| Oracle® Database Backup and Recovery Advanced User's Guide 10g Release 1 (10.1) Part Number B10734-01 |
|





|
View PDF |
| Oracle® Database Backup and Recovery Advanced User's Guide 10g Release 1 (10.1) Part Number B10734-01 |
|
|
View PDF |
Tuning RMAN performance is mostly a matter of maximizing the speed with which RMAN creates your backups and restores from backups, on disk and especially on tape. A secondary concern is limiting the effect of backup activities on database throughput.
You may also need to tune performance of the database during instance recovery.
This chapter covers the concepts needed for performance tuning, and the features in RMAN that can help you. The discussion is divided into the following sections:
RMAN backup and restore operations have the following distinct components:
The slowest of these operations in any RMAN task is called the bottleneck. RMAN tuning involves identifying the bottlenecks for a given task and using RMAN commands, initialization parameter settings, or adjustments to physical media to improve performance on the backup.
The key to tuning RMAN is understanding how it performs I/O. RMAN's backup and restore jobs use two types of I/O buffers: DISK and tertiary storage (usually tape). When performing a backup, RMAN reads input files using disk buffers and writes the output backup file by using either disk or tape buffers. Restore operations use disk or tape buffers for input, depending on where the backup is stored, and disk buffers for output.
To tune RMAN effectively, you must thoroughly understand concepts such as synchronous and asynchronous I/O, disk and tape buffers, and channel architecture. When you understand these concepts, then you can learn how to use fixed views to monitor bottlenecks, and use the techniques described in "Tuning RMAN Backup Performance: Examples" to solve problems.
There are a number of concepts that affect RMAN performance and that can therefore influence your strategy for backup performance tuning:
RMAN I/O uses two different types of buffers: disk and tape. These buffers are typically different sizes. They are allocated differently, depending upon the device type and the role the buffer plays in an RMAN operation.
To understand how RMAN allocates buffers to read datafiles during backups, you must understand how RMAN multiplexing works.
RMAN multiplexing is RMAN's ability to read a number of files in a backup simultaneously from different sources to improve reading performance, and then write them to a single backup piece. The level of multiplexing is the number of files read simultaneously.
Multiplexing is described at greater length in "Multiplexed Backup Sets". The level of multiplexing is determined by the algorithm described in "Algorithm for Multiplexed Backups". Review this section before proceeding.
When RMAN backs up from disk, it uses the datafile described in the following table to determine how large to make the buffers.
The number of buffers allocated depends on the following rules:
If you backup to or restore from an sbt device, then by default the database allocates four buffers for each channel for the tape writers (or reads if doing a restore). The size of these buffers is platform dependent, but is typically 256K. This value can be changed using the ALLOCATE or SEND command using the PARMS and the BLKSIZE option.
To calculate the total size of buffers used during a backup or restore, multiply the buffer size by 2, and then multiply this product by the number of channels.
For example, assume that you use two tape channels and each buffer is 256K. In this case, the total size of buffers used during a backup is as follows:
256KB/buffer x 4 buffers/channel x 2 channels = 2 MB
RMAN allocates the tape buffers in the SGA if I/O slaves are being used, or the PGA otherwise.
If you use I/O slaves, then set the LARGE_POOL_SIZE initialization parameter to set aside SGA memory dedicated to holding these large memory allocations. This prevents RMAN I/O buffers from competing with the library cache for SGA memory. If I/O slaves for tape I/O were requested but there is not enough space in the SGA for them, slaves are not used, and a message appears in the alert log.
When RMAN reads or writes data, the I/O is either synchronous or asynchronous. When the I/O is synchronous, a server process can perform only one task at a time. When it is asynchronous, a server process can begin an I/O and then perform other work while waiting for the I/O to complete. It can also begin multiple I/O operations before waiting for the first to complete.
Some operating systems support native asynchronous disk I/O. The database takes advantage of this feature if it is available. On operating systems that do not support native asynchronous I/O, the database can simulate it with special I/O slave processes that are dedicated to performing I/O on behalf of another process. You can control disk I/O slaves by setting the DBWR_IO_SLAVES parameter to a nonzero value. The database allocates four backup disk I/O slaves for any nonzero value of DBWR_IO_SLAVES.
By contrast, tape I/O is always synchronous. For tape I/O, each channel allocated (whether manually or based on a CONFIGURE command) corresponds to a server process, called here a channel process.
Figure 14-1 shows synchronous I/O in a backup to tape.
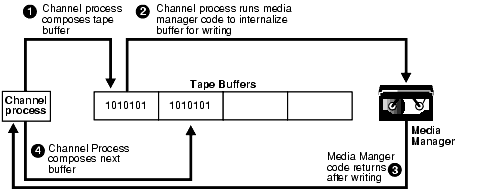
Text description of the illustration bradv015.gif
The following steps occur:
Figure 14-2 shows asynchronous I/O in a tape backup. Asynchronous I/O to tape is simulated by using tape slaves. In this case, each allocated channel corresponds to a server process, which in the explanation which follows is identified as a channel process. For each channel process, one tape slave is started (or more than one, in the case of multiple copies).
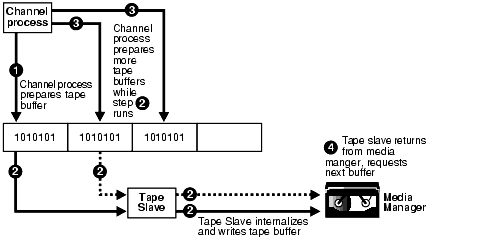
Text description of the illustration bradv012.gif
The following steps occur:
The following factors affect the speed of the backup to tape:
The tape native transfer rate is the speed of writing to a tape without compression. This speed represents the upper limit of the backup rate. The upper limit of your backup performance should be the aggregate transfer rate of all of your tape drives. If your backup is already performing at that rate, and if it is not using an excessive amount of CPU, then RMAN performance tuning will not help.
The level of tape compression is very important for backup performance. If the tape has good compression, then the sustained backup rate is faster. For example, if the compression ratio is 2:1 and native transfer rate of the tape drive is 6 MB/s, then the resulting backup speed is 12 MB/s. In this case, RMAN must be able to read disks with a throughput of more than 12 MB/s or the disk becomes the bottleneck for the backup.
|
Note: You should not use both tape compression provided by the media manager and binary backupset compression as provided by RMAN. If the media manager compression is efficient, then it is usually the better choice. Using RMAN compressed backupsets can be an effective alternative if you need to reduce bandwidth used to move uncompressed backupsets over a network to the media manager, and if the CPU overhead required to compress the data in RMAN is acceptable. See Oracle Database Backup and Recovery Basics for more on using compressed backupsets. |
Tape streaming during write operations has a major impact on tape backup performance. Almost all tape drives currently on the market are fixed-speed, streaming tape drives. Because such drives can only write data at one speed, when they run out of data to write to tape, the tape must slow down and stop. Generally, when the drive's buffer empties, the tape is moving so quickly that it actually overshoots; to continue writing, the drive must rewind the tape to locate the point where it stopped writing.
The physical tape block size can affect backup performance. The block size is the amount of data written by media management software to a tape in one write operation. In general, the larger the tape block size, the faster the backup. Note that physical tape block size is not controlled by RMAN or the Oracle database server, but by media management software. See your media management software's documentation for details.
There are a number of features you can use to tune your backup performance, once you have sufficient knowledge of your database and its workload and bottlenecks.
The RATE parameter specifies the bytes/second that RMAN reads on this channel. Use this parameter to set an upper limit for bytes read so that RMAN does not consume excessive disk bandwidth and degrade online performance.
For example, set RATE=1500K. If each disk drive delivers 3 MB/second, then RMAN leaves some disk bandwidth available to the online system.
Many factors can affect backup performance. Often, finding the solution to a slow backup is a process of trial and error. To get the best performance for a backup, follow the suggested steps in this section:
The RATE parameter on a channel is intended to reduce, rather than increase, backup throughput, so that more disk bandwidth is available for other database operations.
If your backup is not streaming to tape, then make sure that the RATE parameter is not set on the ALLOCATE CHANNEL or CONFIGURE CHANNEL commands.
If and only if your disk does not support asynchronous I/O, then try setting the DBWR_IO_SLAVES initialization parameter to a nonzero value. Any nonzero value for DBWR_IO_SLAVES causes a fixed number (four) of disk I/O slaves to be used for backup and restore, which simulates asynchronous I/O. If I/O slaves are used, I/O buffers are obtained from the SGA. The large pool is used, if configured. Otherwise, the shared pool is used.
Note: By setting DBWR_IO_SLAVES, the database writer processes will use slaves as well. You may need to increase the value of the PROCESSES initialization parameter.
Set this initialization parameter if the database reports an error in the alert.log stating that it does not have enough memory and that it will not start I/O slaves. The message looks something like the following:
ksfqxcre: failure to allocate shared memory means sync I/O will be used whenever async I/O to file not supported natively
When attempting to get shared buffers for I/O slaves, the database does the following:
LARGE_POOL_SIZE is set, then the database attempts to get memory from the large pool. If this value is not large enough, then an error is recorded in the alert log, the database does not try to get buffers from the shared pool, and asynchronous I/O is not used.LARGE_POOL_SIZE is not set, then the database attempts to get memory from the shared pool.alert.log file indicating that synchronous I/O is used for this backup.The memory from the large pool is used for many features, including the shared server (formerly called multi-threaded server), parallel query, and RMAN I/O slave buffers. Configuring the large pool prevents RMAN from competing with other subsystems for the same memory.
Requests for contiguous memory allocations from the shared pool are usually small (under 5 KB) in size. However, it is possible that a request for a large contiguous memory allocation can either fail or require significant memory housekeeping to release the required amount of contiguous memory. Although the shared pool may be unable to satisfy this memory request, the large pool is able to do so. The large pool does not have a least recently used (LRU) list; the database does not attempt to age memory out of the large pool.
Use the LARGE_POOL_SIZE initialization parameter to configure the large pool. To see in which pool (shared pool or large pool) the memory for an object resides, query V$SGASTAT.POOL.
The formula for setting LARGE_POOL_SIZE is as follows:
LARGE_POOL_SIZE = number_of_allocated_channels * (16 MB + ( 4 * size_of_tape_buffer ) )
| See Also:
Oracle Database Concepts for more information about the large pool, and Oracle Database Reference for complete information about initialization parameters |
When performing a full backup of files that are largely empty, or when performing an incremental backup when block change tracking is disabled and few blocks have changed, RMAN may not be able to supply blocks with data to the tape fast enough to keep it streaming. In either case, you can improve performance by increasing the level of multiplexing.
An incremental backup is an RMAN backup in which only modified blocks are backed up. If change tracking is disabled, then incremental backups are often slow because the database must read the entire datafile to find blocks which have changed. If tape drives are not locally attached, then incremental backups can be faster. You must consider how much bandwidth exists for reading the disks compared to the bandwidth for writing to the tapes. If tape bandwidth is limited compared to disk, then incremental backups may help.
If only a few blocks have changed in an incremental backup, then you need to input many buffers from the datafile before you accumulate enough blocks to fill a buffer and write to tape. Hence, the tape drive may not stream.
If none of the previous steps improves backup performance, then try to determine the exact source of the bottleneck. Use the V$BACKUP_SYNC_IO and V$BACKUP_ASYNC_IO views to determine the source of backup or restore bottlenecks and to see detailed progress of backup jobs.
V$BACKUP_SYNC_IO contains rows when the I/O is synchronous to the process (or thread on some platforms) performing the backup. V$BACKUP_ASYNC_IO contains rows when the I/O is asynchronous. Asynchronous I/O is obtained either with I/O processes or because it is supported by the underlying operating system.
| See Also:
Oracle Database Reference for more information about these views |
To determine whether your tape is streaming when the I/O is synchronous, query the EFFECTIVE_BYTES_PER_SECOND column in the V$BACKUP_SYNC_IO or V$BACKUP_ASYNC_IO view. If EFFECTIVE_BYTES_PER_SECOND is less than the raw capacity of the hardware, then the tape is not streaming. If EFFECTIVE_BYTES_PER_SECOND is greater than the raw capacity of the hardware, the tape may or may not be streaming. Compression may cause the EFFECTIVE_BYTES_PER_SECOND to be greater than the speed of real I/O.
With synchronous I/O, it is difficult to identify specific bottlenecks because all synchronous I/O is a bottleneck to the process. The only way to tune synchronous I/O is to compare the rate (in bytes/second) with the device's maximum throughput rate. If the rate is lower than the rate that the device specifies, then consider tuning this aspect of the backup and restore process. The DISCRETE_BYTES_PER_SECOND column in the V$BACKUP_SYNC_IO view displays the I/O rate. If you see data in V$BACKUP_SYNC_IO, then the problem is that you have not enabled asynchronous I/O or you are not using disk I/O slaves.
Long waits are the number of times the backup or restore process told the operating system to wait until an I/O was complete. Short waits are the number of times the backup or restore process made an operating system call to poll for I/O completion in a nonblocking mode. Ready indicates the number of time when I/O was already ready for use and so there was no need to made an operating system call to poll for I/O completion.
The simplest way to identify the bottleneck is to query V$BACKUP_ASYNC_IO for the datafile that has the largest ratio for LONG_WAITS divided by IO_COUNT.
|
Note: If you have synchronous I/O but you have set |
| See Also:
Oracle Database Reference for descriptions of the |
This section offers guidelines for tuning the time required to perform crash and instance recovery. It contains the following topics:
Instance and crash recovery are the automatic application of redo log records to Oracle data blocks after a crash or system failure. During normal operation, if an instance is shut down cleanly (as when using a SHUTDOWN IMMEDIATE statement), rather than terminated abnormally, then the in-memory changes that have not already been written to the datafiles on disk are written to disk as part of the checkpoint performed during shutdown.
However, if a single instance database crashes or if all instances of an Oracle Real Application Cluster configuration crash, then Oracle performs crash recovery at the next startup. If one or more instances of an Oracle Real Application Cluster configuration crash, then a surviving instance performs instance recovery automatically. Instance and crash recovery occur in two steps: cache recovery followed by transaction recovery.
The database can be opened as soon as cache recovery completes, so improving the performance of cache recovery is important for increasing availability.
During the cache recovery step, Oracle applies all committed and uncommitted changes in the redo log files to the affected data blocks. The work required for cache recovery processing is proportional to the rate of change to the database (update transactions each second) and the time between checkpoints.
To make the database consistent, the changes that were not committed at the time of the crash must be undone (in other words, rolled back). During the transaction recovery step, Oracle applies the rollback segments to undo the uncommitted changes.
Periodically, Oracle records a checkpoint. A checkpoint is the highest system change number (SCN) such that all data blocks less than or equal to that SCN are known to be written out to the data files. If a failure occurs, then only the redo records containing changes at SCNs higher than the checkpoint need to be applied during recovery. The duration of cache recovery processing is determined by two factors: the number of data blocks that have changes at SCNs higher than the SCN of the checkpoint, and the number of log blocks that need to be read to find those changes.
Frequent checkpointing writes dirty buffers to the datafiles more often than otherwise, and so reduces cache recovery time in the event of an instance failure. If checkpointing is frequent, then applying the redo records in the redo log between the current checkpoint position and the end of the log involves processing relatively few data blocks. This means that the cache recovery phase of recovery is fairly short.
However, in a high-update system, frequent checkpointing can reduce runtime performance, because checkpointing causes DBWn processes to perform writes.
To minimize the duration of cache recovery, you must force Oracle to checkpoint often, thus keeping the number of redo log records to be applied during recovery to a minimum. However, in a high-update system, frequent checkpointing increases the overhead for normal database operations.
If daily operational efficiency is more important than minimizing recovery time, then decrease the frequency of writes to data files due to checkpoints. This should improve operational efficiency, but also increase cache recovery time.
The fast-start fault recovery feature reduces the time required for cache recovery and makes the recovery bounded and predictable by limiting the number of dirty buffers and the number of redo records generated between the most recent redo record and the last checkpoint.
The foundation of fast-start fault recovery is the fast-start checkpointing architecture. Instead of conventional event-driven (that is, log switching) checkpointing, which does bulk writes, fast-start checkpointing occurs incrementally. Each DBWn process periodically writes buffers to disk to advance the checkpoint position. The oldest modified blocks are written first to ensure that every write lets the checkpoint advance. Fast-start checkpointing eliminates bulk writes and the resultant I/O spikes that occur with conventional checkpointing.
With the fast-start fault recovery feature,the FAST_START_MTTR_TARGET initialization parameter simplifies the configuration of recovery time from instance or system failure. FAST_START_MTTR_TARGET specifies a target for the expected mean time to recover (MTTR), that is, the time (in seconds) that it should take to start up the instance and perform cache recovery. Once FAST_START_MTTR_TARGET is set, the database manages incremental checkpoint writes in an attempt to meet that target. If you have chosen a practical value for FAST_START_MTTR_TARGET, you can expect your database to recover, on average, in approximately the number of seconds you have chosen.
The maximum value for FAST_START_MTTR_TARGET is 3600 seconds (one hour). If you set the value to more than 3600, then Oracle rounds it to 3600.
The following example shows how to set the value of FAST_START_MTTR_TARGET:
SQL> ALTER DATABASE SET FAST_START_MTTR_TARGET=30;
In principle, the minimum value for FAST_START_MTTR_TARGET is one second. However, the fact that you can set FAST_START_MTTR_TARGET this low does not mean that that target can be achieved. There are practical limits to the minimum achievable MTTR target, due to such factors as database startup time.
The MTTR target that your database can achieve given the current value of FAST_START_MTTR_TARGET is called the effective MTTR target. You can view your current effective MTTR by viewing the TARGET_MTTR column of the V$INSTANCE_RECOVERY view.
The practical range of MTTR target values for your database is defined to be the range between the lowest achieveable effective MTTR target for your database and the longest that startup and cache recovery will take in the worst-case scenario (that is, when the whole buffer cache is dirty). A procedure for determining the range of achievable MTTR target values, one step in the process of tuning your FAST_START_MTTR_TARGET value, is described in "Determine the Practical Range for FAST_START_MTTR_TARGET".
To reduce the checkpoint frequency and optimize runtime performance, you can do the following:
FAST_START_MTTR_TARGET to 3600. This enables fast-start checkpointing and the fast-start fault recovery feature, but minimizes its effect on runtime performance while avoiding the need for performance tuning of FAST_START_MTTR_TARGET.| See Also:
Oracle Database Concepts for a complete discussion of checkpoints |
The V$INSTANCE_RECOVERY view displays the current recovery parameter settings. You can also use statistics from this view to determine which factor has the greatest influence on checkpointing.
The following table lists those columns most useful in monitoring predicted cache recovery performance:
For more details on the columns in V$INSTANCE_RECOVERY, see Oracle Database Reference.
As part of the ongoing monitoring of your database, you can periodically compare V$INSTANCE_RECOVERY.TARGET_MTTR to your FAST_START_MTTR_TARGET. The two values should generally be the same if the FAST_START_MTTR_TARGET value is in the practical range. If TARGET_MTTR is consistently longer than FAST_START_MTTR_TARGET, then set FAST_START_MTTR_TARGET to a value no less than TARGET_MTTR. If TARGET_MTTR is consistently shorter, then set FAST_START_MTTR_TARGET to a value no greater than TARGET_MTTR.
To determine the appropriate value for FAST_START_MTTR_TARGET for your database, execute the following four step process:
The FAST_START_MTTR_TARGET initialization parameter causes the database to calculate internal system trigger values, in order to limit the length of the redo log and the number of dirty data buffers in the data cache. This calculation uses estimated time to read a redo block, estimates of the time to read and write a data block, as well as characteristics of typical workload of the system, such as how many dirty buffers corresponds to how many change vectors, and so on.
Initially, internal defaults are used in the calculation. These defaults are replaced over time by data gathered on I/O performance during system operation and actual cache recoveries.
You will have to perform several instance recoveries in order to calibrate your FAST_START_MTTR_TARGET value properly. Before starting calibration, you must decide whether FAST_START_MTTR_TARGET is being calibrated for a database crash or a hardware crash. This is a consideration if your database files are stored in a file system or if your I/O subsystem has a memory cache, because there is a considerable difference in the read and write time to disk depending on whether or not the files are cached. The appropriate value for FAST_START_MTTR_TARGET will depend upon which type of crash is more important to recover from quickly.
To effecitvely calibrate FAST_START_MTTR_TARGET, make sure that you run the typcial workload of the system for long enough, and perform several instance recoveries to ensure that the time to read a redo block and the time to read or write a data block during recovery are recorded accurately.
After calibration, you can perform tests to determine the practical range for FAST_START_MTTR_TARGET for your database.
To determine the lower bound of the practical range, set FAST_START_MTTR_TARGET to 1, and start up your database. Then check the value of V$INSTANCE_RECOVERY.TARGET_MTTR, and use this value as a good lower bound for FAST_START_MTTR_TARGET. Database startup time, rather than cache recovery time, is usually the dominant factor in determining this limit.
For example, set the FAST_START_MTTR_TARGET to 1:
SQL> ALTER DATABASE SET FAST_START_MTTR_TARGET=1;
Then, execute the following query immediately after opening the database:
SQL> SELECT TARGET_MTTR, ESTIMATED_MTTR FROM V$INSTANCE_RECOVERY;
Oracle responds with the following:
TARGET_MTTR ESTIMATED_MTTR 18 15
The TARGET_MTTR value of 18 seconds is the minimum MTTR target that the system can achieve, that is, the lowest practical value for FAST_START_MTTR_TARGET. This minimum is calculated based on the average database startup time.
The ESTIMATED_MTTR field contains the estimated mean time to recovery based on the current state of the running database. Because the database has just opened, the system contains few dirty buffers, so not much cache recovery would be required if the instance failed at this moment. That is why ESTIMATED_MTTR can, for the moment, be lower than the minimum possible TARGET_MTTR.
ESTIMATED_MTTR can be affected in the short term by recent database activity. Assume that you query V$INSTANCE_RECOVERY immediately after a period of heavy update activity in the database. Oracle responds with the following:
TARGET_MTTR ESTIMATED_MTTR 18 30
Now the effective MTTR target is still 18 seconds, and the estimated MTTR (if a crash happened at that moment) is 30 seconds. This is an acceptable result. This means that some checkpoints writes might not have finished yet, so the buffer cache contains more dirty buffers than targeted.
Now wait for sixty seconds and reissue the query to V$INSTANCE_RECOVERY. Oracle responds with the following:
TARGET_MTTR ESTIMATED_MTTR 18 25
The estimated MTTR at this time has dropped to 25 seconds, because some of the dirty buffers have been written out during this period
To determine the upper bound of the practical range, set FAST_START_MTTR_TARGET to 3600, and operate your database under a typical workload for a while. Then check the value of V$INSTANCE_RECOVERY.TARGET_MTTR. This value is a good upper bound for FAST_START_MTTR_TARGET.
The procedure is substantially similar to that in "Determining Lower Bound for FAST_START_MTTR_TARGET: Scenario".
Once you have determined the practical bounds for the FAST_START_MTTR_TARGET parameter, select a preliminary value for the parameter. Choose a higher value within the practical range if your concern is with database performance, and a lower value within the practical range if your priority is shorter recovery times. The narrower the practical range, of course, the easier the choice becomes.
For example, if you discovered that the practical range was between 17 and 19 seconds, it would be quite simple to choose 19, because it makes relatively little difference in recovery time and at the same time minimizes the effect of checkpointing on system performance. However, if you found that the practical range was between 18 and 40 seconds, you might choose a compromise value of 30, and set the parameter accordingly:
SQL> ALTER DATABASE SET FAST_START_MTTR_TARGET=30;
You might then go on to use the MTTR Advisor to determine an optimal value.
Once you have selected a preliminary value for FAST_START_MTTR_TARGET, you can use MTTR Advisor to evaluate the effect of different FAST_START_MTTR_TARGET settings on system performance, compared to your chosen setting.
To enable MTTR Advisor, set the two initialization parameters STATISTICS_LEVEL and FAST_START_MTTR_TARGET.
STATISTICS_LEVEL governs whether all advisors are enabled and is not specific to MTTR Advisor. Make sure that it is set to TYPICAL or ALL. Then, when FAST_START_MTTR_TARGET is set to a non-zero value, the MTTR Advisor is enabled.
After enabling MTTR Advisor, run a typical database workload for a while. When MTTR Advisor is ON, the database simulates checkpoint queue behavior under the current value of FAST_START_MTTR_TARGET, and up to four other different MTTR settings within the range of valid FAST_START_MTTR_TARGET values. (The database will in this case determine the valid range for FAST_START_MTTR_TARGET itself before testing different values in the range.)
The dynamic performance view V$MTTR_TARGET_ADVICE lets you view statistics or advisories collected by MTTR Advisor.
The database populates V$MTTR_TARGET_ADVICE with advice about the effects of each of the FAST_START_MTTR_TARGET settings for your database. For each possible value of FAST_START_MTTR_TARGET, the row contains details about how many cache writes would be performed under the workload tested for that value of FAST_START_MTTR_TARGET.
Specifically, each row contains information about cache writes, total phyiscal writes (including direct writes), and total I/O (including reads) for that value of FAST_START_MTTR_TARGET, expressed both as a total number of operations and a ratio compared to the operations under your chosen FAST_START_MTTR_TARGET value. For instance, a ratio of 1.2 indicates 20% more cache writes.
Knowing the effect of different FAST_START_MTTR_TARGET settings on cache write activity and other I/O enables you to decide better which FAST_START_MTTR_TARGET value best fits your recovery and performance needs.
If MTTR Advisor is currently on,V$MTTR_TARGET_ADVICE shows the Advisor information collected. If MTTR Advisor is currently OFF, the view shows information collected the last time MTTR Advisor was ON since database startup, if any. If the database has been restarted since the last time the MTTR Advisor was used, or if it has never been used, the view will not show any rows.
| See Also:
Oracle Database Reference for column details of the |
You can use the V$INSTANCE_RECOVERY view column OPTIMAL_LOGFILE_SIZE to determine the size of your online redo logs. This field shows the redo log file size in megabytes that is considered optimal based on the current setting of FAST_START_MTTR_TARGET. If this field consistently shows a value greater than the size of your smallest online log, then you should configure all your online logs to be at least this size.
Note, however, that the redo log file size affects the MTTR. In some cases, you may be able to refine your choice of the optimal FAST_START_MTTR_TARGET value by re-running the MTTR Advisor with your suggested optimal log file size.
|
 Copyright © 2003 Oracle Corporation All Rights Reserved. |
|

