Release 8.0
A58225-01
Library |
Product |
Contents |
Index |
| Oracle8
SQL Reference
Release 8.0 A58225-01 |
|
![]()
![]()
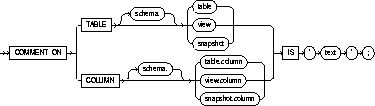
To add a comment about a table, view, snapshot, or column
into the data dictionary. See also "Using Comments".
The table, view, or snapshot must be in your own schema or
you must have COMMENT ANY TABLE system privilege.
|
TABLE |
specifies the schema and name of the table, view, or snapshot to be commented. |
|
COLUMN |
specifies the name of the column of a table, view, or snapshot to be commented. If you omit schema, Oracle assumes the table, view, or snapshot is in your own schema. |
|
IS 'text' |
is the text of the comment. See the syntax description of 'text' in "Text". |
You can effectively drop a comment from the database by setting
it to the empty string ' '. For information on the data dictionary views
that contain comments, see Oracle8 Reference.
To insert an explanatory remark on the NOTES column of the SHIPPING table, you might issue the following statement:
COMMENT ON COLUMN shipping.notes IS 'Special packing or shipping instructions';
To drop this comment from the database, issue the following statement:
COMMENT ON COLUMN shipping.notes IS ' ';
To end your current transaction and make permanent all changes
performed in the transaction. This command also erases all savepoints in
the transaction and releases the transaction's locks. See also "About
Transactions".
You can also use this command to commit an in-doubt distributed
transaction manually. See "Ending Transactions" for
more information on transactions.
You need no privileges to commit your current transaction.
To manually commit a distributed in-doubt transaction that
you originally committed, you must have FORCE TRANSACTION system privilege.
To manually commit a distributed in-doubt transaction that was originally
committed by another user, you must have FORCE ANY TRANSACTION system privilege.

A transaction (or a logical unit of work) is a sequence of
SQL statements that Oracle treats as a single unit. A transaction begins
with the first executable SQL statement after a COMMIT, ROLLBACK, or connection
to the database. A transaction ends with a COMMIT, ROLLBACK, or disconnection
(intentional or unintentional) from the database. Note that Oracle issues
an implicit COMMIT before and after any data definition language (DDL)
statement.
You can also use a COMMIT or ROLLBACK statement to terminate
a read-only transaction begun by a SET TRANSACTION statement.
This example inserts a row into the DEPT table and commits this change:
INSERT INTO dept VALUES (50, 'MARKETING', 'TAMPA'); COMMIT WORK;
The following statement commits the current transaction and associates a comment with it:
COMMIT WORK COMMENT 'In-doubt transaction Code 36, Call (415) 555-2637';
If a network or machine failure prevents this distributed
transaction from committing properly, Oracle stores the comment in the
data dictionary along with the transaction ID. The comment indicates the
part of the application in which the failure occurred and provides information
for contacting the administrator of the database where the transaction
was committed.
Oracle with the distributed option allows you to perform
distributed transactions, or transactions that modify data on multiple
databases. To commit a distributed transaction, you need only issue a COMMIT
statement as you would to commit any other transaction. Each component
of the distributed transaction is then committed on each database.
If a network or machine failure occurs during the commit
process for a distributed transaction, the state of the transaction may
be unknown, or in-doubt. After consultation with the administrators of
the other databases involved in the transaction, you may decide to manually
commit or roll back the transaction on your local database. You can manually
commit the transaction on your local database by using the FORCE clause
of the COMMIT command. For more information on these topics, see Oracle8
Distributed Database Systems.
Note that a COMMIT statement with a FORCE clause only commits
the specified transaction. Such a statement does not affect your current
transaction.
The following statement manually commits an in-doubt distributed transaction:
COMMIT FORCE '22.57.53';
Oracle recommends that you explicitly end every transaction
in your application programs with a COMMIT or ROLLBACK statement, including
the last transaction, before disconnecting from Oracle. If you do not explicitly
commit the transaction and the program terminates abnormally, the last
uncommitted transaction is automatically rolled back.
A normal exit from most Oracle utilities and tools causes
the current transaction to be committed. A normal exit from an Oracle precompiler
program does not commit the transaction and relies on Oracle to roll back
the current transaction.
To define an integrity constraint. An integrity constraint
is a rule that restricts the values for one or more columns in a table
or an index-organized table.
CONSTRAINT clauses can appear in either CREATE TABLE or ALTER
TABLE commands. To define an integrity constraint, you must have the privileges
necessary to issue one of these commands. See CREATE
TABLE and ALTER TABLE.
Defining a constraint may also require additional privileges
or preconditions, depending on the type of constraint. For information
on these privileges, see the descriptions of each type of integrity constraint
in "Defining Integrity Constraints".
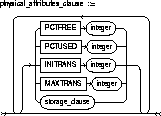
storage_clause: See the STORAGE
clause.
|
CONSTRAINT |
identifies the integrity constraint by the name constraint. Oracle stores this name in the data dictionary along with the definition of the integrity constraint. If you omit this identifier, Oracle generates a name with this form: SYS_Cn. See also "Defining Integrity Constraints". |
|
|
|
If you do not specify NULL or NOT NULL in a column definition, NULL is the default. |
|
|
UNIQUE |
designates a column or combination of columns as a unique key. You cannot define UNIQUE constraints on index-organized tables. See also "UNIQUE Constraints". |
|
|
PRIMARY KEY |
designates a column or combination of columns as the table's primary key. See also "PRIMARY KEY Constraints". |
|
|
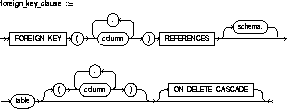
FOREIGN KEY |
designates a column or combination of columns as the foreign key in a referential integrity constraint. |
|
|
REFERENCES |
identifies the primary or unique key that is referenced by a foreign key in a referential integrity constraint. See also "Referential Integrity Constraints". |
|
|
ON DELETE CASCADE |
specifies that Oracle maintains referential integrity by automatically removing dependent foreign key values if you remove a referenced primary or unique key value. |
|
|
NULL |
specifies that a column can contain null values. |
|
|
NOT NULL |
specifies that a column cannot contain null values. See also "NOT NULL Constraints". |
|
|
CHECK |
specifies a condition that each row in the table must satisfy. See also "CHECK Constraints". |
|
|
DEFERRABLE |
indicates that constraint checking can be deferred until the end of the transaction by using the SET CONSTRAINT(S) command. |
|
|
NOT DEFERRABLE |
indicates that this constraint is checked at the end of each DML statement. You cannot defer a NOT DEFERRABLE constraint with the SET CONSTRAINT(S) command. If you do not specify DEFERRABLE or NOT DEFERRABLE, then NOT DEFERRABLE is the default. See also "DEFERRABLE Constraints". |
|
|
|
INITIALLY IMMEDIATE |
indicates that at the start of every transaction, the default is to check this constraint at the end of every DML statement. If no INITIALLY clause is specified, INITIALLY IMMEDIATE is the default. |
|
|
INITIALLY DEFERRED |
implies that this constraint is DEFERRABLE and specifies that, by default, the constraint is checked only at the end of each transaction. |
|
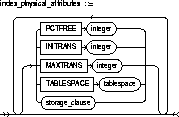
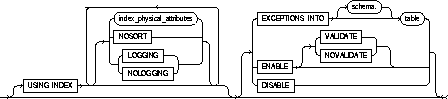
USING INDEX |
specifies parameters for the index Oracle uses to enable a UNIQUE or PRIMARY KEY constraint. The name of the index is the same as the name of the constraint. You can choose the values of the INITRANS, MAXTRANS, TABLESPACE, STORAGE, PCTFREE, LOGGING, and NOLOGGING parameters for the index. For information on these parameters, see CREATE TABLE. |
|
|
|
Use this clause only when enabling UNIQUE and PRIMARY KEY constraints. |
|
|
NOSORT |
indicates that the rows are stored in the database in ascending order and therefore Oracle does not have to sort the rows when creating the index. |
|
|
EXCEPTIONS INTO |
specifies a table into which Oracle places the ROWIDs of all rows violating the constraint. Note: You must create an appropriate exceptions report table to accept information from the EXCEPTIONS option of the ENABLE clause before enabling the constraint. You can create an exception table by submitting the script UTLEXCPT.SQL, which creates a table named EXCEPTIONS. You can create additional exceptions tables with different names by modifying and resubmitting the script. |
|
|
|
The EXCEPTIONS INTO clause is a valid option only when validating a constraint (see the ENABLE clause) or when enabling a constraint with an ALTER TABLE command. See ALTER TABLE. |
|
|
ENABLE VALIDATE |
ensures that all new insert, delete, and update operations on the constrained data comply with the constraint. Checks that all old data also obeys the constraint. An enabled and validated constraint guarantees that all data is and will continue to be valid. This is the default. |
|
|
ENABLE NOVALIDATE |
ensures that all new insert, update, and delete operations on the constrained data comply with the constraint. Oracle does not verify that existing data in the table complies with the constraint. |
|
|
DISABLE |
disables the integrity constraint. If an integrity constraint is disabled, Oracle does not enable it. If you do not specify this option, Oracle automatically enables the integrity constraint. |
|
|
You can also enable and disable integrity constraints with the ENABLE and DISABLE clauses of the CREATE TABLE and ALTER TABLE commands. See the ENABLE clause and the DISABLE clause. See also "Enabling and Disabling Constraints". |
||
|
Disabled constraints can be made enabled with ALTER TABLE. |
||
To define an integrity constraint, include a CONSTRAINT clause in a CREATE TABLE or ALTER TABLE statement. The CONSTRAINT clause has two syntactic forms:
The table_constraint syntax and the column_constraint
syntax are simply different syntactic means of defining integrity constraints.
A constraint that references more than one column must be defined as a
table constraint. There is no other functional difference between an integrity
constraint defined with table_constraint syntax and the same constraint
defined with column_constraint syntax.
The NOT NULL constraint specifies that a column cannot contain
nulls. To satisfy this constraint, every row in the table must contain
a value for the column.
The NULL keyword indicates that a column can contain nulls.
It does not actually define an integrity constraint. If you do not specify
either NOT NULL or NULL, the column can contain nulls by default.
You can specify NOT NULL or NULL with column_constraint
syntax only in a CREATE TABLE or ALTER TABLE statement, not with table_constraint
syntax.
The following statement alters the EMP table and defines and enables a NOT NULL constraint on the SAL column:
ALTER TABLE emp MODIFY (sal NUMBER CONSTRAINT nn_sal NOT NULL);
NN_SAL ensures that no employee in the table has a null salary.
The UNIQUE constraint designates a column or combination
of columns as a unique key. To satisfy a UNIQUE constraint, no two rows
in the table can have the same value for the unique key. However, the unique
key made up of a single column can contain nulls.
A unique key column cannot be of datatype LONG or LONG RAW.
You cannot designate the same column or combination of columns as both
a unique key and a primary key or as both a unique key and a cluster key.
However, you can designate the same column or combination of columns as
both a unique key and a foreign key.
You can define a unique key on a single column with column_constraint
syntax.
The following statement creates the DEPT table and defines and enables a unique key on the DNAME column:
CREATE TABLE dept (deptno NUMBER(2), dname VARCHAR2(9) CONSTRAINT unq_dname UNIQUE, loc VARCHAR2(10) );
The constraint UNQ_DNAME identifies the DNAME column as a
unique key. This constraint ensures that no two departments in the table
have the same name. However, the constraint does allow departments without
names.
Alternatively, you can define and enable this constraint with the table_constraint syntax:
CREATE TABLE dept (deptno NUMBER(2), dname VARCHAR2(9), loc VARCHAR2(10), CONSTRAINT unq_dname UNIQUE (dname) USING INDEX PCTFREE 20 TABLESPACE user_x STORAGE (INITIAL 8K NEXT 6K) );
The above statement also uses the USING INDEX option to specify
storage characteristics for the index that Oracle creates to enable the
constraint.
A composite unique key is a unique key made up of a combination
of columns. Oracle creates an index on the columns of a unique key, so
a composite unique key can contain a maximum of 16 columns. To define a
composite unique key, you must use table_constraint syntax rather
than column_constraint syntax.
To satisfy a constraint that designates a composite unique
key, no two rows in the table can have the same combination of values in
the key columns. Any row that contains nulls in all key columns automatically
satisfies the constraint. However, two rows that contain nulls for one
or more key columns and the same combination of values for the other key
columns violate the constraint.
The following statement defines and enables a composite unique key on the combination of the CITY and STATE columns of the CENSUS table:
ALTER TABLE census ADD CONSTRAINT unq_city_state UNIQUE (city, state) USING INDEX PCTFREE 5 TABLESPACE user_y EXCEPTIONS INTO bad_keys_in_ship_cont;
The UNQ_CITY_STATE constraint ensures that the same combination
of CITY and STATE values does not appear in the table more than once.
The CONSTRAINT clause also specifies other properties of the constraint:
A PRIMARY KEY constraint designates a column or combination of columns as the table's primary key. To satisfy a PRIMARY KEY constraint, both of the following conditions must be true:
A table can have only one primary key.
A primary key column cannot be of datatype LONG or LONG RAW.
You cannot designate the same column or combination of columns as both
a primary key and a unique key or as both a primary key and a cluster key.
However, you can designate the same column or combination of columns as
both a primary key and a foreign key.
You can use the column_constraint syntax to define
a primary key on a single column.
The following statement creates the DEPT table and defines and enables a primary key on the DEPTNO column:
CREATE TABLE dept (deptno NUMBER(2) CONSTRAINT pk_dept PRIMARY KEY, dname VARCHAR2(9), loc VARCHAR2(10) );
The PK_DEPT constraint identifies the DEPTNO column as the
primary key of the DEPT table. This constraint ensures that no two departments
in the table have the same department number and that no department number
is NULL.
Alternatively, you can define and enable this constraint with table_constraint syntax:
CREATE TABLE dept (deptno NUMBER(2), dname VARCHAR2(9), loc VARCHAR2(10), CONSTRAINT pk_dept PRIMARY KEY (deptno) );
A composite primary key is a primary key made up of a combination
of columns. Oracle creates an index on the columns of a primary key; therefore,
a composite primary key can contain a maximum of 16 columns. To define
a composite primary key, you must use the table_constraint syntax
rather than the column_constraint syntax.
The following statement defines a composite primary key on the combination of the SHIP_NO and CONTAINER_NO columns of the SHIP_CONT table:
ALTER TABLE ship_cont ADD PRIMARY KEY (ship_no, container_no) DISABLE;
This constraint identifies the combination of the SHIP_NO
and CONTAINER_NO columns as the primary key of the SHIP_CONT table. The
constraint ensures that no two rows in the table have the same values for
both the SHIP_NO column and the CONTAINER_NO column.
The CONSTRAINT clause also specifies the following properties of the constraint:
A referential integrity constraint designates a column or combination of columns as a foreign key and establishes a relationship between that foreign key and a specified primary or unique key, called the referenced key. In this relationship, the table containing the foreign key is called the child table and the table containing the referenced key is called the parent table. Note the following restrictions:
To satisfy a referential integrity constraint, each row of the child table must meet one of the following conditions:
A referential integrity constraint is defined in the child table. A referential integrity constraint definition can include any of the following keywords:
Before you define a referential integrity constraint in the
child table, the referenced UNIQUE or PRIMARY KEY constraint on the parent
table must already be defined. Also, the parent table must be in your own
schema or you must have REFERENCES privilege on the columns of the referenced
key in the parent table. Before you enable a referential integrity constraint,
its referenced constraint must be enabled.
You cannot define a referential integrity constraint in a
CREATE TABLE statement that contains an AS clause. Instead, you can create
the table without the constraint and then add it later with an ALTER TABLE
statement.
A foreign key column cannot be of datatype LONG or LONG RAW.
You can designate the same column or combination of columns as both a foreign
key and a primary or unique key. You can also designate the same column
or combination of columns as both a foreign key and a cluster key.
You can define multiple foreign keys in a table. Also, a
single column can be part of more than one foreign key.
You can use column_constraint syntax to define a referential
integrity constraint in which the foreign key is made up of a single column.
The following statement creates the EMP table and defines and enables a foreign key on the DEPTNO column that references the primary key on the DEPTNO column of the DEPT table:
CREATE TABLE emp (empno NUMBER(4), ename VARCHAR2(10), job VARCHAR2(9), mgr NUMBER(4), hiredate DATE, sal NUMBER(7,2), comm NUMBER(7,2), deptno CONSTRAINT fk_deptno REFERENCES dept(deptno) );
The constraint FK_DEPTNO ensures that all departments given
for employees in the EMP table are present in the DEPT table. However,
employees can have null department numbers, meaning they are not assigned
to any department. If you wish to prevent the latter, you could create
a NOT NULL constraint on the deptno column in the EMP table, in
addition to the REFERENCES constraint.
Before you define and enable this constraint, you must define
and enable a constraint that designates the DEPTNO column of the DEPT table
as a primary or unique key. For the definition of such a constraint, see
the example.
Note that the referential integrity constraint definition
does not use the FOREIGN KEY keyword to identify the columns that make
up the foreign key. Because the constraint is defined with a column constraint
clause on the DEPTNO column, the foreign key is automatically on the DEPTNO
column.
Note that the constraint definition identifies both the parent
table and the columns of the referenced key. Because the referenced key
is the parent table's primary key, the referenced key column names are
optional.
Note that the above statement omits the DEPTNO column's datatype.
Because this column is a foreign key, Oracle automatically assigns it the
datatype of the DEPT.DEPTNO column to which the foreign key refers.
Alternatively, you can define a referential integrity constraint with table_constraint syntax:
CREATE TABLE emp (empno NUMBER(4), ename VARCHAR2(10), job VARCHAR2(9), mgr NUMBER(4), hiredate DATE, sal NUMBER(7,2), comm NUMBER(7,2), deptno, CONSTRAINT fk_deptno FOREIGN KEY (deptno) REFERENCES dept(deptno) );
Note that the foreign key definitions in both statements
of this example omit the ON DELETE CASCADE option, causing Oracle to forbid
the deletion of a department if any employee works in that department.
If you use the ON DELETE CASCADE option, Oracle permits deletions
of referenced key values in the parent table and automatically deletes
dependent rows in the child table to maintain referential integrity.
This example creates the EMP table, defines and enables the referential integrity constraint FK_DEPTNO, and uses the ON DELETE CASCADE option:
CREATE TABLE emp (empno NUMBER(4), ename VARCHAR2(10), job VARCHAR2(9), mgr NUMBER(4), hiredate DATE, sal NUMBER(7,2), comm NUMBER(7,2), deptno NUMBER(2) CONSTRAINT fk_deptno REFERENCES dept(deptno) ON DELETE CASCADE );
Because of the ON DELETE CASCADE option, Oracle cascades
any deletion of a DEPTNO value in the DEPT table to the DEPTNO values of
its dependent rows of the EMP table. For example, if Department 20 is deleted
from the DEPT table, Oracle deletes the department's employees from the
EMP table.
A composite foreign key is a foreign key made up of a combination
of columns. A composite foreign key can contain as many as 16 columns.
To define a referential integrity constraint with a composite foreign key,
you must use table_constraint syntax. You cannot use column_constraint
syntax, because this syntax can impose rules only on a single column. A
composite foreign key must refer to a composite unique key or a composite
primary key.
To satisfy a referential integrity constraint involving composite keys, each row in the child table must satisfy one of the following conditions:
The following statement defines and enables a foreign key on the combination of the AREACO and PHONENO columns of the PHONE_CALLS table:
ALTER TABLE phone_calls ADD CONSTRAINT fk_areaco_phoneno FOREIGN KEY (areaco, phoneno) REFERENCES customers(areaco, phoneno) EXCEPTIONS INTO wrong_numbers;
The constraint FK_AREACO_PHONENO ensures that all the calls
in the PHONE_CALLS table are made from phone numbers that are listed in
the CUSTOMERS table. Before you define and enable this constraint, you
must define and enable a constraint that designates the combination of
the AREACO and PHONENO columns of the CUSTOMERS table as a primary or unique
key.
The EXCEPTIONS option causes Oracle to write information
to the WRONG_NUMBERS table about any rows in the PHONE_CALLS table that
violate the constraint.
The CHECK constraint explicitly defines a condition. To satisfy the constraint, each row in the table must make the condition either TRUE or unknown (due to a null). For information on conditions, see the syntax description of condition in "Conditions". The condition of a CHECK constraint can refer to any column in the table, but it cannot refer to columns of other tables. CHECK constraint conditions cannot contain the following constructs:
Whenever Oracle evaluates a CHECK constraint condition for
a particular row, any column names in the condition refer to the column
values in that row.
If you create multiple CHECK constraints for a column, design
them carefully so their purposes do not conflict. Oracle does not verify
that CHECK conditions are not mutually exclusive.
The following statement creates the DEPT table and defines a CHECK constraint in each of the table's columns:
CREATE TABLE dept (deptno NUMBER CONSTRAINT check_deptno CHECK (deptno BETWEEN 10 AND 99) DISABLE, dname VARCHAR2(9) CONSTRAINT check_dname CHECK (dname = UPPER(dname)) DISABLE, loc VARCHAR2(10) CONSTRAINT check_loc CHECK (loc IN ('DALLAS','BOSTON', 'NEW YORK','CHICAGO')) DISABLE);
Each constraint restricts the values of the column in which it is defined:
Because each CONSTRAINT clause contains the DISABLE option,
Oracle only defines the constraints and does not enable them.
Unlike other types of constraints, a CHECK constraint defined
with column_constraint syntax can impose rules on any column in
the table, rather than only on the column in which it is defined.
The following statement creates the EMP table and uses a table constraint clause to define and enable a CHECK constraint:
CREATE TABLE emp (empno NUMBER(4), ename VARCHAR2(10), job VARCHAR2(9), mgr NUMBER(4), hiredate DATE, sal NUMBER(7,2), comm NUMBER(7,2), deptno NUMBER(2), CHECK (sal + comm <= 5000) );
This constraint uses an inequality condition to limit an employee's total compensation, the sum of salary and commission, to $5000:
Because the CONSTRAINT clause in this example does not supply
a constraint name, Oracle generates a name for the constraint.
The following statement defines and enables a PRIMARY KEY constraint, two referential integrity constraints, a NOT NULL constraint, and two CHECK constraints:
CREATE TABLE order_detail (CONSTRAINT pk_od PRIMARY KEY (order_id, part_no), order_id NUMBER CONSTRAINT fk_oid REFERENCES scott.order (order_id), part_no NUMBER CONSTRAINT fk_pno REFERENCES scott.part (part_no), quantity NUMBER CONSTRAINT nn_qty NOT NULL CONSTRAINT check_qty_low CHECK (quantity > 0), cost NUMBER CONSTRAINT check_cost CHECK (cost > 0) );
The constraints enable the following rules on table data:
This example also illustrates the following points about constraint clauses and column definitions:
You can specify table and column constraints as DEFERRABLE
or NOT DEFERRABLE. DEFERRABLE means that the constraint will not be checked
until the transaction is committed. The default is NOT DEFERRABLE.
If you specify DEFERRABLE, you can also specify the constraint's
initial state as INITIALLY DEFERRED and thereby start the transaction in
DEFERRED mode. Or you can specify a DEFERRABLE constraint's initial state
as INITIALLY IMMEDIATE and start the transaction in NOT DEFERRED mode.
The following statement creates table GAMES with a NOT DEFERRABLE INITIALLY IMMEDIATE constraint check on the SCORES column:
CREATE TABLE games (scores NUMBER CHECK (scores >= 0));
To define a unique constraint on a column as INITIALLY DEFERRED DEFERRABLE, issue the following statement:
CREATE TABLE orders (ord_num NUMBER CONSTRAINT unq_num UNIQUE (ord_num) INITIALLY DEFERRED DEFERRABLE);
A constraint cannot be defined as NOT DEFERRABLE INITIALLY
DEFERRED.
Use SET CONSTRAINT(S) to set,
for a single transaction, whether a deferrable constraint is checked following
each DML statement or when the transaction is committed. You cannot alter
a constraint's deferrability status; you must drop the constraint and re-create
it.
See Oracle8 Administrator's
Guide and Oracle8 Concepts
for more information about deferred constraints.
Constraints can have one of three states: DISABLE, ENABLE
NOVALIDATE, or ENABLE VALIDATE.
Taking a constraint from a disabled to enable validated state
requires an exclusive lock on the table, because while all old data is
being checked for validity, no new data can be entered into the table.
Due to this behavior, only one constraint can be enabled at a time, and
each new constraint must check all existing rows by serial scan.
To avoid locking the table, place the constraint in the ENABLE
NOVALIDATE state, using the ENABLE clause.
This state ensures that all new DML statements on the table are validated,
therefore Oracle does not need to prevent concurrent access to the table.
ENABLE NOVALIDATE also allows you to place several of the
table's constraints in the ENABLE VALIDATE state concurrently. Each scan
that Oracle performs to validate existing data can also be performed in
parallel when possible.
Placing constraints concurrently in the ENABLE VALIDATE state
requires that you issue multiple ALTER TABLE commands from separate sessions.
Enabling a primary key or unique key constraint automatically
creates a unique index to enforce the constraint. This index is dropped
if the constraint is subsequently disabled, thus causing Oracle to rebuild
the index every time the constraint is enabled.
To avoid this behavior, create new primary key and unique
key constraints initially disabled; then create nonunique indexes or use
existing nonunique indexes to enforce the constraint. Because Oracle does
not drop the nonunique index when the constraint is disabled, any ENABLE
operation on a primary key or unique key constraint occurs almost instantly,
because the index already exists. Redundant indexes are also eliminated.
For more information about PRIMARY KEY and UNIQUE constraints,
see the ENABLE clause.
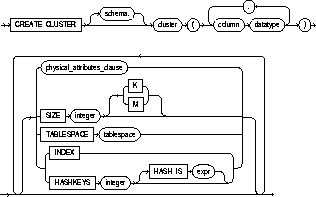
To create a cluster. A cluster is a schema object
that contains one or more tables, all of which have one or more columns
in common. See also "About Clusters" and "Adding
Tables to a Cluster".
To create a cluster in your own schema, you must have CREATE
CLUSTER system privilege. To create a cluster in another user's schema,
you must have CREATE ANY CLUSTER system privilege. Also, the owner of the
schema to contain the cluster must have either space quota on the tablespace
containing the cluster or UNLIMITED TABLESPACE system privilege.
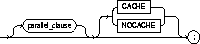
storage_clause: See the STORAGE
clause.
parallel_clause: See the PARALLEL
clause.
|
schema |
is the schema to contain the cluster. If you omit schema, Oracle creates the cluster in your current schema. |
|
cluster |
is the name of the cluster to be created. |
|
column |
is the name of a column in the cluster key. See also "Cluster Keys". |
|
datatype |
is the datatype of a cluster key column. A cluster key column can have any datatype except LONG or LONG RAW. You cannot use the HASH IS clause if any column datatype is not INTEGER or NUMBER with scale 0. For information on datatypes, see the section "Datatypes". |
|
physical_attributes_clause: |
|
|
PCTUSED |
specifies the limit that Oracle uses to determine when additional rows can be added to a cluster's data block. The value of this parameter is expressed as a whole number and interpreted as a percentage. |
|
PCTFREE |
specifies the space reserved in each of the cluster's data blocks for future expansion. The value of the parameter is expressed as a whole number and interpreted as a percentage. |
|
INITRANS |
specifies the initial number of concurrent update transactions allocated for data blocks of the cluster. The value of this parameter for a cluster cannot be less than 2 or more than the value of the MAXTRANS parameter. The default value is the greater of the INITRANS value for the cluster's tablespace and 2. |
|
MAXTRANS |
specifies the maximum number of concurrent update transactions for any given data block belonging to the cluster. The value of this parameter cannot be less than the value of the INITRANS parameter. The maximum value of this parameter is 255. The default value is the MAXTRANS value for the tablespace to contain the cluster. |
|
|
For a complete description of the PCTUSED, PCTFREE, INITRANS, and MAXTRANS parameters, see CREATE TABLE. |
|
SIZE |
specifies the amount of space in bytes to store all rows with the same cluster key value or the same hash value. You can use K or M to specify this space in kilobytes or megabytes. If you omit this parameter, Oracle reserves one data block for each cluster key value or hash value. See also "Cluster Size". |
|
TABLESPACE |
specifies the tablespace in which the cluster is created. |
|
storage_clause |
specifies how data blocks are allocated to the cluster. See the STORAGE clause. |
|
INDEX |
creates an indexed cluster. In an indexed cluster, rows are stored together based on their cluster key values. See also "Types of Clusters". |
|
HASHKEYS |
creates a hash cluster and specifies the number of hash values for a hash cluster. Oracle rounds the HASHKEYS value up to the nearest prime number to obtain the actual number of hash values. The minimum value for this parameter is 2. If you omit both the INDEX option and the HASHKEYS parameter, Oracle creates an indexed cluster by default. See also "Types of Clusters". |
|
HASH IS |
specifies a expression to be used as the hash function for the hash cluster. The expression: |
|
|
|
|
|
If you omit the HASH IS clause, Oracle uses an internal hash function for the hash cluster. |
|
|
The cluster key of a hash column can have one or more columns of any datatype. Hash clusters with composite cluster keys or cluster keys made up of noninteger columns must use the internal hash function. |
|
parallel_clause |
specifies the degree of parallelism to use when creating the cluster and the default degree of parallelism to use when querying the cluster after creation. See the PARALLEL clause. |
|
CACHE |
specifies that the blocks retrieved for this table are placed at the most recently used end of the LRU list in the buffer cache when a full table scan is performed. This option is useful for small lookup tables. |
|
NOCACHE |
specifies that the blocks retrieved for this table are placed at the least recently used end of the LRU list in the buffer cache when a full table scan is performed. This is the default behavior. |
A cluster is a schema object that contains one or
more tables that all have one or more columns in common. Rows of one or
more tables that share the same value in these common columns are physically
stored together within the database.
Clustering provides more control over the physical storage
of rows within the database. Clustering can reduce both the time it takes
to access clustered tables and the space needed to store the table. After
you create a cluster and add tables to it, the cluster is transparent.
You can access clustered tables with SQL statements just as you can nonclustered
tables.
If you cannot fit all rows for one hash value into a data
block, do not use hash clusters. Performance is very poor in this circumstance
because an insert or update of a row in a hash cluster with a size exceeding
the data block size fills the block and performs row chaining to contain
the rest of the row.
Generally, you should only cluster tables that are frequently
joined on the cluster key columns in SQL statements. Clustering multiple
tables improves the performance of joins, but it is likely to reduce the
performance of full table scans, INSERT statements, and UPDATE statements
that modify cluster key values. Before clustering, consider its benefits
and trade-offs in light of the operations you plan to perform on your data.
For more information on the performance implications of clustering, see
Oracle8 Tuning.
The columns defined by the CREATE CLUSTER command make up
the cluster key. These cluster columns must correspond in both datatype
and size to columns in each of the clustered tables, although they need
not correspond in name.
You cannot specify integrity constraints as part of the definition
of a cluster key column. Instead, you can associate integrity constraints
with the tables that belong to the cluster.
A cluster can be either an indexed cluster or a hash cluster.
In an indexed cluster, Oracle stores together rows
having the same cluster key value. Each distinct cluster key value is stored
only once in each data block, regardless of the number of tables and rows
in which it occurs. This saves disk space and improves performance for
many operations.
You may want to use indexed clusters in the following cases:
After you create an indexed cluster, you must create an index
on the cluster key before you can issue any data manipulation language
(DML) statements against a table in the cluster. This index is called the
cluster index. For information on creating a cluster index, see
CREATE INDEX. As with the columns of any index,
the order of the columns in the cluster key affects the structure of the
cluster index.
A cluster index provides quick access to rows within a cluster
based on the cluster key. If you issue a SQL statement that searches for
a row in the cluster based on its cluster key value, Oracle searches the
cluster index for the cluster key value and then locates the row in the
cluster based on its ROWID.
In a hash cluster, Oracle stores together rows that
have the same hash key value. The hash value for a row is the value
returned by the cluster's hash function. When you create a hash cluster,
you can either specify a hash function or use the Oracle internal hash
function. Hash values are not actually stored in the cluster, although
cluster key values are stored for every row in the cluster.
You may want to use hash clusters in the following cases:
The hash function provides access to rows in the table based
on the cluster key value. If you issue a SQL statement that locates a row
in the cluster based on its cluster key value, Oracle applies the hash
function to the given cluster key value and uses the resulting hash value
to locate the matching rows. Because multiple cluster key values can map
to the same hash value, Oracle must also check the row's cluster key value.
This process often results in less I/O than the process for the indexed
cluster, because the index search is not required.
Oracle's internal hash function returns values ranging from
0 to the value of HASHKEYS - 1. If you specify a column with the HASH IS
clause, the column values need not fall into this range. Oracle divides
the column value by the HASHKEYS value and uses the remainder as the hash
value. The hash value for null is HASHKEYS - 1. Oracle also rounds the
HASHKEYS value up to the nearest prime number to obtain the actual number
of hash values. This rounding reduces the likelihood of hash collisions,
or multiple cluster key values having the same hash value.
You cannot create a cluster index for a hash cluster, and
you need not create an index on a hash cluster key.
Oracle uses the value of the SIZE parameter to determine
the space reserved for rows corresponding to one cluster key value or one
hash value. This space then determines the maximum number of cluster or
hash values stored in a data block. If the SIZE value is not a divisor
of the data block size, Oracle uses the next largest divisor. If the SIZE
value is larger than the data block size, Oracle uses the operating system
block size, reserving at least one data block per cluster or hash value.
Oracle also considers the length of the cluster key when
determining how much space to reserve for the rows having a cluster key
value. Larger cluster keys require larger sizes. To see the actual size,
query the KEY_SIZE column of the USER_CLUSTERS data dictionary view. This
does not apply to hash clusters because hash values are not actually stored
in the cluster.
Although the maximum number of cluster and hash key values
per data block is fixed on a per `-cluster basis, Oracle does not reserve
an equal amount of space for each cluster or hash key value. Varying this
space stores data more efficiently, because the data stored per cluster
or hash key value is rarely fixed.
A SIZE value smaller than the space needed by the average
cluster or hash key value may require the data for one cluster key or hash
key value to occupy multiple data blocks. A SIZE value much larger results
in wasted space.
When you create a hash cluster, Oracle immediately allocates
space for the cluster based on the values of the SIZE and HASHKEYS parameters.
For more information on how Oracle allocates space for clusters, see Oracle8
Concepts.
You can add tables to an existing cluster by issuing a CREATE
TABLE statement with the CLUSTER clause. A cluster can contain as many
as 32 tables, although the performance gains of clustering are often lost
in clusters of more than four or five tables.
All tables in the cluster have the cluster's storage characteristics
as specified by the PCTUSED, PCTFREE, INITRANS, MAXTRANS, TABLESPACE, and
STORAGE parameters.
The following statement creates an indexed cluster named PERSONNEL with the cluster key column DEPARTMENT_NUMBER, a cluster size of 512 bytes, and storage parameter values:
CREATE CLUSTER personnel ( department_number NUMBER(2) ) SIZE 512 STORAGE (INITIAL 100K NEXT 50K PCTINCREASE 10);
The following statements add the EMP and DEPT tables to the cluster:
CREATE TABLE emp (empno NUMBER PRIMARY KEY, ename VARCHAR2(10) NOT NULL CHECK (ename = UPPER(ename)), job VARCHAR2(9), mgr NUMBER REFERENCES scott.emp(empno), hiredate DATE CHECK (hiredate >= SYSDATE), sal NUMBER(10,2) CHECK (sal > 500), comm NUMBER(9,0) DEFAULT NULL, deptno NUMBER(2) NOT NULL ) CLUSTER personnel (deptno); CREATE TABLE dept (deptno NUMBER(2), dname VARCHAR2(9), loc VARCHAR2(9)) CLUSTER personnel (deptno);
The following statement creates the cluster index on the cluster key of PERSONNEL:
CREATE INDEX idx_personnel ON CLUSTER personnel;
After creating the cluster index, you can insert rows into
either the EMP or DEPT tables.
The following statement creates a hash cluster named PERSONNEL with the cluster key column DEPARTMENT_NUMBER, a maximum of 503 hash key values, each of size 512 bytes, and storage parameter values:
CREATE CLUSTER personnel ( department_number NUMBER ) SIZE 512 HASHKEYS 500 STORAGE (INITIAL 100K NEXT 50K PCTINCREASE 10);
Because the above statement omits the HASH IS clause, Oracle
uses the internal hash function for the cluster.
The following statement creates a hash cluster named PERSONNEL with the cluster key made up of the columns HOME_AREA_CODE and HOME_PREFIX, and uses a SQL expression containing these columns for the hash function:
CREATE CLUSTER personnel ( home_area_code NUMBER, home_prefix NUMBER ) HASHKEYS 20 HASH IS MOD(home_area_code + home_prefix, 101);
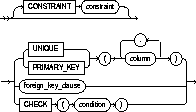 table_constraint::=
table_constraint::=

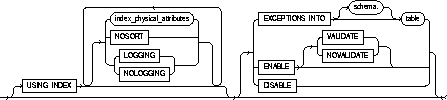
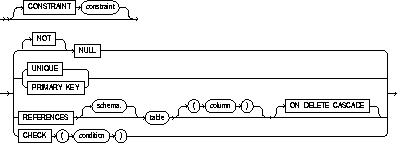 column_constraint::=
column_constraint::=