Release 8.0
A58225-01
Library |
Product |
Contents |
Index |
| Oracle8
SQL Reference
Release 8.0 A58225-01 |
|
![]()
![]()
For the current transaction, to:
The operations performed by a SET TRANSACTION statement affect
only your current transaction, not other users or other transactions. Your
transaction ends whenever you issue a COMMIT or ROLLBACK statement. Note
also that Oracle implicitly commits the current transaction before and
after executing a data definition language statement.
If you use a SET TRANSACTION statement, it must be the first
statement in your transaction. However, a transaction need not have a SET
TRANSACTION statement.
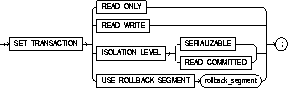
|
READ ONLY |
establishes the current transaction as a read-only transaction. See also rom. |
|
|
READ WRITE |
establishes the current transaction as a read-write transaction. |
|
|
ISOLATION LEVEL |
specifies how transactions containing database modifications are handled. |
|
|
|
SERIALIZABLE |
specifies serializable transaction isolation mode as defined in SQL92. If a serializable transaction contains data manipulation language (DML) that attempts to update any resource that may have been updated in a transaction uncommitted at the start of the serializable transaction, then the DML statement fails. |
|
|
|
Note: The COMPATIBLE initialization parameter must be set to 7.3.0 or higher for SERIALIZABLE mode to work. |
|
|
READ COMMITTED |
is the default Oracle transaction behavior. If the transaction contains DML that requires row locks held by another transaction, then the DML statement waits until the row locks are released. |
|
USE ROLLBACK SEGMENT |
assigns the current transaction to the specified rollback segment. This option also implicitly establishes the transaction as a read-write transaction. |
|
|
|
You cannot use the READ ONLY option and the USE ROLLBACK SEGMENT clause in a single SET TRANSACTION statement or in different statements in the same transaction. Read-only transactions do not generate rollback information and therefore are not assigned rollback segments. See also "Assigning Transactions to Rollback Segments". |
|
The default state for all transactions is statement-level
read consistency. You can explicitly specify this state by issuing a SET
TRANSACTION statement with the READ WRITE option.
You can establish transaction-level read consistency by issuing
a SET TRANSACTION statement with the READ ONLY option. After a transaction
has been established as read-only, all subsequent queries in that transaction
only see changes committed before the transaction began. Read-only transactions
are very useful for reports that run multiple queries against one or more
tables while other users update these same tables.
Only the following statements are permitted in a read-only transaction:
INSERT, UPDATE, and DELETE statements and SELECT statements
with the FOR UPDATE clause are not permitted. Any DDL statement implicitly
ends the read-only transaction.
The read consistency that read-only transactions provide
is implemented in the same way as statement-level read consistency. Every
statement by default uses a consistent view of the data as of the time
the statement is issued. Read-only transactions present a consistent view
of the data as of the time that the SET TRANSACTION READ ONLY statement
is issued. Read-only transactions provide read consistency is for all nodes
accessed by distributed queries and local queries.
You cannot toggle between transaction-level read consistency
and statement-level read consistency in the same transaction. A SET TRANSACTION
statement can only be issued as the first statement of a transaction.
The following statements could be run at midnight of the last day of every month to count how many ships and containers the company owns. This report would not be affected by any other user who might be adding or removing ships and/or containers.
COMMIT SET TRANSACTION READ ONLY SELECT COUNT(*) FROM ship SELECT COUNT(*) FROM container COMMIT;
The last COMMIT statement does not actually make permanent
any changes to the database. It simply ends the read-only transaction.
If you issue a DML statement in a transaction, Oracle assigns
the transaction to a rollback segment. The rollback segment holds the information
necessary to undo the changes made by the transaction. You can issue a
SET TRANSACTION statement with the USE ROLLBACK SEGMENT clause to choose
a specific rollback segment for your transaction. If you do not choose
a rollback segment, Oracle chooses one randomly and assigns your transaction
to it.
SET TRANSACTION lets you to assign transactions of different types to rollback segments of different sizes:
The following statement assigns your current transaction to the rollback segment OLTP_5:
SET TRANSACTION USE ROLLBACK SEGMENT oltp_5;
To specify storage characteristics for tables, indexes, clusters,
and rollback segments, and the default storage characteristics for tablespaces.
See also "Specifying Storage Parameters".
The STORAGE clause can appear in commands that create or alter any of the following schema objects:
To change the value of a STORAGE parameter, you must have
the privileges necessary to use the appropriate create or alter command.
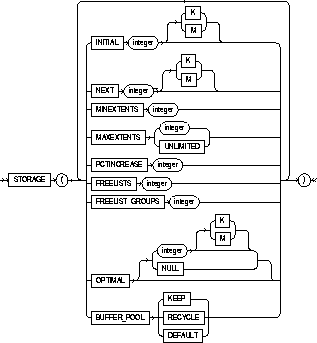
|
INITIAL |
specifies the size in bytes of the object's first extent. Oracle allocates space for this extent when you create the schema object. You can use K or M to specify this size in kilobytes or megabytes. The default value is the size of 5 data blocks. The minimum value is the size of 2 data blocks. The maximum value depends on your operating system. Oracle rounds values up to the next multiple of the data block size for values less than 5 data blocks, and rounds up to the next multiple of 5 data blocks for values greater than 5 data blocks. |
|
|
NEXT |
specifies the size in bytes of the next extent to be allocated to the object. You can use K or M to specify the size in kilobytes or megabytes. The default value is the size of 5 data blocks. The minimum value is the size of 1 data block. The maximum value depends on your operating system. Oracle rounds values up to the next multiple of the data block size for values less than 5 data blocks. For values greater than 5 data blocks, Oracle rounds up to a value that minimizes fragmentation, as described in Oracle8 Concepts. |
|
|
PCTINCREASE |
specifies the percent by which the third and subsequent extents grow over the preceding extent. The default value is 50, meaning that each subsequent extent is 50% larger than the preceding extent. The minimum value is 0, meaning all extents after the first are the same size. The maximum value depends on your operating system. |
|
|
|
You cannot specify PCTINCREASE for rollback segments. Rollback segments always have a PCTINCREASE value of 0. |
|
|
|
Oracle rounds the calculated size of each new extent up to the next multiple of the data block size. |
|
|
MINEXTENTS |
specifies the total number of extents to allocate when the object is created. This parameter enables you to allocate a large amount of space when you create an object, even if the space available is not contiguous. The default and minimum value is 1, meaning that Oracle only allocates the initial extent, except for rollback segments for which the default and minimum value is 2. The maximum value depends on your operating system. |
|
|
|
If the MINEXTENTS value is greater than 1, then Oracle calculates the size of subsequent extents based on the values of the INITIAL, NEXT, and PCTINCREASE parameters. |
|
|
MAXEXTENTS |
specifies the total number of extents, including the first, that Oracle can allocate for the object. The minimum value is 1 (except for rollback segments, which always have a minimum value of 2). The default and maximum values depend your data block size. |
|
|
|
UNLIMITED |
specifies that extents should be allocated automatically as needed. Do not use this option for rollback segments. |
|
|
||
|
FREELIST GROUPS |
for schema objects other than tablespace, specifies the number of groups of free lists for a table, partition, cluster, or index. The default and minimum value for this parameter is 1. Only use this parameter if you are using Oracle with the Parallel Server option in parallel mode. |
|
|
FREELISTS |
for objects other than tablespace, specifies the number of groups of free lists for each of the free list groups for the table, partition, cluster, or index. The default and minimum value for this parameter is 1, meaning that each free list group contains one free list. The maximum value of this parameter depends on the data block size. If you specify a FREELISTS value that is too large, Oracle returns an error message indicating the maximum value. |
|
|
|
You can specify the FREELISTS and the FREELIST GROUPS parameters only in CREATE TABLE, CREATE CLUSTER, and CREATE INDEX statements. |
|
|
OPTIMAL |
is relevant only to rollback segments. It specifies an optimal size in bytes for a rollback segment. You can use K or M to specify this size in kilobytes or megabytes. Oracle tries to maintain this size for the rollback segment by dynamically deallocating extents when their data is no longer needed for active transactions. Oracle deallocates as many extents as possible without reducing the total size of the rollback segment below the OPTIMAL value. |
|
|
|
NULL |
specifies no optimal size for the rollback segment, meaning that Oracle never deallocates the rollback segment's extents. This is the default behavior. |
|
|
The value of this parameter cannot be less than the space initially allocated for the rollback segment specified by the MINEXTENTS, INITIAL, NEXT, and PCTINCREASE parameters. The maximum value depends on your operating system. Oracle rounds values up to the next multiple of the data block size. |
|
|
BUFFER_POOL |
defines a default buffer pool (cache) for a schema object. All blocks for the object are stored in the specified cache. If a buffer pool is defined for a partitioned table or index, then the partitions inherit the buffer pool from the table or index definition, unless overridden by a partition-level definition. Note: BUFFER_POOL is not a valid option for creating or altering tablespaces or rollback segments. For more information about using multiple buffer pools, see Oracle8 Tuning. |
|
|
|
KEEP |
retains the schema object in memory to avoid I/O operations. |
|
|
RECYCLE |
eliminates blocks from memory as soon as they are no longer needed, thus preventing an object from taking up unnecessary cache space. |
|
|
DEFAULT |
always exists for objects not assigned to KEEP or RECYCLE. |
The storage parameters affect both how long it takes to access
data stored in the database and how efficiently space in the database is
used. For a discussion of the effects of these parameters, see Oracle8
Tuning.
When you create a tablespace, you can specify values for
the storage parameters. These values serve as default values for segments
allocated in the tablespace.
When you create a cluster, index, rollback segment, snapshot,
snapshot log, or table, you can specify values for the storage parameters
for the segments allocated to these objects. If you omit any storage parameter,
Oracle uses the value of that parameter specified for the tablespace. However,
when creating a rollback segment, you cannot specify PCTINCREASE (which
is always 0) or MINEXTENTS (which is always 2).
When you alter a cluster, index, rollback segment, snapshot,
snapshot log, or table, you can change the values of storage parameters.
The new values only affect future extent allocations. For this reason,
you cannot change the values of the INITIAL and MINEXTENTS parameter. If
you change the value of the NEXT parameter, the next allocated extent will
have the specified size, regardless of the size of the most recently allocated
extent and the value of the PCTINCREASE parameter. If you change the value
of the PCTINCREASE parameter, Oracle calculates the size of the next extent
using this new value and the size of the most recently allocated extent.
When you alter a tablespace, you can change the values of
storage parameters. The new values serve as default values only to subsequently
allocated segments (or subsequently created objects).
It is not good practice to create or alter a rollback segment
to use MAXEXTENTS UNLIMITED. Rogue transactions containing inserts, updates,
or deletes, that continue for a long time will continue to create new extents
until a disk is full.
A rollback segment that you create without specifying the
STORAGE option has the same storage parameters as the tablespace that the
rollback segment is created in. Thus, if the tablespace is created with
MAXEXTENT UNLIMITED, then the rollback segment would also have the same
default.
The following statement creates a table and provides storage parameter values:
CREATE TABLE dept (deptno NUMBER(2), dname VARCHAR2(14), loc VARCHAR2(13) ) STORAGE ( INITIAL 100K NEXT 50K MINEXTENTS 1 MAXEXTENTS 50 PCTINCREASE 5 );
Oracle allocates space for the table based on the STORAGE parameter values as follows:
If the table data continues to grow, Oracle allocates more extents, each 5% larger than the previous one.
The following statement creates a rollback segment and provides storage parameter values:
CREATE ROLLBACK SEGMENT rsone STORAGE ( INITIAL 10K NEXT 10K MINEXTENTS 2 MAXEXTENTS 25 OPTIMAL 50K );
Oracle allocates space for the rollback segment based on the STORAGE parameter values as follows:
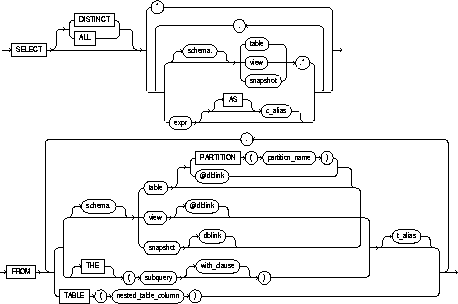
A subquery is a form of the SELECT command that appears
inside another SQL statement. A subquery is sometimes called a nested
query. The statement containing a subquery is called the parent
statement. The rows returned by the subquery are used by the parent
statement. See also "Using Subqueries".

|
WITH READ ONLY |
specifies that the subquery cannot be updated. |
|
WITH CHECK OPTION |
specifies that, if the subquery is used in place of a table in an INSERT, UPDATE, or DELETE statement, changes to that table that would produce rows excluded from the subquery are prohibited. In other words, the following statement: |
|
|
INSERT INTO (SELECT ename, deptno FROM emp WHERE deptno < 10) VALUES ('Taylor', 20); would be legal, but INSERT INTO (SELECT ename, deptno FROM emp WHERE deptno < 10 WITH CHECK OPTION) VALUES ('Taylor', 20); would be rejected. |
|
|
informs Oracle that the column value returned by the subquery is a nested table, not a scalar value. A subquery prefixed by THE is called a flattened subquery. "Using Flattened Subqueries". |
|
|
identifies the nested table column correlated to the outer query. |
Other keywords and parameters function as they are described
in SELECT. For more information,
see "Correlated Subqueries", "Selecting
from the DUAL Table", "Using Sequences", and "Distributed
Queries".
Use subqueries for the following purposes:
A subquery answers multiple-part questions. For example,
to determine who works in Taylor's department, you can first use a subquery
to determine the department in which Taylor works. You can then answer
the original question with the parent SELECT statement.
A subquery is evaluated once for the entire parent statement,
in contrast to a correlated subquery which is evaluated once per row processed
by the parent statement.
A subquery can itself contain a subquery. Oracle places no
limit on the level of query nesting.
To determine who works in Taylor's department, issue the following statement:
SELECT ename, deptno FROM emp WHERE deptno = (SELECT deptno FROM emp WHERE ename = 'TAYLOR');
To give all employees in the EMP table a 10% raise if they have not already been issued a bonus (if they do not appear in the BONUS table), issue the following statement:
UPDATE emp SET sal = sal * 1.1 WHERE empno NOT IN (SELECT empno FROM bonus);
To create a duplicate of the DEPT table named NEWDEPT, issue the following statement:
CREATE TABLE newdept (deptno, dname, loc) AS SELECT deptno, dname, loc FROM dept;
 To manipulate the individual rows
of a nested table stored in a database column, use the keyword THE. You
must prefix THE to a subquery that returns a single column value or an
expression that yields a nested table. If the subquery returns more than
a single column value, a run-time error results. Because the value is a
nested table, not a scalar value, Oracle must be informed, which is what
THE does.
To manipulate the individual rows
of a nested table stored in a database column, use the keyword THE. You
must prefix THE to a subquery that returns a single column value or an
expression that yields a nested table. If the subquery returns more than
a single column value, a run-time error results. Because the value is a
nested table, not a scalar value, Oracle must be informed, which is what
THE does.
The following example adds a new row to department 40's nested table stored in column PROJECTS:
INSERT INTO THE(SELECT projects FROM dept WHERE deptno = 40) VALUES(33, 'Install new email system', 14875);
This example increases the budgets for two projects assigned to department 70:
UPDATE THE(SELECT projects FROM dept WHERE deptno = 70) SET budget = budget + 1000 WHERE projno IN (24, 25);
A correlated subquery is a subquery that is evaluated once for each row processed by the parent statement. The parent statement can be a SELECT, UPDATE, or DELETE statement. The following examples show the general syntax of a correlated subquery:
SELECT select_list FROM table1 t_alias1 WHERE expr operator (SELECT column_list FROM table2 t_alias2 WHERE t_alias1.column operator t_alias2.column); UPDATE table1 t_alias1 SET column = (SELECT expr FROM table2 t_alias2 WHERE t_alias1.column = t_alias2.column); DELETE FROM table1 t_alias1 WHERE column operator (SELECT expr FROM table2 t_alias2 WHERE t_alias1.column = t_alias2.column);
This discussion focuses on correlated subqueries in SELECT
statements; it also applies to correlated subqueries in UPDATE and DELETE
statements.
You can use a correlated subquery to answer a multiple-part
question whose answer depends on the value in each row processed by the
parent statement. For example, a correlated subquery can be used to determine
which employees earn more than the average salaries for their departments.
In this case, the correlated subquery specifically computes the average
salary for each department.
Oracle performs a correlated subquery when the subquery references
a column from a table from the parent statement.
Oracle resolves unqualified columns in the subquery by looking
in the tables of the subquery, then in the tables of the parent statement,
then in the tables of the next enclosing parent statement, and so on. Oracle
resolves all unqualified columns in the subquery to the same table. If
the tables in a subquery and parent query contain a column with the same
name, a reference to the column of a table from the parent query must be
prefixed by the table name or alias. To make your statements easier for
you to read, always qualify the columns in a correlated subquery with the
table, view, or snapshot name or alias.
In an UPDATE statement, you can use a correlated subquery
to update rows in one table based on rows from another table. For example,
you could use a correlated subquery to roll up four quarterly sales tables
into a yearly sales table.
In a DELETE statement, you can use a correlated query to
delete only those rows that also exist in another table.
The following statement returns data about employees whose salaries exceed the averages for their departments. The following statement assigns an alias to EMP, the table containing the salary information, and then uses the alias in a correlated subquery:
SELECT deptno, ename, sal FROM emp x WHERE sal > (SELECT AVG(sal) FROM emp WHERE x.deptno = deptno) ORDER BY deptno;
For each row of the EMP table, the parent query uses the correlated subquery to compute the average salary for members of the same department. The correlated subquery performs these steps for each row of the EMP table:
The subquery is evaluated once for each row of the EMP table.
DUAL is a table automatically created by Oracle along with
the data dictionary. DUAL is in the schema of the user SYS, but is accessible
by the name DUAL to all users. It has one column, DUMMY, defined to be
VARCHAR2(1), and contains one row with a value 'X'. Selecting from the
DUAL table is useful for computing a constant expression with the SELECT
command. Because DUAL has only one row, the constant is returned only once.
Alternatively, you can select a constant, pseudocolumn, or expression from
any table.
The following statement returns the current date:
SELECT SYSDATE FROM DUAL;
You could select SYSDATE from the EMP table, but Oracle would
return 14 rows of the same SYSDATE, one for every row of the EMP table.
Selecting from DUAL is more convenient.
The sequence pseudocolumns NEXTVAL and CURRVAL can also appear
in the select list of a SELECT statement. For information on sequences
and their use, see CREATE SEQUENCE and "Pseudocolumns".
The following statement increments the ZSEQ sequence and returns the new value:
SELECT zseq.nextval FROM dual;
The following statement selects the current value of ZSEQ:
SELECT zseq.currval FROM dual;
Oracle's distributed database management system architecture
allows you to access data in remote databases using Net8 and an Oracle
server. You can identify a remote table, view, or snapshot by appending
@dblink to the end of its name. The dblink must be a complete
or partial name for a database link to the database containing the remote
table, view, or snapshot. For more information on referring to database
links, see "Referring to Objects in Remote Databases".
Distributed queries are currently subject to the restriction that all tables locked by a FOR UPDATE clause and all tables with LONG columns selected by the query must be located on the same database. For example, the following statement will cause an error:
SELECT emp_ny.* FROM emp_ny@ny, dept WHERE emp_ny.deptno = dept.deptno AND dept.dname = 'ACCOUNTING' FOR UPDATE OF emp_ny.sal;
The following statement fails because it selects LONG_COLUMN, a LONG value, from the EMP_REVIEW table on the NY database and locks the EMP table on the local database:
SELECT emp.empno, review.long_column, emp.sal FROM emp, emp_review@ny review WHERE emp.empno = emp_review.empno FOR UPDATE OF emp.sal;
This example shows a query that joins the DEPT table on the local database with the EMP table on the HOUSTON database:
SELECT ename, dname FROM emp@houston, dept WHERE emp.deptno = dept.deptno;
To remove all rows from a table or cluster and reset the
STORAGE parameters to the values when the table or cluster was created.
See also "Truncating Tables and Clusters". For illustrations,
see "Examples".
The table or cluster must be in your schema or you must have
DROP ANY TABLE system privilege. See also "Restrictions".
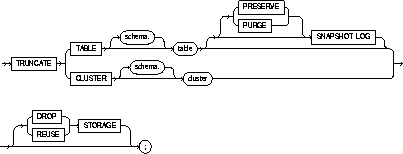
|
schema |
is the schema to contain the trigger. If you omit schema, Oracle creates the trigger in your own schema. |
|
|
TABLE |
specifies the schema and name of the table to be truncated. You can truncate index-organized tables. This table cannot be part of a cluster. |
|
|
|
When you truncate a table, Oracle also automatically deletes all data in the table's indexes. |
|
|
SNAPSHOT LOG |
specifies whether a snapshot log defined on the table is to be preserved or purged when the table is truncated. This clause allows snapshot master tables to be reorganized through export/import without affecting the ability of primary-key snapshots defined on the master to be fast refreshed. To support continued fast refresh of primary-key snapshots the snapshot log must record primary-key information. For more information about snapshot logs and the TRUNCATE command, see Oracle8 Replication. |
|
|
|
PRESERVE |
specifies that any snapshot log should be preserved when the master table is truncated. This is the default. |
|
|
PURGE |
specifies that any snapshot log should be purged when the master table is truncated. |
|
CLUSTER |
specifies the schema and name of the cluster to be truncated. You can only truncate an indexed cluster, not a hash cluster. |
|
|
|
When you truncate a cluster, Oracle also automatically deletes all data in the cluster's tables' indexes. |
|
|
DROP STORAGE |
deallocates the space from the deleted rows from the table or cluster. This space can subsequently be used by other objects in the tablespace. This is the default. |
|
|
REUSE STORAGE |
retains the space from the deleted rows allocated to the table or cluster. Storage values are not reset to the values when the table or cluster was created. This space can subsequently be used only by new data in the table or cluster resulting from inserts or updates. |
|
|
|
The DROP STORAGE and REUSE STORAGE options also apply to the space freed by the data deleted from associated indexes. |
|
You can use the TRUNCATE command to quickly remove all rows from a table or cluster. Removing rows with the TRUNCATE command is faster than removing them with the DELETE command for the following reasons:
The TRUNCATE command allows you to optionally deallocate
the space freed by the deleted rows. The DROP STORAGE option deallocates
all but the space specified by the table's MINEXTENTS parameter.
Deleting rows with the TRUNCATE command is also more convenient than dropping and re-creating a table because dropping and re-creating:
|
Note: When you truncate a table, the storage parameter NEXT is changed to be the size of the last extent deleted from the segment in the process of truncation. |
When you truncate a table, NEXT is automatically reset to
the last extent deleted.
You cannot individually truncate a table that is part of
a cluster. You must either truncate the cluster, delete all rows from the
table, or drop and re-create the table.
You cannot truncate the parent table of an enabled referential
integrity constraint. You must disable the constraint before truncating
the table. (An exception is that you may truncate the table if the integrity
constraint is self-referential.)
You cannot roll back a TRUNCATE statement.
The following statement deletes all rows from the EMP table and returns the freed space to the tablespace containing EMP:
TRUNCATE TABLE emp;
The above statement also deletes all data from all indexes
on EMP and returns the freed space to the tablespaces containing them.
The following statement deletes all rows from all tables in the CUST cluster, but leaves the freed space allocated to the tables:
TRUNCATE CLUSTER cust REUSE STORAGE
The above statement also deletes all data from all indexes
on the tables in CUST.
The following statements are examples of truncate statements that preserve snapshot logs:
TRUNCATE TABLE emp PRESERVE SNAPSHOT LOG; TRUNCATE TABLE stock;
To change existing values in a table or in a view's base
table.
|
Note: Descriptions of commands and clauses preceded by |
You can use comments in an UPDATE statement to pass instructions,
or hints, to the Oracle optimizer. The optimizer uses hints to choose
an execution plan for the statement. For more information, see Oracle8
Tuning.
You can place a parallel hint immediately after the UPDATE
keyword to parallelize both the underlying scan and UPDATE operations.
For detailed information about parallel DML, see Oracle8
Tuning, Oracle8
Parallel Server Concepts & Administration, and Oracle8
Concepts.
For you to update values in a table, the table must be in
your own schema or you must have UPDATE privilege on the table.
For you to update values in the base table of a view,
If the SQL92_SECURITY initialization parameter is set to
TRUE, then you must have SELECT privilege on the table whose column values
you are referencing (such as the columns in a WHERE clause) to perform
an UPDATE.
The UPDATE ANY TABLE system privilege also allows you to
update values in any table or any view's base table.
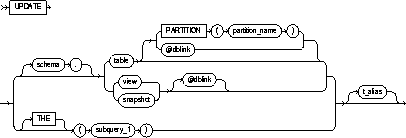
|
schema |
is the schema containing the table or view. If you omit schema, Oracle assumes the table or view is in your own schema. |
|
table / view |
is the name of the table to be updated. Issuing an UPDATE statement against a table fires any UPDATE triggers associated with the table. If you specify view, Oracle updates the view's base table. See also "Updating Views". |
|
PARTITION (partition_name) |
specifies partition-level row updates for table. The partition_name parameter may be the name of the partition within table targeted for update, or a more complicated predicate restricting the update to just one partition. See also "Updating Partitioned Tables". |
|
dblink |
is a complete or partial name of a database link to a remote database where the table or view is located. For information on referring to database links, see "Referring to Objects in Remote Databases". You can use a database link to update a remote table or view only if you are using Oracle's distributed functionality. |
|
|
If you omit dblink, Oracle assumes the table or view is on the local database. |
|
|
informs Oracle that the column value returned by the subquery is a nested table, not a scalar value. A subquery prefixed by THE is called a flattened subquery. See also "Using Flattened Subqueries". |
|
subquery_1 |
is a subquery that Oracle treats in the same manner as a view. See also "Subqueries". |
|
t_alias |
provides a different name for the table, view, or subquery to be referenced elsewhere in the statement. |
|
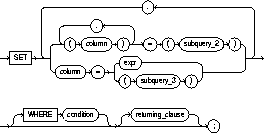
SET clause |
determines which columns are updated and what new values are stored in them. |
|
column |
is the name of a column of the table or view that is to be updated. If you omit a column of the table from the SET clause, that column's value remains unchanged. |
|
subquery_2 |
is a subquery that returns new values that are assigned to the corresponding columns. See also "Subqueries". |
|
expr |
is the new value assigned to the corresponding column. This expression can contain host variables and optional indicator variables. See the syntax description in "Expressions". |
|
subquery_3 |
is a subquery that returns new values that are assigned to the corresponding columns. See also "Subqueries" and "Correlated Update". |
|
If the SET clause contains a subquery, it must return exactly one row for each row updated. Each value in the subquery result is assigned respectively to the columns in the parenthesized list. If the subquery returns no rows, then the column is assigned a null. Subqueries may select from the table being updated. The SET clause may mix assignments of expressions and subqueries. |
|
|
WHERE |
restricts the rows updated to those for which the specified condition is TRUE. If you omit this clause, Oracle updates all rows in the table or view. See the syntax description of "Conditions". The WHERE clause determines the rows in which values are updated. If the WHERE clause is not specified, all rows are updated. For each row that satisfies the WHERE clause, the columns to the left of the equals (=) operator in the SET clause are set to the values of the corresponding expressions on the right. The expressions are evaluated as the row is updated. |
|
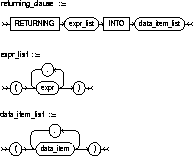
returning_clause |
retrieves the rows affected by the UPDATE statement. You can only retrieve scalar, LOB, ROWID, and REF types. See also "The RETURNING Clause". |
|
expr_list |
is some of the syntax descriptions in "Expressions". You must specify a column expression in the expr_list for each variable in the data_item_list. |
|
INTO |
indicates that the values of the changed rows are to be stored in the data_item variable(s) specified in data_item_list. |
|
data_item |
is a PL/SQL variable or bind variable which stores the retrieved expr value in the expr_list. |
|
You cannot use the returning_clause with parallel DML or with remote objects. |
|
If a view was created with the WITH CHECK OPTION, you can
update the view only if the resulting data satisfies the view's defining
query.
You cannot update a view if the view's defining query contains one of the following constructs:
When you create a partitioned table, you specify an ordered list of columns that determines into which partition a row or index entry belongs. These columns are the partitioning columns. The values in the partitioning columns of a row are the partitioning key for that row.
CREATE TABLE emp (emp_no NUMBER(5), dept VARCHAR2(2), name VARCHAR2 (30)) STORAGE (INITIAL 100K NEXT 50K) LOGGING PARTITION BY RANGE (emp_no) ( PARTITION acct VALUES LESS THAN (1000) TABLESPACE ts1, PARTITION sales VALUES LESS THAN (2000) TABLESPACE ts2 PARTITION educ VALUES LESS THAN (3000) ); INSERT INTO EMP VALUES (1226, 'sa', 'smith'); INSERT INTO EMP VALUES (2100, 'ed', 'jones');
In the following example, employee SMITH is updated in the EMP table:
UPDATE emp SET emp_no = 1356 WHERE name = 'SMITH';
The following statement is rejected because updating the row would cause JONES to move to another partition:
UPDATE emp SET emp_no = 1500 WHERE name = 'JONES';
Attempting to change the value of one or more columns that
are part of the partitioning key would cause the updated row to migrate
to another partition, thereby generating an error.
You do not need to specify the partition name when updating
values in a partitioned table. However in some cases specifying the partition
name can be more efficient than a complicated WHERE clause. To target a
single partition of a partitioned table whose values you want to change,
specify the PARTITION clause. This syntax can be less cumbersome than using
a WHERE clause.
The following example updates values in a single partition of the SALES table:
UPDATE sales PARTITION (feb96) s SET s.account_name = UPPER(s.account_name);
If a subquery refers to columns from the updated table, Oracle
evaluates the subquery once for each row, rather than once for the entire
update. Such an update is called a correlated update. The reference to
columns from the updated table is usually accomplished by means of a table
alias.
Potentially, each row evaluated by an UPDATE statement could
be updated with a different value as determined by the correlated subquery.
Normal UPDATE statements update each row with the same value.
The following statement gives null commissions to all employees with the job TRAINEE:
UPDATE emp SET comm = NULL WHERE job = 'TRAINEE';
The following statement promotes JONES to manager of Department 20 with a $1,000 raise (assuming there is only one JONES):
UPDATE emp SET job = 'MANAGER', sal = sal + 1000, deptno = 20 WHERE ename = 'JONES';
The following statement increases the balance of bank account number 5001 in the ACCOUNTS table on a remote database accessible through the database link BOSTON:
UPDATE accounts@boston SET balance = balance + 500 WHERE acc_no = 5001;
This example shows the following syntactic constructs of the UPDATE command:
UPDATE emp a SET deptno = (SELECT deptno FROM dept WHERE loc = 'BOSTON'), (sal, comm) = (SELECT 1.1*AVG(sal), 1.5*AVG(comm) FROM emp b WHERE a.deptno = b.deptno) WHERE deptno IN (SELECT deptno FROM dept WHERE loc = 'DALLAS' OR loc = 'DETROIT');
The above UPDATE statement performs the following operations:
 The following example updates particular
rows of the PROJS table:
The following example updates particular
rows of the PROJS table:
UPDATE THE(SELECT projs FROM dept d WHERE d.dno = 123) p SET p.budgets = p.budgets + 1 WHERE p.pno IN (123, 456);
You can use a RETURNING clause to return values from updated columns, and thereby eliminate the need to perform a SELECT following the UPDATE statement.
You can also use UPDATE with a RETURNING clause to update
from views with single base tables.
The following example returns values from the updated row and stores the result in PL/SQL variables BND1, BND2, BND3:
UPDATE emp SET job ='MANAGER', sal = sal + 1000, deptno = 20 WHERE ename = 'JONES' RETURNING sal*0.25, ename, deptno INTO bnd1, bnd2, bnd3;
 WITH_clause::=
WITH_clause::=
 THE
THE  TABLE (nested_table_column)
TABLE (nested_table_column)  are available only if the Oracle objects option is installed on your database
server.
are available only if the Oracle objects option is installed on your database
server.
 THE
THE