| Oracle® Database Globalization Support Guide 10g Release 1 (10.1) Part Number B10749-01 |
|





|
View PDF |
| Oracle® Database Globalization Support Guide 10g Release 1 (10.1) Part Number B10749-01 |
|
|
View PDF |
This chapter discusses character set conversion and character set migration. It includes the following topics:
Choosing the appropriate character set for your database is an important decision. When you choose the database character set, consider the following factors:
A related topic is choosing a new character set for an existing database. Changing the database character set for an existing database is called character set migration. When you migrate from one database character set to another you must choose an appropriate character set. You should also plan to minimize data loss from the following sources:
When the database is created using byte semantics, the sizes of the CHAR and VARCHAR2 datatypes are specified in bytes, not characters. For example, the specification CHAR(20) in a table definition allows 20 bytes for storing character data. When the database character set uses a single-byte character encoding scheme, no data loss occurs when characters are stored because the number of characters is equivalent to the number of bytes. If the database character set uses a multibyte character set, then the number of bytes no longer equals the number of characters because a character can consist of one or more bytes.
During migration to a new character set, it is important to verify the column widths of existing CHAR and VARCHAR2 columns because they may need to be extended to support an encoding that requires multibyte storage. Truncation of data can occur if conversion causes expansion of data.
Table 11-1 shows an example of data expansion when single-byte characters become multibyte characters through conversion.
| Character | WE8MSWIN 1252 Encoding | AL32UTF8 Encoding |
|---|---|---|
|
ä |
E4 |
C3 A4 |
|
ö |
F6 |
C3 B6 |
|
© |
A9 |
C2 A9 |
|
€ |
80 |
E2 82 AC |
The first column of Table 11-1 shows selected characters. The second column shows the hexadecimal representation of the characters in the WE8MSWIN1252 character set. The third column shows the hexadecimal representation of each character in the AL32UTF8 character set. Each pair of letters and numbers represents one byte. For example, ä (a with an umlaut) is a single-byte character (E4) in WE8MSWIN1252, but it becomes a two-byte character (C3 A4) in AL32UTF8. Also, the encoding for the euro symbol expands from one byte (80) to three bytes (E2 82 AC).
If the data in the new character set requires storage that is greater than the supported byte size of the datatypes, then you need to change your schema. You may need to use CLOB columns.
Data truncation can cause the following problems:
scött (o with an umlaut) changes from 5 bytes to 6 bytes. In AL32UTF8, scött can no longer log in because of the difference in the username. Oracle Corporation recommends that usernames and passwords be based on ASCII characters. If they are not, then you must reset the affected usernames and passwords after migrating to a new character set
CHAR data contains characters that expand after migration to a new character set, space padding is not removed during database export by default. This means that these rows will be rejected upon import into the database with the new character set. The workaround is to set the BLANK_TRIMMING initialization parameter to TRUE before importing the CHAR data.
| See Also:
Oracle Database Reference for more information about the |
This section includes the following topics:
The Export and Import utilities can convert character sets from the original database character set to the new database character set. However, character set conversions can sometimes cause data loss or data corruption. For example, if you are migrating from character set A to character set B, then the destination character set B should be a superset of character set A. The destination character, B, is a superset if it contains all the characters defined in character set A. Characters that are not available in character set B are converted to replacement characters, which are often specified as ? or ¿ or as a character that is related to the unavailable character. For example, ä (a with an umlaut) can be replaced by a. Replacement characters are defined by the target character set.
Figure 11-1 shows an example of a character set conversion in which the copyright and euro symbols are converted to ? and ä is converted to a.
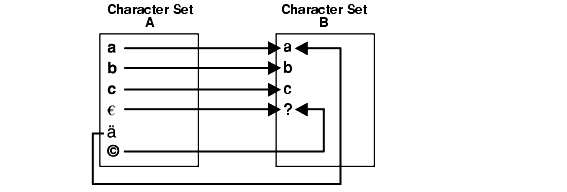
Text description of the illustration nlspg020.gif
To reduce the risk of losing data, choose a destination character set with a similar character repertoire. Migrating to Unicode can be an attractive option because AL32UTF8 contains characters from most legacy character sets.
Another character set migration scenario that can cause the loss of data is migrating a database that contains invalid data. Invalid data usually occurs in a database because the NLS_LANG parameter is not set properly on the client. The NLS_LANG value should reflect the client operating system code page. For example, in an English Windows environment, the code page is WE8MSWIN1252. When the NLS_LANG parameter is set properly, the database can automatically convert incoming data from the client operating system. When the NLS_LANG parameter is not set properly, then the data coming into the database is not converted properly. For example, suppose that the database character set is AL32UTF8, the client is an English Windows operating system, and the NLS_LANG setting on the client is AL32UTF8. Data coming into the database is encoded in WE8MSWIN1252 and is not converted to AL32UTF8 data because the NLS_LANG setting on the client matches the database character set. Thus Oracle assumes that no conversion is necessary, and invalid data is entered into the database.
This can lead to two possible data inconsistency problems. One problem occurs when a database contains data from a character set that is different from the database character set but the same code points exist in both character sets. For example, if the database character set is WE8ISO8859P1 and the NLS_LANG setting of the Chinese Windows NT client is SIMPLIFIED CHINESE_CHINA.WE8ISO8859P1, then all multibyte Chinese data (from the ZHS16GBK character set) is stored as multiples of single-byte WE8ISO8859P1 data. This means that Oracle treats these characters as single-byte WE8ISO8859P1 characters. Hence all SQL string manipulation functions such as SUBSTR or LENGTH are based on bytes rather than characters. All bytes constituting ZHS16GBK data are legal WE8ISO8859P1 codes. If such a database is migrated to another character set such as AL32UTF8, then character codes are converted as if they were in WE8ISO8859P1. This way, each of the two bytes of a ZHS16GBK character are converted separately, yielding meaningless values in AL32UTF8. Figure 11-2 shows an example of this incorrect character set replacement.
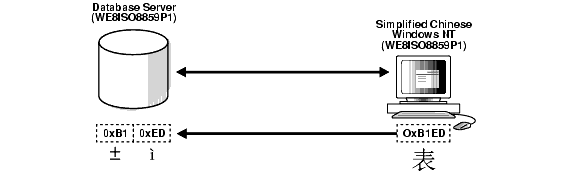
Text description of the illustration nlspg021.gif
The second possible problem is having data from mixed character sets inside the database. For example, if the data character set is WE8MSWIN1252, and two separate Windows clients using German and Greek are both using WE8MSWIN1252 as the NLS_LANG character set, then the database contains a mixture of German and Greek characters. Figure 11-3 shows how different clients can use different character sets in the same database.
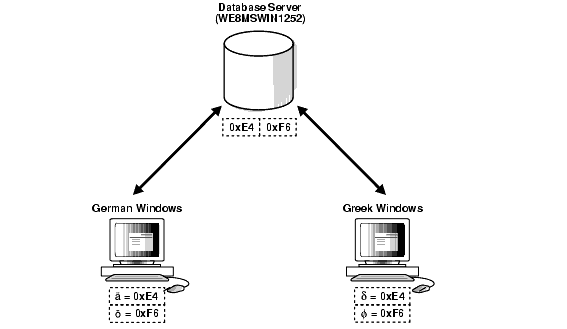
Text description of the illustration nlspg022.gif
For database character set migration to be successful, both of these cases require manual intervention because Oracle cannot determine the character sets of the data being stored.Incorrect data conversion can lead to data corruption, so perform a full backup of the database before attempting to migrate the data to a new character set.
Database character set migration has two stages: data scanning and data conversion. Before you change the database character set, you need to identify possible database character set conversion problems and truncation of data. This step is called data scanning.
Data scanning identifies the amount of effort required to migrate data into the new character encoding scheme before changing the database character set. Some examples of what may be found during a data scan are the number of schema objects where the column widths need to be expanded and the extent of the data that does not exist in the target character repertoire. This information helps to determine the best approach for converting the database character set.
Incorrect data conversion can lead to data corruption, so perform a full backup of the database before attempting to migrate the data to a new character set.
There are three approaches to converting data from one database character set to another if the database does not contain any of the inconsistencies described in "Character Set Conversion Issues". A description of methods to migrate databases with such inconsistencies is out of the scope of this documentation. For more information, contact Oracle Consulting Services for assistance.
The approaches are:
| See Also:
Chapter 12, "Character Set Scanner Utilities" for more information about data scanning |
In most cases, a full export and import is recommended to properly convert all data to a new character set. It is important to be aware of data truncation issues, because columns with character datatypes may need to be extended before the import to handle an increase in size. Existing PL/SQL code should be reviewed to ensure that all byte-based SQL functions such as LENGTHB, SUBSTRB, and INSTRB, and PL/SQL CHAR and VARCHAR2 declarations are still valid.
| See Also:
Oracle Database Utilities for more information about the Export and Import utilities |
The CSALTER script is part of the Database Character Set Scanner utility. The CSALTER script is the most straightforward way to migrate a character set, but it can be used only under special circumstances: the database character set itself and all of its schema data must be a strict subset of the new character set. The new character set is a strict superset of the current character set if:
With the strict superset criteria in mind, only the metadata is converted to the new character set by the CSALTER script, with the following exception: the CSALTER script performs data conversion only on CLOB columns in the data dictionary and sample schemas that have been created by Oracle. CLOB columns that users have created may need to be handled separately. Beginning with Oracle9i, some internal fields in the data dictionary and sample schemas are stored in CLOB columns. Customers may also store data in CLOB fields. When the database character set is multibyte, then CLOB data is stored in a format that is compatible with UCS-2 data. When the database character set is single-byte, then CLOB data is stored using the database character set. Because the CSALTER script converts data only in CLOB columns in the data dictionary and sample schemas that were created by Oracle, any other CLOB columns that are created must be first exported and then dropped from the schema before the CSALTER script can be run.
To change the database character set, perform the following steps:
SHUTDOWN IMMEDIATE or a SHUTDOWN NORMAL statement.CSALTER script cannot be rolled back.CSSCAN /AS SYSDBA FULL=Y...
CSALTER script.
@@CSALTER.PLB NORMAL SHUTDOWN IMMEDIATE; -- or SHUTDOWN NORMAL; STARTUP;
See Also:
|
In an Oracle Real Application Clusters environment, ensure that no other Oracle background processes are running, with the exception of the background processes associated with the instance through which a user is connected, before attempting to issue the CSALTER script. With DBA privileges, use the following SQL statement to verify that no other Oracle background processes are running:
SELECT SID, SERIAL#, PROGRAM FROM V$SESSION;
Set the CLUSTER_DATABASE initialization parameter to FALSE to allow the character set change to be completed. Reset it to TRUE after the character set has been changed.
Another approach to migrating character data is to perform selective exports followed by rescanning and running the CSALTER script. This approach is most common when the subset character set is single-byte and the migration is to a multibyte character set. In this scenario, user-created CLOBs must be converted because the encoding changes from the single- byte character set to a UCS-2-compatible format which Oracle uses for storage of CLOBs regardless of the multibyte encoding. The Database Character Set Scanner identifies these columns as convertible. It is up to the user to export these columns and then drop them from the schema, rescan, and, if the remaining data is clean, run the CSALTER script. When these steps have been completed, then import the CLOB columns to the database to complete migration.
Beginning with Oracle9i, data that is stored in columns of the NCHAR datatypes is stored exclusively in a Unicode encoding regardless of the database character set. This allows users to store Unicode in a database that does not use Unicode as the database character set.
This section includes the following topics:
In the version 8 database, Oracle introduced a national character datatype (NCHAR) that allows a second, alternate character set in addition to the database character set. The NCHAR datatypes support several fixed-width Asian character sets that were introduced to provide better performance when processing Asian character data.
Beginning with Oracle9i, the SQL NCHAR datatypes are limited to Unicode character set encoding (UTF8 and AL16UTF16). Any other version 8 character sets that were available for the NCHAR datatype, including Asian character sets such as JA16SJISFIXED are no longer supported.
The steps for migrating existing NCHAR, NVARCHAR2, and NCLOB columns to NCHAR datatypes in Oracle9i and later are as follows:
NCHAR columns from the version 8 or Oracle8i database.NCHAR columns.NCHAR columns into the upgraded database.The migration utility can also convert version 8 and Oracle8i NCHAR columns to NCHAR columns in later releases. A SQL NCHAR upgrade script called utlnchar.sql is supplied with the migration utility. Run it at the end of the database migration to convert version 8 and Oracle8i NCHAR columns to the NCHAR columns in later releases. After the script has been executed, the data cannot be downgraded. The only way to move back to version 8 or Oracle8i is to drop all NCHAR columns, downgrade the database, and import the old NCHAR data from a previous version 8 or Oracle8i export file. Ensure that you have a backup (export file) of version 8 or Oracle8i NCHAR data, in case you need to downgrade your database in the future.
See Also:
|
To change the national character set, use the ALTER DATABASE NATIONAL CHARACTER SET statement. The syntax of the statement is as follows:
ALTER DATABASE [db_name] NATIONAL CHARACTER SET new_NCHAR_character_set;
db_name is optional. The character set name should be specified without quotes.
You can issue the ALTER DATABASE CHARACTER SET and ALTER DATABASE NATIONAL CHARACTER SET statements together if desired.
You can use the n_switch.sql script, located in $ORACLE_HOME/rdbms/admin, to convert the national character set between UTF8 and AL16UTF16. Run it in RESTRICTED mode.
| See Also:
Oracle Database SQL Reference for the syntax of the |
You can change a column's datatype definition using the following methods:
The ALTER TABLE MODIFY statement has the following advantages over online table redefinition:
Online table redefinition has the following advantages over the ALTER TABLE MODIFY statement:
CLOB datatype to the NCLOB datatypeThis section contains the following topics:
The ALTER TABLE MODIFY statement can be used to change table column definitions from the CHAR datatypes to NCHAR datatypes. It also converts all of the data in the column from the database character set to the NCHAR character set. The syntax of the ALTER TABLE MODIFY statement is as follows:
ALTER TABLE table_name MODIFY (column_name datatype);
If indexes have been built on the migrating column, then dropping the indexes can improve the performance of the ALTER TABLE MODIFY statement because indexes are updated when each row is updated.
The maximum column lengths for NCHAR and NVARCHAR2 columns are 2000 and 4000 bytes. When the NCHAR character set is AL16UTF16, the maximum column lengths for NCHAR and NVARCHAR2 columns are 1000 and 2000 characters, which are 2000 and 4000 bytes. If this size limit is violated during migration, then consider changing the column to the NCLOB datatype instead.
|
Note:
|
It takes significant time to migrate a large table with a large number of rows to Unicode datatypes. During the migration, the column data is unavailable for both reading and updating. Online table redefinition can significantly reduce migration time. Using online table redefinition also allows the table to be accessible to DML during most of the migration time.
Perform the following tasks to migrate a table to Unicode datatypes using online table redefinition:
DBMS_REDEFINITION.CAN_REDEF_TABLE PL/SQL procedure to verify that the table can be redefined online. For example, to migrate the scott.emp table, enter the following command:
DBMS_REDEFINITION.CAN_REDEF_TABLE('scott','emp');
CREATE TABLE int_emp( empno NUMBER(4), ename NVARCHAR2(10), job NVARCHAR2(9), mgr NUMBER(4), hiredate DATE, sal NUMBER(7,2), deptno NUMBER(2), org NVARCHAR2(10));
DBMS_REDEFINITION.START_REDEF_TABLE('scott', 'emp', 'int_emp', 'empno empno, to_nchar(ename) ename, to_nchar(job) job, mgr mgr, hiredate hiredate, sal sal, deptno deptno, to_nchar(org) org');
If you are migrating CLOB columns to NCLOB columns, then use the TO_NCLOB SQL conversion function instead of the TO_NCHAR SQL function.
DISABLED mode. Triggers that are defined on the interim table are not executed until the online table redefinition process has been completed.DBMS_REDEFINITION.SYNC_INTERIM_TABLE procedure. This reduces the time required for the DBMS_REDEFINITION.FINISH_REDEF_TABLE procedure. Enter a command similar to the following:
DBMS_REDEFINITION.SYNC_INTERIM_TABLE('scott', 'emp', 'int_emp');
DBMS_REDEFINITION.FINISH_REDEF_TABLE procedure. Enter a command similar to the following:
DBMS_REDEFINITION.RINISH_REDEF_TABLE('scott', 'emp', 'int_emp');
When this procedure has been completed, the following conditions are true:
DROP TABLE int_emp;
The results of the online table redefinition tasks are as follows:
START_REDEF_TABLE subprogram and before the FINISH_REDEF_TABLE subprogram are defined for the redefined original table. Referential constraints that apply to the interim table now apply to the redefined original table and are enabled.| See Also:
Oracle Database Administrator's Guide for more information about online table redefinition |
You may need to perform additional tasks to recover a migrated database schema to its original state. Consider the issues described in Table 11-2.
|
 Copyright © 1996, 2003 Oracle Corporation All Rights Reserved. |
|

