Release 8.0
A58225-01
Library |
Product |
Contents |
Index |
| Oracle8
SQL Reference
Release 8.0 A58225-01 |
|
![]()
![]()
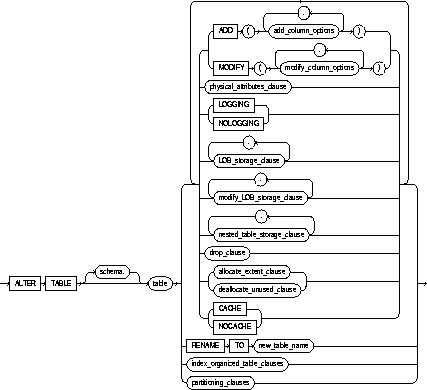
To alter the definition of a table in one of the following ways:
 add or modify object type,
nested table type, or VARRAY type column
add or modify object type,
nested table type, or VARRAY type column add integrity constraints to
object type columns
add integrity constraints to
object type columns|
Note: Descriptions of commands and clauses preceded by |
The table must be in your own schema, or you must have ALTER
privilege on the table, or you must have ALTER ANY TABLE system privilege.
For some operations you may also need the CREATE ANY INDEX privilege.
 To use an object type in a column
definition when modifying a table, either that object must belong to the
same schema as the table being altered, or you must have either the EXECUTE
ANY TYPE system privilege or the EXECUTE schema object privilege for the
object type.
To use an object type in a column
definition when modifying a table, either that object must belong to the
same schema as the table being altered, or you must have either the EXECUTE
ANY TYPE system privilege or the EXECUTE schema object privilege for the
object type.
column_constraint,
table_constraint: See the "CONSTRAINT
clause"
storage_clause:
See "STORAGE clause".
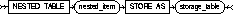 nested_table_storage_clause::=
nested_table_storage_clause::=
drop_clause: See
the "DROP clause".
deallocate_unused_clause:
See the "DEALLOCATE UNUSED clause".
 index_organized_table_clauses::=
index_organized_table_clauses::=
parallel_clause:
See the "PARALLEL clause".
|
schema |
is the schema containing the table. If you omit schema, Oracle assumes the table is in your own schema. |
|
|
table |
is the name of the table to be altered. You can alter the definition of an index-organized table. |
|
|
ADD |
adds a column or integrity constraint. You cannot ADD columns to an index-organized table. See also "Adding Columns". |
|
|
MODIFY |
modifies the definition of an existing column. If you omit any of the optional parts of the column definition (datatype, default value, or column constraint), these parts remain unchanged.You cannot MODIFY column definitions of index-organized tables. See also "Modifying Column Definitions". |
|
|
|
column |
is the name of the column to be added or modified. |
|
|
datatype |
specifies a datatype for a new column or a new datatype for an existing column. You can omit the datatype only if the statement also designates the column as part of the foreign key of a referential integrity constraint. Oracle automatically assigns the column the same datatype as the corresponding column of the referenced key of the referential integrity constraint. |
|
|
DEFAULT |
specifies a default value for a new column or a new default for an existing column. Oracle assigns this value to the column if a subsequent INSERT statement omits a value for the column. If you are adding a new column to the table and specify the default value, Oracle inserts the default column value into all rows of the table. The datatype of the default value must match the datatype specified for the column. The column must also be long enough to hold the default value. A DEFAULT expression cannot contain references to other columns, the pseudocolumns CURRVAL, NEXTVAL, LEVEL, and ROWNUM, or date constants that are not fully specified. |
|
|
column_constraint |
adds or removes a NOT NULL constraint to or from an existing column. See the syntax of column_constraint in the "CONSTRAINT clause". |
|
|
table_constraint |
adds an integrity constraint to the table. See the syntax of table_constraint in the "CONSTRAINT clause". See also "REFs". |
|
modify_default_attributes_clause |
is a valid option only for partitioned tables. Use this option to specify new values for the default attributes of a partitioned table. |
|
|
physical_attributes_clause |
changes the value of PCTFREE, PCTUSED, INITRANS, and MAXTRANS parameters for the table, partition, the overflow data segment, or the default characteristics of a partitioned table. See the PCTFREE, PCTUSED, INITRANS, and MAXTRANS parameters of "CREATE TABLE". |
|
|
|
storage_clause |
changes the storage characteristics of the table, partition, overflow data segment, or the default characteristics of a partitioned table. See the "STORAGE clause". |
|
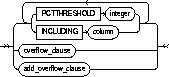
PCTTHRESHOLD |
specifies the percentage of space reserved in the index block for an index-organized table row. Any portion of the row that exceeds the specified threshold is stored in the overflow area. If OVERFLOW is not specified, then rows exceeding the THRESHOLD limit are rejected. PCTTHRESHOLD must be a value from 0 to 50. |
|
|
|
INCLUDING column_name |
specifies a column at which to divide an index-organized table row into index and overflow portions. All columns that follow column_name are stored in the overflow data segment. A column_name is either the name of the last primary key column or any non-primary-key column. |
|
|
OVERFLOW |
specifies the overflow data segment physical storage attributes to be modified for the index-organized table. Parameters specified in this clause are only applicable to the overflow data segment. See "CREATE TABLE". |
|
|
ADD OVERFLOW |
adds an overflow data segment to the specified index-organized table. |
|
|
See also "Index-Organized Tables". |
|
|
LOB |
specifies the LOB storage characteristics for the newly added LOB column. You cannot use this clause to modify an existing LOB column. |
|
|
lob_item |
is the LOB column name or LOB object attribute for which you are explicitly defining tablespace and storage characteristics that are different from those of the table. |
|
|
STORE AS |
|
|
|
|
lob_segname |
specifies the name of the LOB data segment. You cannot use lob_segname if more than one lob_item is specified. |
|
|
ENABLE STORAGE IN ROW |
specifies that the LOB value is stored in the row (inline) if its length is less than approximately 4000 bytes minus system control information. This is the default. |
|
|
DISABLE STORAGE IN ROW |
specifies that the LOB value is stored outside of the row regardless of the length of the LOB value. |
|
|
Note that the LOB locator is always stored in the row regardless of where the LOB value is stored. You cannot change the STORAGE IN ROW once it is set. |
|
|
|
CHUNK integer |
specifies the number of bytes to be allocated for LOB manipulation. If integer is not a multiple of the database block size, Oracle rounds up (in bytes) to the next multiple. For example, if the database block size is 2048 and integer is 2050, Oracle allocates 4096 bytes (2 blocks).The maximum value is 32768 (32 K), which is the largest Oracle block size allowed. Note: The value of CHUNK must be less than or equal to the values of both INITIAL and NEXT (either the default values or those specified in the storage clause). If CHUNK exceeds the value of either INITIAL or NEXT, Oracle returns an error. |
|
|
PCTVERSION integer |
is the maximum percentage of overall LOB storage space used for creating new versions of the LOB. The default value is 10, meaning that older versions of the LOB data rae not overwritten until 10% of the overall LOB storage space is used. |
|
|
INDEX lob_index_name |
is the name of the LOB index segment. You cannot use lob_index_name if more than one lob_item is specified. |
|
MODIFY LOB (lob_item) |
modifies the physical attributes of the LOB attribute lob_item or LOB object attribute. You can only specify one LOB column for each MODIFY LOB clause. See also "LOB Columns". |
|
|
|
||
|
|
specifies storage_table as the name of the storage table in which the rows of all nested_item values reside. You must include this clause when modifying a table with columns or column attributes whose type is a nested table. |
|
|
|
The nested_item is the name of a column or a column-qualified attribute whose type is a nested table. |
|
|
|
The storage_table is the name of the storage table. The storage table is modified in the same schema and the same tablespace as the parent table. See also "Nested Table Columns". |
|
|
drop_clause |
drops an integrity constraint. See the "DROP clause". |
|
|
ALLOCATE EXTENT |
explicitly allocates a new extent for the table, the partition, the overflow data segment, the LOB data segment, or the LOB index. |
|
|
|
SIZE |
specifies the size of the extent in bytes. You can use K or M to specify the extent size in kilobytes or megabytes. If you omit this parameter, Oracle determines the size based on the values of the table's overflow data segment's, or LOB index's STORAGE parameters. |
|
|
DATAFILE |
specifies one of the datafiles in the tablespace of the table, overflow data segment, LOB data tablespace, or LOB index to contain the new extent. If you omit this parameter, Oracle chooses the datafile. |
|
|
INSTANCE |
makes the new extent available to the freelist group associated with the specified instance. If the instance number exceeds the maximum number of freelist groups, the former is divided by the latter, and the remainder is used to identify the freelist group to be used. An instance is identified by the value of its initialization parameter INSTANCE_NUMBER. If you omit this parameter, the space is allocated to the table, but is not drawn from any particular freelist group. Rather, the master freelist is used, and space is allocated as needed. For more information, see Oracle8 Concepts. Use this parameter only if you are using Oracle with the Parallel Server option in parallel mode. |
|
|
Explicitly allocating an extent with this clause does affect the size for the next extent to be allocated as specified by the NEXT and PCTINCREASE storage parameters. |
|
|
DEALLOCATE UNUSED |
explicitly deallocates unused space at the end of the table, partition, overflow data segment, LOB data segment, or LOB index and makes the space available for other segments. You can free only unused space above the high-water mark. If KEEP is omitted, all unused space is freed. For more information, see "DEALLOCATE UNUSED clause". |
|
|
|
KEEP |
specifies the number of bytes above the high-water mark that the table, overflow data segment, LOB data segment, or LOB index will have after deallocation. If the number of remaining extents are less than MINEXTENTS, then MINEXTENTS is set to the current number of extents. If the initial extent becomes smaller than INITIAL, then INITIAL is set to the value of the current initial extent. |
|
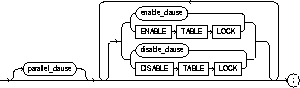
enable_clause |
enables a single integrity constraint or all triggers associated with the table. See the "ENABLE clause". |
|
|
CACHE |
for data that is accessed frequently, specifies that the blocks retrieved for this table are placed at the most recently used end of the LRU list in the buffer cache when a full table scan is performed. This option is useful for small lookup tables. CACHE is not a valid option for index-organized tables. |
|
|
NOCACHE |
for data that is not accessed frequently, specifies that the blocks retrieved for this table are placed at the least recently used end of the LRU list in the buffer cache when a full table scan is performed. For LOBs, the LOB value is either not brought into the buffer cache or brought into the buffer cache and placed at the least recently used end of the LRU list. (The latter is the default behavior.) |
|
|
|
NOCACHE is not a valid option for index-organized tables. |
|
|
LOGGING/NOLOGGING |
LOGGING/NOLOGGING specifies that subsequent Direct Loader (SQL*Loader) and direct-load INSERT operations against a nonpartitioned table, table partition, or all partitions of a partitioned table will be logged (LOGGING) or not logged (NOLOGGING) in the redo log file. When used with the modify_default_attributes_clause, this option affects the logging attribute of a partitioned table. |
|
|
|
LOGGING/NOLOGGING also specifies whether ALTER TABLE...MOVE and ALTER TABLE...SPLIT operations will be logged or not logged. |
|
|
|
In NOLOGGING mode, data is modified with minimal logging (to mark new extents invalid and to record dictionary changes). When applied during media recovery, the extent invalidation records mark a range of blocks as logically corrupt, because the redo data is not logged. Therefore, if you cannot afford to lose this table, it is important to take a backup after the NOLOGGING operation. |
|
|
|
If the database is run in ARCHIVELOG mode, media recovery from a backup taken before the LOGGING operation will restore the table. However, media recovery from a backup taken before the NOLOGGING operation will not restore the table. |
|
|
|
The logging attribute of the base table is independent of that of its indexes. |
|
|
|
For more information about the LOGGING option and Parallel DML, see Oracle8 Parallel Server Concepts & Administration. |
|
|
|
NOLOGGING is not a valid keyword for altering index-organized tables. |
|
|
RENAME TO |
renames table to new_table_name. |
|
|
partitioning_clauses |
See also "Modifying Table Partitions". |
|
|
MODIFY PARTITION [table partitions] |
modifies the real physical attributes of a table partition partition_name. You can specify any of the following as new physical attributes for the partition: the logging attribute; PCTFREE, PCTUSED, INITRANS, or MAXTRANS parameter; or storage parameters. |
|
|
MODIFY PARTITION [index partitions] |
modifies the attributes of an index partition partition_name. Note that you cannot specify the following options with clauses of the MODIFY PARTITION [table partitions] option. |
|
|
|
UNUSABLE LOCAL INDEXES |
marks all the local index partitions associated with partition_name as unusable. |
|
|
REBUILD UNUSABLE LOCAL INDEXES |
rebuilds the unusable local index partitions associated with partition_name. |
|
RENAME PARTITION |
renames table partition current_name to new_name. |
|
|
MOVE PARTITION |
moves table partition partition_name to another segment. You can move partition data to another tablespace, recluster data to reduce fragmentation, or change a create-time physical attribute. |
|
|
ADD PARTITION |
adds a new partition new_partition_name to the "high" end of a partitioned table. You can specify any of the following as new physical attributes for the partition: the logging attribute; the PCTFREE, PCTUSED, INITRANS, or MAXTRANS parameter; or storage parameters. |
|
|
|
VALUES LESS THAN (value_list) |
specifies the upper bound for the new partition. The value_list is a comma-separated, ordered list of literal values corresponding to column_list. The value_list must collate greater than the partition bound for the highest existing partition in the table. |
|
DROP PARTITION |
removes partition partition_name, and the data in that partition, from a partitioned table. |
|
|
TRUNCATE PARTITION |
removes all rows from the partition partition_name in a table. |
|
|
|
DROP STORAGE |
specifies that space from the deleted rows be deallocated and made available for use by other schema objects in the tablespace. |
|
|
REUSE STORAGE |
specifies that space from the deleted rows remains allocated to the partition. The space is subsequently available only for inserts and updates to the same partition. |
|
SPLIT PARTITION |
from an original partition partition_name_old, creates two new partitions, each with a new segment and new physical attributes, and new initial extents. The segment associated with partition_name_old is discarded. |
|
|
|
AT (value_list) |
specifies the new noninclusive upper bound for split_partition_1. The value_list must compare less than the pre-split partition bound for partition_name_old and greater than the partition bound for the next lowest partition (if there is one). |
|
|
INTO |
describes the two partitions resulting from the split. |
|
|
partition_description, partition_description |
specifies optimal names and physical attributes of the two partitions resulting from the split. |
|
EXCHANGE PARTITION |
converts partition partition_name into a nonpartitioned table, and a nonpartitioned table into a partition of a partitioned table by exchanging their data (and index) segments. The default behavior is EXCLUDING INDEXES WITH VALIDATION. |
|
|
|
WITH TABLE table |
specifies the table with which the partition will be exchanged. |
|
|
INCLUDING INDEXES |
specifies that the local index partitions be exchanged with the corresponding regular indexes. |
|
|
EXCLUDING INDEXES |
specifies that all the local index partitions corresponding to the partition and all the regular indexes on the exchanged table are marked as unusable. |
|
|
WITH VALIDATION |
specifies that any rows in the exchanged table that do not collate properly return an error. |
|
|
WITHOUT VALIDATION |
specifies that the proper collation of rows in the exchanged table is not checked. |
|
parallel_clause |
specifies the degree of parallelism for the table. PARALLEL is not a valid option for index-organized tables. See the "PARALLEL clause". |
|
|
|
ENABLE TABLE LOCK |
enables DML and DDL locks on a table in a parallel server environment. For more information, see Oracle8 Parallel Server Concepts & Administration. |
|
|
disable_clause |
disables a single integrity constraint or all triggers associated with the tables. See the "DISABLE clause". |
|
|
|
Integrity constraints specified in DISABLED clauses must be defined in the ALTER TABLE statements or in a previously issued statement. You can also enable and disable integrity constraints with the ENABLE and DISABLE keywords of the CONSTRAINT clause. If you define an integrity constraint but do not explicitly enable or disable it, Oracle enables it by default. |
|
|
DISABLE TABLE LOCK |
disables DML and DDL locks on a table to improve performance in a parallel server environment. For more information, see Oracle8 Parallel Server Concepts & Administration.. |
If you use the ADD clause to add a new column to the table,
then the initial value of each row for the new column is null. You can
add a column with a NOT NULL constraint only to a table that contains no
rows.
If you create a view with a query that uses the asterisk
(*) in the select list to select all columns from the base table and you
subsequently add columns to the base table, Oracle will not automatically
add the new column to the view. To add the new column to the view, you
can re-create the view using the CREATE VIEW command with the OR REPLACE
option.
Operations performed by the ALTER TABLE command can cause
Oracle to invalidate procedures and stored functions that access the table.
For information on how and when Oracle invalidates such objects, see Oracle8
Concepts.
You can use the MODIFY clause to change any of the following
parts of a column definition: datatype, size, default value, or NOT NULL
column constraint.
The MODIFY clause need only specify the column name and the
modified part of the definition, rather than the entire column definition.
You can change a CHAR column to VARCHAR2 (or VARCHAR) and
a VARCHAR2 (or VARCHAR) to CHAR only if the column contains nulls in all
rows or if you do not attempt to change the column size. You can change
any column's datatype or decrease any column's size if all rows for the
column contain nulls. However, you can always increase the size of a character
or raw column or the precision of a numeric column.
You cannot change a column's datatype to a LOB or REF datatype.
A change to a column's default value only affects rows subsequently
inserted into the table. Such a change does not change default values previously
inserted.
To discontinue previously specified default values, so that they are no longer automatically inserted into newly added rows, replace the values with nulls, as shown in this example:
ALTER TABLE accounts MODIFY (bal DEFAULT NULL);
This statement has no effect on any existing values in existing
rows.
The only type of integrity constraint that you can add to
an existing column using the MODIFY clause with the column constraint syntax
is a NOT NULL constraint. However, you can define other types of integrity
constraints (UNIQUE, PRIMARY KEY, referential integrity, and CHECK constraints)
on existing columns using the ADD clause and the table constraint syntax.
You can define a NOT NULL constraint on an existing column
only if the column contains no nulls.
The following statement adds a column named THRIFTPLAN of datatype NUMBER with a maximum of seven digits and two decimal places and a column named LOANCODE of datatype CHAR with a size of one and a NOT NULL integrity constraint:
ALTER TABLE emp ADD (thriftplan NUMBER(7,2), loancode CHAR(1) NOT NULL);
The following statement increases the size of the THRIFTPLAN column to nine digits:
ALTER TABLE emp MODIFY (thriftplan NUMBER(9,2));
Because the MODIFY clause contains only one column definition,
the parentheses around the definition are optional.
The following statement changes the values of the PCTFREE and PCTUSED parameters for the EMP table to 30 and 60, respectively:
ALTER TABLE emp PCTFREE 30 PCTUSED 60;
The following statement allocates an extent of 5 kilobytes for the EMP table and makes it available to instance 4:
ALTER TABLE emp ALLOCATE EXTENT (SIZE 5K INSTANCE 4);
Because this command omits the DATAFILE parameter, Oracle
allocates the extent in one of the datafiles belonging to the tablespace
containing the table.
This example modifies the BAL column of the ACCOUNTS table so that it has a default value of 0:
ALTER TABLE accounts MODIFY (bal DEFAULT 0);
If you subsequently add a new row to the ACCOUNTS table and do not specify a value for the BAL column, the value of the BAL column is automatically 0:
INSERT INTO accounts(accno, accname) VALUES (accseq.nextval, 'LEWIS') SELECT * FROM accounts WHERE accname = 'LEWIS'; ACCNO ACCNAME BAL ------ ------- --- 815234 LEWIS 0
Index-organized tables are special kinds of tables that keep
data sorted on the primary key and are therefore best suited for primary-key-based
access and manipulation.
You cannot ADD columns to an index-organized table, but you
can alter the definition of an index-organized table.
This example modifies the INITRANS parameter for the index segment of index-organized table DOCINDEX:
ALTER TABLE docindex INITRANS 4;
The following statement adds an overflow data segment to index-organized table DOCINDEX:
ALTER TABLE docindex ADD OVERFLOW;
This example modifies the INITRANS parameter for the overflow data segment of index-organized table DOCINDEX:
ALTER TABLE docindex OVERFLOW INITRANS 4;
You can add a LOB column to a table, or modify the LOB data
segment or index storage characteristics.
The following statement adds CLOB column RESUME to the EMPLOYEE table:
ALTER TABLE employee ADD (resume CLOB) LOB (resume) STORE AS resume_seg (TABLESPACE resume_ts);
To modify the LOB column RESUME to use caching, enter the following statement:
ALTER TABLE employee MODIFY LOB (resume) (CACHE);
 Nested Table Columns
Nested Table ColumnsYou can add a nested table type column to a table. Specify
a nested table storage clause for each column added.
The following example adds the nested table column SKILLS to the EMPLOYEE table:
ALTER TABLE employee ADD (skills skill_table_type) NESTED TABLE skills STORE AS nested_skill_table;
You can also modify a nested table's storage characteristics.
Use the name of the storage table specified in the nested table storage
clause to make the modification. You cannot query or perform DML
statements on the storage table; only use the storage table to modify the
nested table column storage characteristics.
 The following example creates table
VETSERVICE with nested table column CLIENT and storage table CLIENT_TAB.
Nested table VETSERVICE is modified to specify constraints and modify a
column length by altering nested storage table CLIENT_TAB:
The following example creates table
VETSERVICE with nested table column CLIENT and storage table CLIENT_TAB.
Nested table VETSERVICE is modified to specify constraints and modify a
column length by altering nested storage table CLIENT_TAB:
CREATE TABLE vetservice (vet_name VARCHAR2(30), client pet_table) NESTED TABLE client STORE AS client_tab; ALTER TABLE client_tab ADD UNIQUE (ssn); ALTER TABLE client_tab MODIFY (pet_name VARCHAR2(35));
 The following statement adds a UNIQUE
constraint to nested table NESTED_SKILL_TABLE:
The following statement adds a UNIQUE
constraint to nested table NESTED_SKILL_TABLE:
ALTER TABLE nested_skill_table ADD UNIQUE (a);
For more information about nested table storage see the "CREATE
TABLE". For more information about nested tables, see Oracle8
Application Developer's Guide.
The following example alters the storage table for a nested table of REF values to specify that the REF is scoped:
CREATE TYPE emp_t AS OBJECT ( eno number, ename char(31)); CREATE TYPE emps_t AS TABLE OF REF emp_t; CREATE TABLE emptab OF emp_t; CREATE TABLE dept (dno NUMBER, employees EMPS_T) NESTED TABLE employees STORE AS deptemps; ALTER TABLE deptemps ADD(SCOPE FOR (column_value) IS emptab);
Similarly, to specify storing the REF with ROWID:
ALTER TABLE deptemps ADD (REF(column_value) WITH ROWID);
Note that in order to execute these ALTER TABLE statements
successfully, the storage table DEPTEMPS must be empty. Also, note that
because the nested table is defined as a table of scalars (REFs), Oracle
implicitly provides the column name COLUMN_VALUE for the storage table.
 REFs
REFsA REF value is a reference to a row in an object table. A
table can have top-level REF columns or it can have REF attributes embedded
within an object column. In general, if a table has a REF column, each
REF value in the column could reference a row in a different object table.
A SCOPE clause restricts the scope of references to a single table.
Use the ALTER TABLE command to add new REF columns or to
add REF clauses to existing REF columns. You can modify any table, including
named inner nested tables (storage tables). If a REF column is created
WITH ROWID or with a scope table, you cannot modify the column to drop
these options. However, if a table is created without any REF clauses,
you can add them later with an ALTER TABLE statement.
Note: You can add a scope clause to existing REF columns
of a table only if the table is empty. The scope_table_name must
be in your own schema or you must have SELECT privilege on the table, or
the SELECT ANY TABLE system privilege. This privilege is needed only while
altering the table with the REF column.
In the following example an object type DEPT_T has been previously defined. Now, create table EMP as follows:
CREATE TABLE emp (name VARCHAR(100), salary NUMBER, dept REF dept_t);
An object table DEPARTMENTS is created as:
CREATE TABLE departments OF dept_t;
If the DEPARTMENTS table contains all possible departments, the DEPT column in EMP can only refer to rows in the DEPARTMENTS table. This can be expressed as a scope clause on the DEPT column as follows:
ALTER TABLE emp ADD (SCOPE FOR (dept) IS departments);
Note that the above ALTER TABLE statement will succeed only
if the EMP table is empty.
If you want the REF values in the DEPT column of EMP to also store the ROWIDs, issue the following statement:
ALTER TABLE emp ADD (REF(dept) WITH ROWID);
You can modify a table or table partition in any of the following
ways. You cannot combine partition operations with other partition operations
or with operations on the base table in one ALTER TABLE statement.
Use ALTER TABLE ADD PARTITION to add a partition to the high
end of the table (after the last existing partition). If the first element
of the partition bound of the high partition is MAXVALUE, you cannot add
a partition to the table. You must split the high partition.
You can add a partition to a table even if one or more of
the table indexes or index partitions are marked UNUSABLE.
You must use the SPLIT PARTITION clause to add a partition
at the beginning or the middle of the table.
The following example adds partition JAN97 to tablespace TSX:
ALTER TABLE sales ADD PARTITION jan97 VALUES LESS THAN( '970201' ) TABLESPACE tsx;
ALTER TABLE DROP PARTITION drops a partition and its data.
If you want to drop a partition but keep its data in the table, you must
merge the partition into one of the adjacent partitions. For information
about merging two tables partitions, see the Oracle8
Administrator's Guide.
If you drop a partition and later insert a row that would
have belonged to the dropped partition, the row will be stored in the next
higher partition. However, if you drop the highest partition, the insert
will fail because the range of values represented by the dropped partition
is no longer valid for the table.
This statement also drops the corresponding partition in
each local index defined on table. The index partitions are dropped
even if they are marked as unusable.
If there are global indexes defined on table, and
the partition you want to drop is not empty, dropping the partition
marks all the global, nonpartitioned indexes and all the partitions of
global partitioned indexes as unusable.
When a table contains only one partition, you cannot drop
the partition. You must drop the table.
The following example drops partition DEC95:
ALTER TABLE sales DROP PARTITION dec95;
This form of ALTER TABLE converts a partition to a nonpartitioned
table and a NONPARTITIONED table to a partition by exchanging their data
segments. You must have ALTER TABLE privileges on both tables to perform
this operation.
The statistics of the table and partition--including table,
column, index statistics and histograms--are exchanged. The aggregate statistics
of the partitioned table are recalculated.
The logging attribute of the table and partition is exchanged.
The following example converts partition FEB97 to table SALES_FEB97 without exchanging local index partitions with corresponding indexes on SALES_FEB97 and without verifying that data in SALES_FEB97 falls within the bounds of partition FEB97:
ALTER TABLE sales EXCHANGE PARTITION feb97 WITH TABLE sales_feb97 WITHOUT VALIDATION;
Use the MODIFY PARTITION options of ALTER TABLE to
The following example marks all the local index partitions corresponding to the NOV96 partition of the SALES table UNUSABLE:
ALTER TABLE sales MODIFY PARTITION nov96 UNUSABLE LOCAL INDEXES;
The following example rebuilds all the local index partitions that were marked UNUSABLE:
ALTER TABLE sales MODIFY PARTITION jan97 REBUILD UNUSABLE LOCAL INDEXES;
The following example changes MAXEXTENTS and logging attribute for partition BRANCH_NY:
ALTER TABLE branch MODIFY PARTITION branch_ny STORAGE(MAXEXTENTS 75) LOGGING;
This ALTER TABLE option moves a table partition to another
segment. MOVE PARTITION always drops the partition's old segment and creates
a new segment, even if you do not specify a new tablespace.
If partition partition_name is not empty, MOVE PARTITION
marks all corresponding local index partitions and all global nonpartitioned
indexes, and all the partitions of global partitioned indexes as unusable.
ALTER TABLE MOVE PARTITION obtains its parallel attribute
from the PARALLEL clause, if specified. If not specified, the default PARALLEL
attributes of the table, if any, are used. If neither is specified, it
performs the move without using parallelism.
The PARALLEL clause on MOVE PARTITION does not change the
default PARALLEL attributes of table.
The following example moves partition DEPOT2 to tablespace TS094:
ALTER TABLE parts MOVE PARTITION depot2 TABLESPACE ts094 NOLOGGING;
Use the RENAME option of ALTER TABLE to rename a table or
to rename a partition.
The following example renames a table:
ALTER TABLE emp RENAME TO employee;
In the following example, partition EMP3 is renamed:
ALTER TABLE employee RENAME PARTITION emp3 TO employee3;
The SPLIT PARTITION option divides a partition into two partitions.
A new segment is allocated for each partition resulting from the split.
The attributes of the new partitions are inherited from the partition that
was split, except for attributes whose values you explicitly override in
the SPLIT clause. The segment associated with the old partition is discarded.
This statement also performs a matching split on the corresponding
partition in each local index defined on table. The index partitions
are split even if they are marked unusable.
With the exception of the TABLESPACE attribute, the physical
attributes of the LOCAL index partition being split are used for both new
index partitions. If the parent LOCAL index lacks a default TABLESPACE
attribute, new LOCAL index partitions will reside in the same tablespace
as the corresponding newly created partitions of the underlying table.
If you do not specify physical attributes (PCTFREE, PCTUSED,
INITRANS, MAXTRANS, STORAGE) for the new partitions, the current values
of the partition being split are used as the default values for both partitions.
If partition_name is not empty, SPLIT PARTITION marks
all affected index partitions as unusable. This includes all global index
partitions as well as the local index partitions that result from the split.
The PARALLEL clause on SPLIT PARTITION does not change the
default PARALLEL attributes of table.
The following example splits the old partition DEPOT4, creating two new partitions, naming one DEPOT9 and reusing the name of the old partition for the other:
ALTER TABLE parts SPLIT PARTITION depot4 AT ( '40-001' ) INTO ( PARTITION depot4 TABLESPACE ts009 (MINEXTENTS 2), PARTITION depot9 TABLESPACE ts010 ) PARALLEL ( DEGREE 10 );
Use TRUNCATE PARTITION to remove all rows from a partition
in a table. Freed space is deallocated or reused depending on whether DROP
STORAGE or REUSE STORAGE is specified in the clause.
This statement truncates the corresponding partition in each
local index defined on table. The local index partitions are truncated
even if they are marked as unusable. The unusable local index partitions
are marked valid, resetting the UNUSABLE indicator.
If any global indexes are defined on table, and the
partition you want to truncate is not empty, truncating the partition
marks all the global nonpartitioned indexes and all the partitions of global
partitioned indexes as unusable.
If you want to truncate a partition that contains data, you
must first disable any referential integrity constraints on the table.
Alternatively, you can delete the rows and then truncate the partition.
The following example deletes all the data in the SYS_P017 partition and deallocates the freed space:
ALTER TABLE deliveries TRUNCATE PARTITION sys_p017 DROP STORAGE;
For examples of defining integrity constraints with the ALTER
TABLE command, see the "CONSTRAINT clause".
For examples of enabling, disabling, and dropping integrity
constraints and triggers with the ALTER TABLE command, see the "ENABLE
clause", the "DISABLE clause", and the
"DROP clause".
For examples of changing the value of a table's storage parameters,
see the "STORAGE clause".
To alter an existing tablespace in one of the following ways:
See also "ALTER TABLESPACE".
If you have ALTER TABLESPACE system privilege, you can perform any of this command's operations. If you have MANAGE TABLESPACE system privilege, you can only perform the following operations:
Before you can make a tablespace read-only, the following conditions must be met. Performing this function in restricted mode may help you meet these restrictions, since only users with RESTRICTED SESSION system privilege can be logged on.
filespec: See
"Filespec".
storage_clause:
See "STORAGE clause".
|
tablespace |
is the name of the tablespace to be altered. |
|
|
LOGGING/ NOLOGGING |
specifies the default logging attribute of all tables, indexes, and partitions within the tablespace. The tablespace-level logging attribute can be overridden by logging specifications at the table, index, and partition levels. |
|
|
|
When an existing tablespace logging attribute is changed by an ALTER TABLESPACE statement, all tables, indexes, and partitions created after the statement will have the new default logging attribute (which you can still subsequently override); the logging attributes of existing objects are not changed. |
|
|
|
Only the following operations support NOLOGGING mode: |
|
|
|
||
|
|
In NOLOGGING mode, data is modified with minimal logging (to mark new extents invalid and to record dictionary changes). When applied during media recovery, the extent invalidation records mark a range of blocks as logically corrupt, because the redo data is not logged. Therefore, if you cannot afford to lose the object, it is important to take a backup after the NOLOGGING operation. |
|
|
ADD DATAFILE |
adds the datafile specified by filespec to the tablespace. (See the syntax description of "Filespec"). You can add a datafile while the tablespace is online or offline. Be sure that the datafile is not already in use by another database. |
|
|
AUTOEXTEND |
enables or disables the autoextending of the size of the datafile in the tablespace. |
|
|
|
OFF |
disables autoextend if it is turned on. NEXT and MAXSIZE are set to zero. Values for NEXT and MAXSIZE must be respecified in further ALTER TABLESPACE AUTOEXTEND commands. |
|
|
ON |
enables autoextend. |
|
|
NEXT |
specifies the size in bytes of the next increment of disk space to be allocated automatically to the datafile when more extents are required. You can use K or M to specify this size in kilobytes or megabytes. The default is one data block. |
|
|
MAXSIZE |
specifies maximum disk space allowed for automatic extension of the datafile. |
|
|
UNLIMITED |
sets no limit on allocating disk space to the datafile. |
|
RENAME DATAFILE |
renames one or more of the tablespace's datafiles. Take the tablespace offline before renaming the datafile. Each 'filename' must fully specify a datafile using the conventions for filenames on your operating system. |
|
|
|
This clause only associates the tablespace with the new file rather than the old one. This clause does not actually change the name of the operating system file. You must change the name of the file through your operating system. |
|
|
COALESCE |
for each datafile in the tablespace, coalesces all contiguous free extents into larger contiguous extents. |
|
|
|
COALESCE cannot be specified with any other command option. |
|
|
DEFAULT storage_clause |
specifies the new default storage parameters for objects subsequently created in the tablespace. See the "STORAGE clause". |
|
|
MINIMUM EXTENT integer |
controls free space fragmentation in the tablespace by ensuring that every used and/or free extent size in a tablespace is at least as large as, and is a multiple of, integer. For more information about using MINIMUM EXTENT to control space fragmentation, see Oracle8 Administrator's Guide. |
|
|
ONLINE |
brings the tablespace online. |
|
|
OFFLINE |
takes the tablespace offline and prevents further access to its segments. |
|
|
|
NORMAL |
performs a checkpoint for all datafiles in the tablespace. All of these datafiles must be online. This is the default. You need not perform media recovery on this tablespace before bringing it back online. You must use this option if the database is in NOARCHIVELOG mode. |
|
|
TEMPORARY |
performs a checkpoint for all online datafiles in the tablespace but does not ensure that all files can be written. Any offline files may require media recovery before you bring the tablespace back online. |
|
|
IMMEDIATE |
does not ensure that tablespace files are available and does not perform a checkpoint. You must perform media recovery on the tablespace before bringing it back online. |
|
|
FOR RECOVER |
takes the production database tablespaces in the recovery set offline. Use this option when one or more datafiles in the tablespace are unavailable. |
|
Suggestion: Before taking a tablespace offline for a long time, you may want to alter any users who have been assigned the tablespace as either a default or temporary tablespace. When the tablespace is offline, these users cannot allocate space for objects or sort areas in the tablespace. You can reassign to such users new default and temporary tablespaces with the ALTER USER command. |
||
|
BEGIN BACKUP |
signifies that an open backup is to be performed on the datafiles that make up this tablespace. This option does not prevent users from accessing the tablespace. You must use this option before beginning an open backup. You cannot use this option on a read-only tablespace. |
|
|
|
Note: While the backup is in progress, you cannot: take the tablespace offline normally, shutdown the instance, or begin another backup of the tablespace. |
|
|
END BACKUP |
signifies that an open backup of the tablespace is complete. Use this option as soon as possible after completing an open backup. You cannot use this option on a read-only tablespace. If you forget to indicate the end of an online tablespace backup, and an instance failure or SHUTDOWN ABORT occurs, Oracle assumes that media recovery (possibly requiring archived redo log) is necessary at the next instance start up. To restart the database without media recovery, see Oracle8 Administrator's Guide. |
|
|
READ ONLY |
signifies that no further write operations are allowed on the tablespace. The tablespace becomes read only. Once a tablespace is read-only, you can copy its files to read-only media. You must then rename the datafiles in the control file to point to the new location by using the SQL command ALTER DATABASE RENAME. |
|
|
READ WRITE |
signifies that write operations are allowed on a previously read-only tablespace. |
|
|
PERMANENT |
specifies that the tablespace is to be converted from a temporary to a permanent one. A permanent tablespace is one wherein permanent database objects can be stored. This is the default when a tablespace is created. |
|
|
TEMPORARY |
specifies that the tablespace is to be converted from a permanent to a temporary one. A temporary tablespace is one in which no permanent database objects can be stored. |
|
The following examples illustrate the use of the ALTER TABLESPACE
COMMAND.
The following statement signals to the database that a backup is about to begin:
ALTER TABLESPACE accounting BEGIN BACKUP;
The following statement signals to the database that the backup is finished:
ALTER TABLESPACE accounting END BACKUP;
This example moves and renames a datafile associated with the ACCOUNTING tablespace from 'DISKA:PAY1.DAT' to 'DISKB:RECEIVE1.DAT':
ALTER TABLESPACE accounting OFFLINE NORMAL;
ALTER TABLESPACE accounting RENAME DATAFILE 'diska:pay1.dbf' TO 'diskb:receive1.dbf';
ALTER TABLESPACE accounting ONLINE;
The following statement adds a datafile to the tablespace and changes the default logging attribute to NOLOGGING; when more space is needed new extents of size 10 kilobytes will be added up to a maximum of 100 kilobytes:
ALTER TABLESPACE accounting NOLOGGING ADD DATAFILE 'disk3:pay3.dbf' AUTOEXTEND ON NEXT 10 K MAXSIZE 100 K;
Altering a tablespace logging attribute has no affect on
the logging attributes of the existing schema objects within the tablespace.
The tablespace-level logging attribute can be overridden by logging specifications
at the table, index, and partition levels.
The following statement changes the allocation of every extent of TABSPACE_ST to a multiple of 128K:
ALTER TABLESPACE tabspace_st MINIMUM EXTENT 128K;
To enable, disable, or compile a database trigger.
The trigger must be in your own schema or you must have ALTER
ANY TRIGGER system privilege.
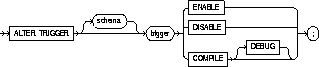
|
schema |
is the schema containing the trigger. If you omit schema, Oracle assumes the trigger is in your own schema. |
|
|
trigger |
is the name of the trigger to be altered. See also "Invalid Triggers". |
|
|
ENABLE |
enables the trigger. See also "Enabling and Disabling Triggers". |
|
|
DISABLE |
disables the trigger. See also "Enabling and Disabling Triggers". |
|
|
COMPILE |
compiles the trigger. |
|
|
|
DEBUG |
instructs the PL/SQL compiler to generate and store the code for use by the PL/SQL debugger. This option can be used for normal triggers and for instead-of triggers. |
You can use the ALTER TRIGGER command to explicitly recompile
a trigger that is invalid. Explicit recompilation eliminates the need for
implicit run-time recompilation and prevents associated run-time compilation
errors and performance overhead.
When you issue an ALTER TRIGGER statement, Oracle recompiles
the trigger regardless of whether it is valid or invalid.
When you recompile a trigger, Oracle first recompiles objects
upon which the trigger depends, if any of these objects are invalid. If
Oracle recompiles the trigger successfully, the trigger becomes valid.
If recompiling the trigger results in compilation errors, then Oracle returns
an error and the trigger remains invalid. You can then debug triggers using
the predefined package DBMS_OUTPUT. For information on debugging procedures,
see Oracle8 Application Developer's
Guide. For information on how Oracle maintains dependencies among
schema objects, including remote objects, see Oracle8
Concepts.
|
Note: This command does not change the declaration or definition of an existing trigger. To redeclare or redefine a trigger, you must use the CREATE TRIGGER command with the OR REPLACE option. |
A database trigger is always either enabled or disabled.
If a trigger is enabled, Oracle fires the trigger when a triggering statement
is issued. If the trigger is disabled, Oracle does not fire the trigger
when a triggering statement is issued.
When you create a trigger, Oracle enables it automatically.
You can use the ENABLE and DISABLE options of the ALTER TRIGGER command
to enable and disable a trigger.
You can also use the ENABLE and DISABLE clauses of the ALTER
TABLE command to enable and disable all triggers associated with a table.
|
Note: The ALTER TRIGGER command does not change the definition of an existing trigger. To redefine a trigger, you must use the CREATE TRIGGER command with the OR REPLACE option. |
Consider a trigger named REORDER created on the INVENTORY
table. The trigger is fired whenever an UPDATE statement reduces the number
of a particular part on hand below the part's reorder point. The trigger
inserts into a table of pending orders a row that contains the part number,
a reorder quantity, and the current date.
When this trigger is created, Oracle enables it automatically. You can subsequently disable the trigger with the following statement:
ALTER TRIGGER reorder DISABLE;
When the trigger is disabled, Oracle does not fire the trigger
when an UPDATE statement causes the part's inventory to fall below its
reorder point.
After disabling the trigger, you can subsequently enable it with the following statement:
ALTER TRIGGER reorder ENABLE;
After you reenable the trigger, Oracle fires the trigger
whenever a part's inventory falls below its reorder point as a result of
an UPDATE statement. Note that a part's inventory may have fallen below
its reorder point while the trigger was disabled. When you reenable the
trigger, Oracle does not automatically fire the trigger for this part until
another transaction further reduces the inventory.
 ALTER TYPE
ALTER TYPETo recompile the specification and/or body, or to change
the specification of an object type by adding new object member subprogram
specifications.
|
Note: This command is available only if the Oracle objects option is installed on your database server. |
The object type must be in your own schema and you must have
CREATE TYPE or CREATE ANY TYPE system privilege, or you must have ALTER
ANY TYPE system privileges.
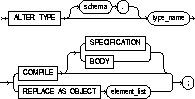
|
schema |
is the schema that contains the type. If you omit schema, Oracle creates the type in your current schema. |
|
|
type_name |
is the name of an object type, a nested table type, or a VARRAY type. |
|
|
COMPILE |
compiles the object type specification and body. This is the default if no option is specified. |
|
|
|
SPECIFICATION |
compiles only the object type specification. |
|
|
BODY |
compiles only the object type body. |
|
REPLACE AS OBJECT |
adds new member subprogram specifications. This option is valid only for object types. |
|
|
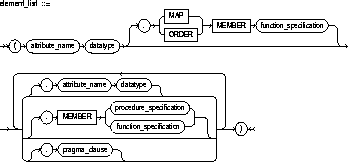
attribute_name |
is an object attribute name. Attributes are data items with a name and a type specifier that form the structure of the object. |
|
|
MAP/ORDER MEMBER function_specification |
||
|
|
MAP |
specifies a member function (MAP method) that returns the relative position of a given instance in the ordering of all instances of the object. A map method is called implicitly and induces an ordering of object instances by mapping them to values of a predefined scalar type. PL/SQL uses the ordering to evaluate Boolean expressions and to perform comparisons. |
|
|
|
A scalar value is always manipulated as a single unit. Scalars are mapped directly to the underlying hardware. An integer, for example, occupies 4 or 8 contiguous bytes of storage, in memory or on disk. |
|
|
|
An object specification can contain only one map method, which must be a function. The result type must be a predefined SQL scalar type, and the map function can have no arguments other than the implicit SELF argument. |
|
|
ORDER |
specifies a member function (ORDER method) that takes an instance of an object as an explicit argument and the implicit SELF argument and returns either a negative, zero, or positive integer. The negative, zero, or positive indicates that the implicit SELF argument is less than, equal to, or greater than the explicit argument. |
|
|
|
When instances of the same object type definition are compared in an ORDER BY clause, the order method function_specification is invoked. |
|
|
|
An object specification can contain only one ORDER method, which must be a function having the return type INTEGER. |
|
|
You can declare either a MAP method or an ORDER method, but not both. If you declare either method, you can compare object instances in SQL. |
|
|
|
If you do not declare either method, you can compare object instances only for equality or inequality. Note that instances of the same type definition are equal only if each pair of their corresponding attributes is equal. No comparison method needs to be specified to determine the equality of two object types. For more information about object value comparisons, "Object Values". |
|
|
MEMBER |
specifies a function or procedure subprogram associated with the object type which is referenced as an attribute. For information about overloading subprogram names within a package, see the PL/SQL User's Guide and Reference. See also "Restriction". You must specify a corresponding method body in the object type body for each procedure or function specification. See "CREATE TYPE BODY" |
|
|
|
procedure_specification |
is the specification of a procedure subprogram. |
|
|
function_specification |
is the specification of a function subprogram. |
|
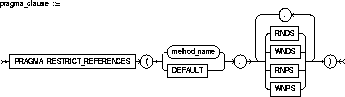
PRAGMA RESTRICT_REFERENCES |
is a complier directive that denies member functions read/write access to database tables, packaged variables, or both, and thereby helps to avoid side effects. For more information, see the PL/SQL User's Guide and Reference. |
|
|
|
method_name |
is the name of the MEMBER function or procedure to which the pragma is being applied. |
|
|
WNDS |
specifies constraint writes no database state (does not modify database tables). |
|
|
WNPS |
specifies constraint writes no package state (does not modify packaged variables). |
|
|
RNDS |
specifies constraint reads no database state (does not query database tables). |
|
|
RNPS |
specifies constraint reads no package state (does not reference packages variables). |
You cannot change the existing properties (attributes, member
subprograms, map or order functions) of an object type, but you can add
new member subprogram specifications.
In the following example, member function QTR is added to the type definition of DATA_T:
CREATE TYPE data_t AS OBJECT ( year NUMBER, MEMBER FUNCTION prod(invent NUMBER) RETURN NUMBER ); CREATE TYPE BODY data_t IS MEMBER FUNCTION prod (invent NUMBER) RETURN NUMBER IS BEGIN RETURN (year + invent); END; END; ALTER TYPE data_t REPLACE AS OBJECT ( year NUMBER, MEMBER FUNCTION prod(invent NUMBER) RETURN NUMBER, MEMBER FUNCTION qtr(der_qtr DATE) RETURN CHAR ); CREATE OR REPLACE TYPE BODY data_t IS MEMBER FUNCTION prod (invent NUMBER) RETURN NUMBER IS BEGIN RETURN (year + invent); END; MEMBER FUNCTION qtr(der_qtr DATE) RETURN CHAR IS BEGIN RETURN 'FIRST'; END; END;
The following example recompiles type LOAN_T:
CREATE TYPE loan_t AS OBJECT ( loan_num INTEGER, interest_rate FLOAT, amount FLOAT, start_date DATE, end_date DATE ); ALTER TYPE loan_t COMPILE;
The following example compiles the type body of LINK2:
CREATE TYPE link1 AS OBJECT (a NUMBER); CREATE TYPE link2 AS OBJECT (a NUMBER, b link1, MEMBER FUNCTION p(c1 NUMBER) RETURN NUMBER); CREATE TYPE BODY link2 AS MEMBER FUNCTION p(c1 NUMBER) RETURN NUMBER IS t13 link1; BEGIN t13 := link1(13); dbms_output.put_line(t13.a); RETURN 5; END; END; CREATE TYPE link3 AS OBJECT (a link2); CREATE TYPE link4 AS OBJECT (a link3); CREATE TYPE link5 AS OBJECT (a link4); ALTER TYPE link2 COMPILE BODY;
The following example compiles the type specification of LINK2:
CREATE TYPE link1 AS OBJECT (a NUMBER); CREATE TYPE link2 AS OBJECT (a NUMBER, b link1, MEMBER FUNCTION p(c1 NUMBER) RETURN NUMBER); CREATE TYPE BODY link2 AS MEMBER FUNCTION p(c1 NUMBER) RETURN NUMBER IS t14 link1; BEGIN t14 := link1(14); dbms_output.put_line(t14.a); RETURN 5; END; END; CREATE TYPE link3 AS OBJECT (a link2); CREATE TYPE link4 AS OBJECT (a link3); CREATE TYPE link5 AS OBJECT (a link4); ALTER TYPE link2 COMPILE SPECIFICATION;
To change any of the following characteristics of a database user:
You must have the ALTER USER system privilege. However, you
can change your own password without this privilege.
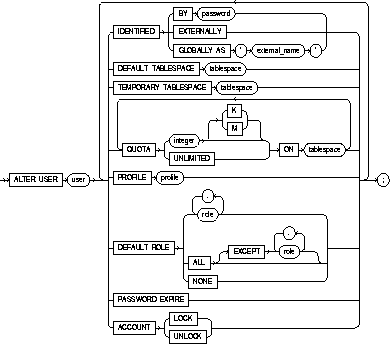
The keywords and parameters in the ALTER USER command all
have the same meaning as in the CREATE USER command. For information on
these keywords and parameters, see "CREATE USER".
For more information on default roles, see "Establishing
Default Roles". For more information on security domains, see "Changing
Authentication Methods".
The DEFAULT ROLE clause can only contain roles that have been granted directly to the user with a GRANT statement. You cannot use the DEFAULT ROLE clause to enable:
Note that Oracle enables default roles at logon without requiring
the user to specify their passwords.
The following statement changes the user SCOTT's password to LION and default tablespace to the tablespace TSTEST:
ALTER USER scott IDENTIFIED BY lion DEFAULT TABLESPACE tstest;
The following statement assigns the CLERK profile to SCOTT:
ALTER USER scott PROFILE clerk;
In subsequent sessions, SCOTT is restricted by limits in
the CLERK profile.
The following statement makes all roles granted directly to SCOTT default roles, except the AGENT role:
ALTER USER scott DEFAULT ROLE ALL EXCEPT agent;
At the beginning of SCOTT's next session, Oracle enables
all roles granted directly to SCOTT except the AGENT role.
You can change a user's access verification method to IDENTIFIED
GLOBALLY AS 'external_name' only if all external roles granted directly
to the user are revoked.
You can change a user created as IDENTIFIED GLOBALLY AS 'external_name'
to IDENTIFIED BY password or IDENTIFIED EXTERNALLY.
The following example changes user TOM's authentication mechanism:
ALTER USER tom IDENTIFIED GLOBALLY AS 'CN=tom';
The following example causes user FRED's password to expire:
ALTER USER fred PASSWORD EXPIRE;
If you cause a database user's password to expire with PASSWORD
EXPIRE, the user must change the password before attempting to log in to
the database following the expiration. However, tools such as SQL*Plus
allow you to change the password on the first attempted login following
the expiration.
To recompile a view or an object view. See also "Recompiling
Views".
|
Note: : Descriptions of commands and clauses preceded by |
The view must be in your own schema or you must have ALTER
ANY TABLE system privilege.
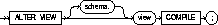
You can use the ALTER VIEW command to explicitly recompile
a view that is invalid. Explicit recompilation allows you to locate recompilation
errors before run time. You may want to explicitly recompile a view after
altering one of its base tables to ensure that the alteration does not
affect the view or other objects that depend on it.
When you issue an ALTER VIEW statement, Oracle recompiles the view regardless of whether it is valid or invalid. Oracle also invalidates any local objects that depend on the view. For more about dependencies among schema objects, see Oracle8 Concepts.
|
Note: This command does not change the definition of an existing view. To redefine a view, you must use the CREATE VIEW command with the OR REPLACE option. |
To recompile the view CUSTOMER_VIEW, issue the following statement:
ALTER VIEW customer_view COMPILE;
If Oracle encounters no compilation errors while recompiling
CUSTOMER_VIEW, CUSTOMER_VIEW becomes valid. If recompiling results in compilation
errors, Oracle returns an error and CUSTOMER_VIEW remains invalid.
Oracle also invalidates all dependent objects. These objects
include any procedures, functions, package bodies, and views that reference
CUSTOMER_VIEW. If you subsequently reference one of these objects without
first explicitly recompiling it, Oracle recompiles it implicitly at run
time.
To perform one of the following functions on an index or index partition, table or table partition, index-organized table, or cluster:
 collect statistics on scalar
object attributes
collect statistics on scalar
object attributes validate and update object
references (REFs)
validate and update object
references (REFs)|
Note: Descriptions of commands and clauses preceded by |
The schema object to be analyzed must be in your own schema
or you must have the ANALYZE ANY system privilege.
If you want to list chained rows of a table or cluster into
a list table, the list table must be in your own schema, or you must have
INSERT privilege on the list table, or you must have INSERT ANY TABLE system
privilege. If you want to validate a partitioned table, you must have INSERT
privilege on the table into which you list analyzed ROWIDS, or you must
have INSERT ANY TABLE system privilege.
See also "Restrictions".

|
schema |
is the schema containing the index, table, or cluster. If you omit schema, Oracle assumes the index, table, or cluster is in your own schema. |
|
|
index |
identifies an index to be analyzed (if no FOR clause is used). |
|
|
table |
identifies a table to be analyzed. When you collect statistics for a table, Oracle also automatically collects the statistics for each of the table's indexes, provided that no FOR clauses are used. |
|
|
PARTITION |
specifies that statistics will be gathered for (partition_name). You cannot use this option when analyzing clusters. |
|
|
cluster |
identifies a cluster to be analyzed. When you collect statistics for a cluster, Oracle also automatically collects the statistics for all the cluster's tables and all their indexes, including the cluster index. See also "Clusters". |
|
|
|
validates the REFs in the specified table, checks the ROWID portion in each REF, compares it with the true ROWID, and corrects, if necessary. You can use this option only when analyzing a table. |
|
|
COMPUTE STATISTICS |
computes exact statistics about the analyzed object and stores them in a data dictionary. See also "Collecting Statistics". |
|
|
ESTIMATE STATISTICS |
estimates statistics about the analyzed object and stores them in the data dictionary. |
|
|
|
SAMPLE |
specifies the amount of data from the analyzed object Oracle samples to estimate statistics. If you omit this parameter, Oracle samples 1064 rows. If you specify more than half of the data, Oracle reads all the data and computes the statistics. |
|
|
ROWS |
causes Oracle to sample integer rows of the table or cluster or integer entries from the index. The integer must be at least 1. |
|
|
PERCENT |
causes Oracle to sample integer percent of the rows from the table or cluster or integer percent of the index entries. The integer can range from 1 to 99. |
|
for_clause |
specifies whether an entire table or index, or just particular columns, will be analyzed. The following clauses apply only to the ANALYZE TABLE version of this command: |
|
|
|
FOR TABLE |
collects table statistics for the table. |
|
|
FOR ALL COLUMNS |
collects column statistics for all columns and scalar object attributes. |
|
|
|
INDEX collects column statistics for all indexed columns in the table. |
|
|
FOR COLUMNS |
collects column statistics for the specified columns and scalar object attributes. |
|
|
|
specifies the qualified column name of an item in an object. |
|
|
FOR ALL INDEXES |
all indexes associated with the table will be analyzed. |
|
|
FOR ALL LOCAL INDEXES |
specifies that all local index partitions are analyzed. You must specify the keyword LOCAL if the PARTITION (partition_name) clause and the index option are specified. |
|
|
SIZE |
specifies the maximum number of partitions in the histogram. The default value is 75, minimum value is 1, and maximum value is 254. |
|
|
Histogram statistics are described in Oracle8 Tuning. See also "Columns". |
|
|
DELETE STATISTICS |
deletes any statistics about the analyzed object that are currently stored in the data dictionary. See also "Deleting Statistics". |
|
|
VALIDATE STRUCTURE |
validates the structure of the analyzed object. If you use this option when analyzing a cluster, Oracle automatically validates the structure of the cluster's tables. If you use this option when analyzing a partitioned table, Oracle also verifies that the row belongs to the correct partition. See also "Validating Structures". |
|
|
|
INTO |
specifies a table into which Oracle lists the ROWIDs of the partitions whose rows do not collate correctly. If you omit schema, Oracle assumes the list is in your own schema. If you omit this clause all together, Oracle assumes that the table is named INVALID_ROWS. The SQL script used to create this table is UTLVALID.SQL. |
|
|
CASCADE |
validates the structure of the indexes associated with the table or cluster. If you use this option when validating a table, Oracle also validates the table's indexes. If you use this option when validating a cluster, Oracle also validates all the clustered tables' indexes, including the cluster index. |
|
LIST CHAINED ROWS |
identifies migrated and chained rows of the analyzed table or cluster. You cannot use this option when analyzing an index. |
|
|
|
INTO |
specifies a table into which Oracle lists the migrated and chained rows. If you omit schema, Oracle assumes the list table is in your own schema. If you omit this clause altogether, Oracle assumes that the table is named CHAINED_ROWS. The script used to create this table is UTLCHAIN.SQL. The list table must be on your local database. |
|
|
To analyze index-organized tables, you must create a separate chained-rows table for each index-organized table created to accommodate the primary key storage of index-organized tables. Use the SQL scripts DBMSIOTC.SQL and PRVTIOTC.PLB to define the BUILD_CHAIN_ROWS_TABLE package, and then execute this procedure to create an IOT_CHAINED_ROWS table for an index-organized table. See also "Listing Chained Rows". |
|
Do not use ANALYZE to collect statistics on data dictionary
tables.
You cannot compute or estimate statistics for the following column types:
You can collect statistics about the physical storage characteristics and data distribution of an index, table, column, or cluster and store them in the data dictionary. For computing or estimating statistics:
Use estimation, rather than computation, unless you feel
you need exact values. Some statistics are always computed exactly, regardless
of whether you specify computation or estimation. If you choose estimation
and the time saved by estimating a statistic is negligible, Oracle computes
the statistic exactly.
If the data dictionary already contains statistics for the
analyzed object, Oracle updates the existing statistics with the new ones.
 The following statement calculates
statistics for a scalar object attribute:
The following statement calculates
statistics for a scalar object attribute:
ANALYZE TABLE emp COMPUTE STATISTICS FOR COLUMNS addr.street;
The statistics are used by the Oracle optimizer to choose
the execution plan for SQL statements that access analyzed objects. These
statistics may also be useful to application developers who write such
statements. For information on how these statistics are used, see Oracle8
Tuning.
The following sections list the statistics for that are collected
for indexes, tables, columns, and clusters. The statistics marked with
asterisks (*) are always computed exactly.
For an index, Oracle collects the following statistics:
Index statistics appear in the data dictionary views USER_INDEXES,
ALL_INDEXES, and DBA_INDEXES.
For a table, Oracle collects the following statistics:
Table statistics appear in the data dictionary views USER_TABLES,
ALL_TABLES, and DBA_TABLES.
Column statistics can be based on the entire column or can
use a histogram. A histogram partitions the values in the column into bands,
so that all column values in a band fall within the same range. In some
cases, it is useful to see how many values fall in various ranges. Oracle's
histograms are height balanced as opposed to width balanced. This means
that the column values are divided into bands so that each band contains
approximately the same number of values. The useful information the histogram
provides, then, is where in the range of values the endpoints fall. Width-balanced
histograms, in contrast, divide the data into a number of ranges, all of
which are the same size, and then count the number of values falling into
each range.
Oracle collects the following column statistics:
For uniformly distributed data, the cost-based approach makes
fairly accurate guesses at the cost of executing a particular statement.
For non-uniformly distributed data, Oracle allows you to store histograms
describing the data distribution of a particular column. These histograms
are stored in the dictionary and can be used by the cost-based optimizer.
Histograms are persistent objects, so there is a maintenance
and space cost for using them. You should compute histograms only for columns
that you know have highly skewed data distribution. Also, be aware that
histograms, as well as all optimizer statistics, are static. If the data
distribution of a column changes frequently, you must reissue the ANALYZE
command to recompute the histogram for that column.
Histograms are not useful for columns with the following characteristics:
Create histograms on columns that are frequently used in WHERE clauses of queries and have a highly skewed data distribution. You create a histogram by using the ANALYZE TABLE command. For example, if you want to create a 10-band histogram on the SAL column of the EMP table, issue the following statement:
ANALYZE TABLE emp COMPUTE STATISTICS FOR COLUMNS sal SIZE 10;
You can also collect histograms for a single partition of a table. The following statement analyzes the EMP table partition P1:
ANALYZE TABLE emp PARTITION (p1) COMPUTE STATISTICS;
Column statistics appear in the data dictionary views: USER_TAB_COLUMNS,
ALL_TAB_COLUMNS, and DBA_TAB_COLUMNS.
Histograms appear in the data dictionary views USER_HISTOGRAMS,
DBA_HISTOGRAMS, and ALL_HISTOGRAMS.
For an indexed cluster, Oracle collects the average number
of data blocks taken up by a single cluster key value and all of its rows.
For a hash clusters, Oracle collects the average number of data blocks
taken up by a single hash key value and all of its rows. These statistics
appear in the data dictionary views USER_CLUSTERS and DBA_CLUSTERS.
The following statement estimates statistics for the CUST_HISTORY table and all of its indexes:
ANALYZE TABLE cust_history ESTIMATE STATISTICS;
With the DELETE STATISTICS option of the ANALYZE command,
you can remove existing statistics about an object from the data dictionary.
You may want to remove statistics if you no longer want the Oracle optimizer
to use them.
When you use the DELETE STATISTICS option on a table, Oracle
also automatically removes statistics for all the table's indexes. When
you use the DELETE STATISTICS option on a cluster, Oracle also automatically
removes statistics for all the cluster's tables and all their indexes,
including the cluster index.
The following statement deletes statistics about the CUST_HISTORY table and all its indexes from the data dictionary:
ANALYZE TABLE cust_history DELETE STATISTICS;
With the VALIDATE STRUCTURE option of the ANALYZE command,
you can verify the integrity of the structure of an index, table, or cluster.
If Oracle successfully validates the structure, a message confirming its
validation is returned to you. If Oracle encounters corruption in the structure
of the object, an error message is returned to you. In this case, drop
and re-create the object.
Validating the structure of a object prevents SELECT, INSERT,
UPDATE, and DELETE statements from concurrently accessing the object. Therefore,
do not use this option on the tables, clusters, and indexes of your production
applications during periods of high database activity.
For an index, the VALIDATE STRUCTURE option verifies the
integrity of each data block in the index and checks for block corruption.
Note that this option does not confirm that each row in the table has an
index entry or that each index entry points to a row in the table. You
can perform these operations by validating the structure of the table with
the CASCADE option.
When you use the VALIDATE STRUCTURE option on an index, Oracle
also collects statistics about the index and stores them in the data dictionary
view INDEX_STATS. Oracle overwrites any existing statistics about previously
validated indexes. At any time, INDEX_STATS can contain only one row describing
only one index. The INDEX_STATS view is described in the Oracle8
Reference.
The statistics collected by this option are not used by the
Oracle optimizer. Do not confuse these statistics with the statistics collected
by the COMPUTE STATISTICS and ESTIMATE STATISTICS options.
The following statement validates the structure of the index PARTS_INDEX:
ANALYZE INDEX parts_index VALIDATE STRUCTURE;
For a table, the VALIDATE STRUCTURE option verifies the integrity of each of the table's data blocks and rows. You can use the CASCADE option to also validate the structure of all indexes on the table as well and to perform cross-referencing between the table and each of its indexes. For each index, the cross-referencing involves the following validations:
The following statement analyzes the EMP table and all of its indexes:
ANALYZE TABLE emp VALIDATE STRUCTURE CASCADE;
 For a table, the VALIDATE REF UPDATE
option verifies the REFs in the specified table, checks the ROWID portion
of each REF, and then compares it with the true ROWID. If the result is
an incorrect ROWID, the REF is updated so that the ROWID portion is correct.
For a table, the VALIDATE REF UPDATE
option verifies the REFs in the specified table, checks the ROWID portion
of each REF, and then compares it with the true ROWID. If the result is
an incorrect ROWID, the REF is updated so that the ROWID portion is correct.
 The following statement validates
the REFs in the EMP table:
The following statement validates
the REFs in the EMP table:
ANALYZE TABLE emp VALIDATE REF UPDATE;
For a cluster, the VALIDATE STRUCTURE option verifies the
integrity of each row in the cluster and automatically validates the structure
of each of the cluster's tables. You can use the CASCADE option to also
validate the structure of all indexes on the cluster's tables as well,
including the cluster index.
The following statement analyzes the ORDER_CUSTS cluster, all of its tables, and all of their indexes, including the cluster index:
ANALYZE CLUSTER order_custs VALIDATE STRUCTURE CASCADE;
There is no rule-based optimizer for partitioned tables,
so it is important to analyze partitioned tables and indexes regularly.
For a partitioned table, the VALIDATE STRUCTURE option verifies
each row in the partition to verify whether the column values of the partitioning
columns collate less than the partition bound of that partition and greater
than the partition bound of the previous partition (except the first partition).
If the row does not collate correctly, the ROWID is inserted into the INVALID_ROWS
table.
With the LIST option of the ANALYZE command, you can collect
information about the migrated and chained rows in a table or cluster.
A migrated row is one that has been moved from one data block to
another. For example, Oracle migrates a row in a cluster if its cluster
key value is updated. A chained row is one that is contained in
more than one data block. For example, Oracle chains a row of a table or
cluster if the row is too long to fit in a single data block. Migrated
and chained rows may cause excessive I/O. You may want to identify such
rows to eliminate them. For information on eliminating migrated and chained
rows, see Oracle8 Tuning.
You can use the INTO clause to specify an output table into
which Oracle places this information. The definition of a sample output
table CHAINED_ROWS is provided in a SQL script available on your distribution
media. Your list table must have the same column names, types, and sizes
as the CHAINED_ROWS table. On many operating systems, the name of this
script is UTLCHAIN.SQL. The actual name and location of this script depends
on your operating system.
The following statement collects information about all the chained rows of the table ORDER_HIST:
ANALYZE TABLE order_hist LIST CHAINED ROWS INTO cr;
The preceding statement places the information into the table CR. You can then examine the rows with this query:
SELECT * FROM cr OWNER_NAME TABLE_NAME CLUSTER_NAME HEAD_ROWID TIMESTAMP ---------- ---------- ------------ ------------------ --------- SCOTT ORDER_HIST AAAAZzAABAAABrXAAA 15-MAR-96
To manually archive redo log file groups or to enable or
disable automatic archiving. See also "Restrictions".
The ARCHIVE LOG clause must appear in an ALTER SYSTEM command.
You must have the privileges necessary to issue this statement. For information
on these privileges, see "ALTER SYSTEM".
You must also have the OSDBA or OSOPER role enabled.
You can use most of the options of this clause when your
instance has the database mounted, open or closed. Options that require
your instance to have the database open are noted.
You must archive redo log file groups in the order in which
they are filled. If you specify a redo log file group for archiving with
the LOGFILE parameter, and earlier redo log file groups are not yet archived,
Oracle returns an error. If you specify a redo log file group for archiving
with the CHANGE parameter or CURRENT option, and earlier redo log file
groups are not yet archived, Oracle archives all unarchived groups up to
and including the specified group.
You can also manually archive redo log file groups with the
ARCHIVE LOG Server Manager command. For information on this command, see
the Oracle Server Manager User's Guide.
You can also choose to have Oracle archive redo log files
groups automatically. For information on automatic archiving, see Oracle8
Administrator's Guide. Note that you can always manually archive
redo log file groups regardless of whether automatic archiving is enabled.
The following statement manually archives the redo log file group with the log sequence number 4 in thread number 3:
ALTER SYSTEM ARCHIVE LOG THREAD 3 SEQUENCE 4;
The following statement manually archives the redo log file group containing the redo log entry with the SCN 9356083:
ALTER SYSTEM ARCHIVE LOG CHANGE 9356083;
The following statement manually archives the redo log file group containing a member named 'DISKL:LOG6.LOG' to an archived redo log file in the location 'DISKA:[ARCH$]':
ALTER SYSTEM ARCHIVE LOG LOGFILE 'diskl:log6.log' TO 'diska:[arch$]';
To choose specific SQL statements for auditing in subsequent
user sessions. To choose particular schema objects for auditing, see "AUDIT
(Schema Objects)". See also "Auditing".
|
Note: Descriptions of commands and clauses preceded by |
You must have AUDIT SYSTEM system privilege.
|
statement_opt |
chooses specific SQL statements for auditing. For a list of these statement options and the SQL statements they audit, see the following two tables. See also "Statement Options for Database Objects" and "Statement Options for Commands". |
|
|
system_priv |
chooses SQL statements that are authorized by the specified system privilege for auditing. For a list of all system privileges and the SQL statements that they authorize, see Table 4-11. See also "Shortcuts for System Privileges and Statement Options". |
|
|
BY user |
chooses only SQL statements issued by specified users for auditing. If you omit this clause, Oracle audits all users' statements. |
|
|
BY SESSION |
causes Oracle to write a single record for all SQL statements of the same type issued in the same session. |
|
|
BY ACCESS |
causes Oracle to write one record for each audited statement. |
|
|
|
If you specify statement options or system privileges that audit data definition language (DDL) statements, Oracle automatically audits by access regardless of whether you specify the BY SESSION or BY ACCESS option. |
|
|
|
For statement options and system privileges that audit other types of SQL statements other than DDL, you can specify either the BY SESSION or BY ACCESS option. BY SESSION is the default. |
|
|
WHENEVER SUCCESSFUL |
chooses auditing only for statements that succeed. |
|
|
|
NOT chooses auditing only for statements that fail or result in errors. |
|
|
|
If you omit the WHENEVER clause, Oracle audits SQL statements regardless of success or failure. |
|
Auditing keeps track of operations performed by database users. For each audited operation, Oracle produces an audit record containing this information:
Oracle writes audit records to the audit trail. The audit
trail is a database table that contains audit records. You can review database
activity by examining the audit trail through data dictionary views. For
information on these views, see the Oracle8
Reference.
To generate audit records, you must perform the following
steps:
You must enable auditing by setting the initialization parameter
AUDIT_TRAIL = DB.
To specify auditing options, you must use the AUDIT command.
Auditing options choose which SQL commands, operations, database objects,
and users Oracle audits. After you specify auditing options, they appear
in the data dictionary. For more information on data dictionary views containing
auditing options see the Oracle8 Reference.
You can specify auditing options regardless of whether auditing
is enabled. However, Oracle does not generate audit records until you enable
auditing.
Auditing options specified by the AUDIT command (SQL Statements)
apply only to subsequent sessions, rather than to current sessions.
The following table lists the statement options relating to database objects and the statements that they audit.
The following table lists additional statement options related to commands and the SQL statements and operations that they audit.
To choose auditing for every SQL statement that creates, alters, drops, or sets a role, regardless of whether the statement completes successfully, issue the following statement:
AUDIT ROLE;
To choose auditing for every statement that successfully creates, alters, drops, or sets a role, issue the following statement:
AUDIT ROLE WHENEVER SUCCESSFUL;
To choose auditing for every CREATE ROLE, ALTER ROLE, DROP ROLE, or SET ROLE statement that results in an Oracle error, issue the following statement:
AUDIT ROLE WHENEVER NOT SUCCESSFUL;
To choose auditing for any statement that queries or updates any table, issue the following statement:
AUDIT SELECT TABLE, UPDATE TABLE;
To choose auditing for statements issued by the users SCOTT and BLAKE that query or update a table or view, issue the following statement:
AUDIT SELECT TABLE, UPDATE TABLE BY scott, blake;
To choose auditing for statements issued using the DELETE ANY TABLE system privilege, issue the following statement:
AUDIT DELETE ANY TABLE;
To choose auditing for statements issued using the CREATE ANY DIRECTORY system privilege, issue the following statement:
AUDIT CREATE ANY DIRECTORY;
To choose auditing for CREATE DIRECTORY (and DROP DIRECTORY) statements that do NOT use the CREATE ANY DIRECTORY system privilege, issue the following statement:
AUDIT DIRECTORY;
Oracle provides shortcuts for specifying groups of system privileges and statement options at once. However, Oracle encourages you to choose individual system privileges and statement options for auditing, because these shortcuts may not be supported in future versions of Oracle. The shortcuts are follows:
|
CONNECT |
is equivalent to specifying the CREATE SESSION system privilege. |
|
RESOURCE |
is equivalent to specifying the following system privileges: |
|
|
|
|
DBA |
is equivalent to the SYSTEM GRANT statement option and the following system privileges: |
|
|
|
|
ALL |
equivalent to specifying all statement options shown in Table 4-6, but not the additional statement options shown in Table 4-7. |
|
ALL PRIVILEGES |
is equivalent to specifying all system privileges. |
To choose a specific schema object for auditing. To choose
particular SQL commands for auditing, see "AUDIT
(SQL Statements)".
Auditing keeps track of operations performed by database
users. For a brief conceptual overview of auditing, including how to enable
auditing, see the "AUDIT (SQL Statements)".
Note that auditing options established by the AUDIT command (Schema Objects)
apply to current sessions as well as to subsequent sessions.
The object you choose for auditing must be in your own schema
or you must have AUDIT ANY system privilege. In addition, if the object
you choose for auditing is a directory object, even if you created it,
you must have AUDIT ANY system privilege.
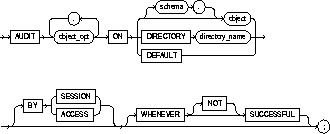
|
object_opt |
specifies a particular operation for auditing. The following table shows each object option and the types of objects to which it applies. See also "Object Options". |
|
|
schema |
is the schema containing the object chosen for auditing. If you omit schema, Oracle assumes the object is in your own schema. |
|
|
object |
identifies the object chosen for auditing. The object must be a table; view; sequence; stored procedure, function, or package; snapshot; or library. |
|
|
|
You can also specify a synonym for a table, view, sequence, procedure, stored function, package, or snapshot. |
|
|
ON DEFAULT |
establishes the specified object options as default object options for subsequently created objects. See also "Default Auditing". |
|
|
DIRECTORY directory_name |
identifies the name of the directory chosen for auditing. |
|
|
BY SESSION |
means that Oracle writes a single record for all operations of the same type on the same object issued in the same session. |
|
|
BY ACCESS |
means that Oracle writes one record for each audited operation. |
|
|
If you omit both of the preceding options, Oracle audits by session. |
||
|
WHENEVER SUCCESSFUL |
chooses auditing only for SQL statements that complete successfully. |
|
|
|
NOT chooses auditing only for statements that fail, or result in errors. |
|
|
|
If you omit the WHENEVER clause entirely, Oracle audits all SQL statements, regardless of success or failure. |
|
The following table shows the object options you can choose
for each type of object.
The name of each object option specifies a command to be
audited. For example, if you choose to audit a table with the ALTER option,
Oracle audits all ALTER TABLE statements issued against the table. If you
choose to audit a sequence with the SELECT option, Oracle audits all statements
that use any of the sequence's values.
Oracle provides a shortcut for specifying object auditing options:
|
ALL |
is equivalent to specifying all object options applicable for the type of object. You can use this shortcut rather than explicitly specifying all options for an object. |
You can use the DEFAULT option of the AUDIT command to specify
auditing options for objects that have not yet been created. Once you have
established these default auditing options, any subsequently created object
is automatically audited with those options. Note that the default auditing
options for a view are always the union of the auditing options for the
view's base tables.
If you change the default auditing options, the auditing
options for previously created objects remain the same. You can change
the auditing options for an existing object only by specifying the object
in the ON clause of the AUDIT command.
To choose auditing for every SQL statement that queries the EMP table in the schema SCOTT, issue the following statement:
AUDIT SELECT ON scott.emp;
To choose auditing for every statement that successfully queries the EMP table in the schema SCOTT, issue the following statement:
AUDIT SELECT ON scott.emp WHENEVER SUCCESSFUL;
To choose auditing for every statement that queries the EMP table in the schema SCOTT and results in an Oracle error, issue the following statement:
AUDIT SELECT ON scott.emp WHENEVER NOT SUCCESSFUL;
To choose auditing for every statement that inserts or updates a row in the DEPT table in the schema BLAKE, issue the following statement:
AUDIT INSERT, UPDATE ON blake.dept;
To choose auditing for every statement that performs any operation on the ORDER sequence in the schema ADAMS, issue the following statement:
AUDIT ALL ON adams.order;
The above statement uses the ALL short cut to choose auditing for the following statements that operate on the sequence:
To choose auditing for every statement that reads files from the BFILE_DIR1 directory, issue the following statement:
AUDIT READ ON DIRECTORY bfile_dir1;
The following statement specifies default auditing options for objects created in the future:
AUDIT ALTER, GRANT, INSERT, UPDATE, DELETE ON DEFAULT;
Any objects created later are automatically audited with the specified options that apply to them, provided that auditing has been enabled:
 are available only if the Oracle objects option is installed on your database
server.
are available only if the Oracle objects option is installed on your database
server.




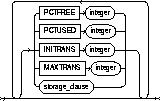 physical_attributes_clause::=
physical_attributes_clause::=
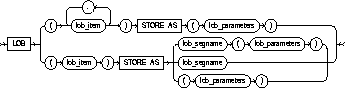 LOB_storage_clause::=
LOB_storage_clause::=
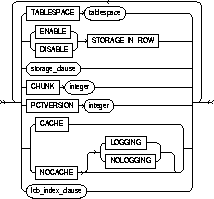 LOB_parameters::=
LOB_parameters::=
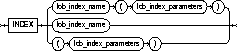 LOB_index_clause::=
LOB_index_clause::=
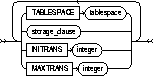 LOB_index_parameters::=
LOB_index_parameters::=
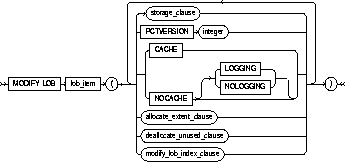 modify_LOB_storage_clause::=
modify_LOB_storage_clause::=
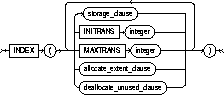 modify_LOB_index_clause::=
modify_LOB_index_clause::=
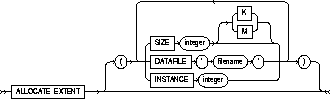 allocate_extent_clause::=
allocate_extent_clause::=
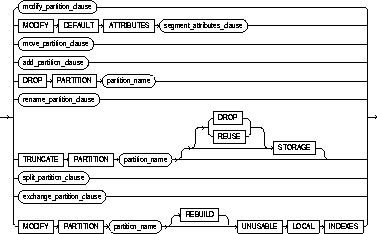 partitioning_clauses::=
partitioning_clauses::=
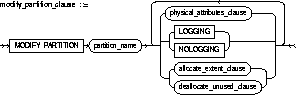



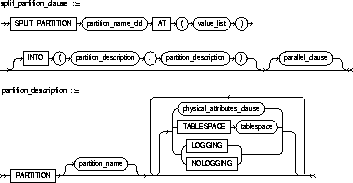
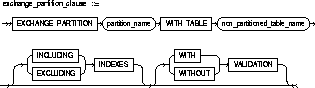
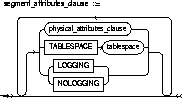
 NESTED TABLE nested_item STORE
AS storage_table
NESTED TABLE nested_item STORE
AS storage_table 
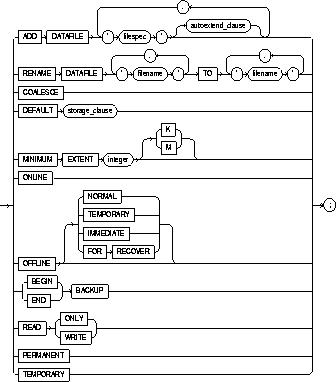
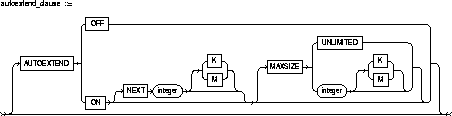
 are available only if the Oracle objects option is installed on your database
server.
are available only if the Oracle objects option is installed on your database
server.
 are only available if the Oracle objects option is installed on your database
server.
are only available if the Oracle objects option is installed on your database
server.
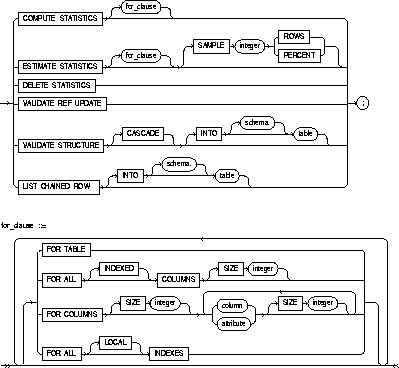
 VALIDATE REF UPDATE
VALIDATE REF UPDATE  attribute
attribute  are available only if the Oracle objects option is installed on your database
server.
are available only if the Oracle objects option is installed on your database
server.
 TYPE
TYPE GRANT TYPE
GRANT TYPE