-7.
This section covers the following topics:
When a row is inserted into a table and new extents need to be allocated, a certain number of contiguous blocks (specified with !blocks in the GC_FILES_TO_LOCKS parameter) are allocated to the free list group associated with an instance. Extents allocated when the table or cluster is first created and new extents that are automatically allocated add their blocks to the master free list (space above the high water mark).
When a user explicitly allocates an extent without specifying an instance, or when an extent is automatically allocated to a segment because the system is running out of space (the high water mark cannot be advanced any more), the new extent becomes part of the unused space. It is placed at the end of the extent map, which means that the current high water mark is now in an extent "to the left" of the new one. The new extent is thus added "above" the high water mark.
You have two options for controlling the allocation of new extents.
Pre-allocating extents is a static approach to the problem of preventing automatic allocation of extents by Oracle. You can pre-allocate extents to tables that have free list groups. This means that all the free blocks will be formatted into free lists, which will reside in the free list group of the instance to which you are pre-allocating the extent. This approach is useful if you need to partition data so as to greatly reduce all pinging on insert, or if you need to accommodate objects which you expect will grow.
Note: False pinging will not be eliminated.
See Also: "Pre-allocating Extents (Optional)" on page 17-10.
If you primarily need to accommodate growth, the strategy of dynamically allocating blocks to free list groups would be more effective than pre-allocation of extents. You can use the !blocks option of GC_FILES_TO_LOCKS to dynamically allocate blocks to a free list from the high water mark within a lock boundary. This method does not eliminate all pinging on the segment header-- rather, it allocates blocks on the fly so that you do not have to pre-allocate extents.
Remember that locks are owned by instances. Blocks are allocated on a per-instance basis--and that is why they are allocated to free list groups. Within an instance, blocks can be allocated to different free lists.
Using this method, you can either explicitly allocate the !blocks value, or else leave the balance of new blocks still covered by the existing PCM lock. If you choose the latter, remember that there still may be contention for the existing PCM lock by allocation to other instances. If the PCM lock covers multiple groups of blocks, there may still be unnecessary forced reads and writes of all the blocks covered by the lock.
See Also: "Dynamically Allocating Extents" on page 17-14.
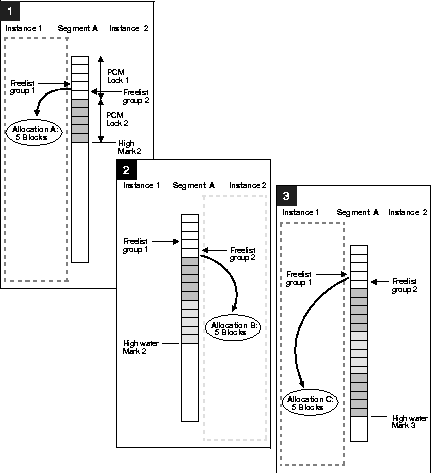
A segment's high water mark is the current limit to the number of blocks that have been allocated within the segment. If you are allocating extents dynamically, the high water mark is also the lock boundary. The lock boundary and the number of blocks which will be allocated at one time within an extent must coincide. This value must be the same for all instances.
Consider the following example, in which there are 4 blocks per lock (!4). Locks have been allocated before the block content has been entered. If we have filled datablock D2, held by Lock 2, and then allocate another range of 4 blocks, only the number of blocks which fits within the lock boundary will actually be allocated: in this case, blocks 7 and 8. Both of these are protected by your current lock. With the high water mark at 8, when instance 2 allocates a range of blocks, all four blocks 9 to 12 are allocated, covered by lock 3. The next time instance 1 allocates blocks it will get blocks 13 to 16, covered by lock 4.
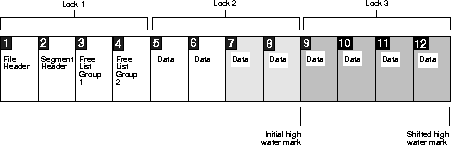
The example in this section assumes that GC_FILES_TO_LOCKS has the following setting for both instances:
GC_FILES_TO_LOCKS = "1000!5"
With the EACH option specified, each file in file_list is allocated #locks number of PCM locks. Within each file, !blocks specifies the number of contiguous data blocks to be covered by each lock.
Figure 11-9 shows the incremental process by which the segment grows:
In this way, if user A on Instance 1 is working on block 10, no one else from either instance can work on any block in the range of blocks that are covered by Lock 2 (that is, blocks 6 through 10).