| Oracle® Database Java Developer's Guide 10g Release 1 (10.1) Part Number B12021-01 |
|





|
View PDF |
| Oracle® Database Java Developer's Guide 10g Release 1 (10.1) Part Number B12021-01 |
|
|
View PDF |
Oracle Database executes standard Java applications. However, by integrating Java classes within the database server, your environment is different from a typical Java development environment. This chapter describes the basic differences for writing, installing, and deploying Java applications within Oracle Database.
The OracleJVM platform is a standard, compatible Java environment, which will execute any 100% pure Java application. It has been implemented by Oracle to be compatible with the Java Language Specification and the Java virtual machine specification. It supports the standard Java binary format and the standard Java APIs. In addition, Oracle Database adheres to standard Java language semantics, including dynamic class loading at runtime.
However, unlike other Java environments, the OracleJVM is embedded within the Oracle Database and, therefore, introduces a number of new concepts. This section summarizes the differences between the Sun Microsystems J2SE environment and the environment that occurs when you combine Java with the Oracle Database.
In your standard Java environment, you run a Java application through the interpreter by executing java <classname>. This causes the application to execute within a process on your operating system.
With the OracleJVM, you must load the application into the database, publish the interface, and then run the application within a database session. This book discusses how to run your Java applications within the database. Specifically, see the following sections for instructions on executing Java in the database:
In addition, certain features, included within standard Java, change when you run your application within a database session. These are covered in the following sections:
Once you are familiar with this chapter, see Chapter 3, "Invoking Java in the Database" for directions on how to set up your client, and examples for invoking different types of Java applications.
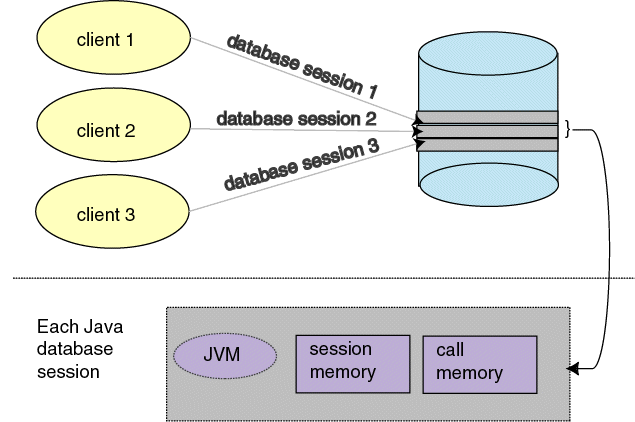
In incorporating Java within Oracle Database, your Java application exists within the context of a database session. OracleJVM sessions are entirely analogous to traditional Oracle sessions. Each OracleJVM session maintains the client's Java state across calls within the session.
Figure 2-1 demonstrates how each Java client starts up a database session as the environment for executing Java within the database. Garbage collection, session memory, and call memory exist solely for each client within its session.
Text description of the illustration au_over.gif
Within the context of a session, the client performs the following:
Within a single session, the client has its own Java environment, which is separate from every other client's environment. It appears to the client as if a separate, individual JVM was invoked for each session, although the implementation is vastly more efficient than this seems to imply. Within a session, the OracleJVM manages the scalability for you within the database. Every call executed from a single client is managed within its own session--separately from other clients. The OracleJVM maximizes sharing read-only data between clients and emphasizes a minimum amount of per-session incremental footprint to maximize performance for multiple clients.
The underlying server environment hides the details associated with session, network, state, and other shared resource management issues from Java server code. Static variables are all local to the client. No client can access another client's static variables, because the memory is not available across session boundaries. Because each client executes its calls within its own session, each client's activities are separate from any other client. During a call, you can store objects in static fields of different classes, and you can expect this state to be available for your next call. The entire state of your Java program is private to you and exists for your entire session.
The OracleJVM manages the following within the session:
For the Oracle Database 10g release, we offer the following Java APIs--Java stored procedures, JNDI, and JDBC.
In the Sun Microsystems J2SE environment, you develop Java applications with a main() method, which is called by the interpreter when the class is run. The main() method is invoked when you execute java <classname> on the command-line. This command starts the java interpreter and passes the desired classname to be executed to the interpreter. The interpreter loads the class and starts the execution by invoking main(). However, Java applications within the database do not start their execution from a main() method.
After loading your Java application within the database (see "Loading Classes"), you can execute your Java code by invoking any static method within the loaded class. The class or methods must be published for you to execute them (see "Publishing"). Your only entry point is no longer always assumed to be main(). Instead, when you execute your Java application, you specify a method name within the loaded class as your entry point.
For example, in a normal Java environment, you would start up the Java object on the server by executing the following:
java myprogram
where myprogram is the name of a class that contains a main() method. In myprogram, main() immediately calls mymethod for processing incoming information.
In Oracle Database, you load the myprogram.class file into the database and publish mymethod as an entry-point. Then, the client or trigger can invoke mymethod explicitly.
In the Sun Microsystems Java development environment, Java source code, binaries, and resources are stored as files in a file system.
In addition, when you execute Java, you specify a CLASSPATH, which is a set of a file system tree roots containing your files. Java also provides a way to group these files into a single archive form--a ZIP or JAR file.
Both of these concepts are different within the database. The following table describes how Oracle Database handles Java classes and locates dependent classes.
The call and session terms, used during our discussions, are not Java terms; but are server terms that apply to the OracleJVM platform. The Oracle Database memory manager preserves Java program state throughout your session (that is, between calls). The JVM uses the Oracle database to hold Java source, classes, and resources within a schema--Java schema objects. You can use a resolver to specify how Java, when executed in the server, locates source code, classes, and resources.
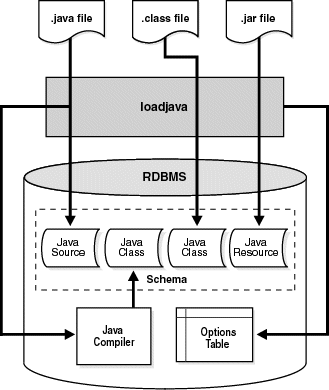
To make Java files available to the OracleJVM, you must load them into the Oracle database as schema objects. As Figure 2-2 illustrates, loadjava can invoke the JVM's Java compiler, which compiles source files into standard class files.
The figure also shows that loadjava can set the values of options stored in a system database table. Among other things, these options affect the processing of Java source files.
Text description of the illustration loading_.gif
Each Java class is stored as a schema object. The name of the object is derived from the fully qualified name (full name) of the class, which includes the names of containing packages. For example, the full name of class Handle is:
oracle.aurora.rdbms.Handle
In the name of a Java schema object, slashes replace dots, so the full name of the class becomes:
oracle/aurora/rdbms/Handle
The Oracle RDBMS accepts Java names up to 4000 characters long. However, the names of Java schema objects cannot be longer than 31 characters, so if a name is longer than that, the system generates an alias (short name) for the schema object. Otherwise, the full name is used. You can specify the full name in any context that requires it. When needed, name mapping is handled by the RDBMS. See "Shortened Class Names" for more information.
For your Java methods to be executed, you must do the following:
Compilation of your source can be performed in one of the following ways:
|
Note: If you decide to compile through loadjava, you can specify compiler options. See "Specifying Compiler Options" for more information. |
You can compile your Java with a conventional Java compiler, such as javac. After compilation, you load the compiled binary into the database, rather than the source itself. This is a better option, because it is normally easier to debug your Java code on your own system, rather than debugging it on the database.
When you specify the -resolve option on loadjava for a source file, the following occurs:
Oracle Database logs all compilation errors both to loadjava's log file and the
USER_ERRORS view.
When you load the Java source into the database without the -resolve option, Oracle Database compiles the source automatically when the class is needed during runtime. The source file is loaded into a source schema object.
Oracle Database logs all compilation errors both to loadjava's log file and the
USER_ERRORS view.
There are two ways to specify options to the compiler.
You must create this table yourself if you wish to specify compiler options this way. See "Compiler Options Specified in a Database Table" for instructions on how to create the JAVA$OPTIONS table.
The following sections describe your compiler options:
When compiling a source schema object for which there is neither a JAVA$OPTIONS entry nor a command line value for an option, the compiler assumes a default value as follows:
The loadjava compiler option, encoding, identifies the encoding of the .java file. This option overrides any matching value in the JAVA$OPTIONS table. The values are identical to the javac -encoding option. This option is relevant only when loading a source file.
Each JAVA$OPTIONS row contains the names of source schema objects to which an option setting applies; you can use multiple rows to set the options differently for different source schema objects.
You can set JAVA$OPTIONS entries by means of the following functions and procedures, which are defined in the database package DBMS_JAVA:
FUNCTION get_compiler_option(name VARCHAR2, option VARCHAR2) RETURNS VARCHAR2;The parameters for these methods are described in the following table:
A schema does not initially have a JAVA$OPTIONS table. To create a JAVA$OPTIONS table, use the DBMS_JAVA package's java.set_compiler_option procedure to set a value. The procedure will create the table if it does not exist. Specify parameters in single quotes. For example:
SQL> execute dbms_java.set_compiler_option('x.y', 'online', 'false');
Table 2-4 represents a hypothetical JAVA$OPTIONS database table. The pattern match rule is to match as much of the schema name against the table entry as possible. The schema name with a higher resolution for the pattern match is the entry that applies. Because the table has no entry for the encoding option, the compiler uses the default or the value specified on the command line. The online option shown in the table matches schema object names as follows:
| Name | Option | Value | Match Examples |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
(empty string) |
|
|
Oracle Database provides a dependency management and automatic build facility that will transparently recompile source programs when you make changes to the source or binary programs upon which they depend. Consider the following cases:
public class A { B b; public void assignB () {b = new B()} } public class B { C c; public void assignC () {c = new C()} } public class C { A a; public void assignA () {a = new A()} } <pre>
The system tracks dependencies at a class level of granularity. In the preceding example, you can see that classes A, B, and C depend on one another, because A holds an instance of B, B holds an instance of C, and C holds an instance of A. If you change the definition of class A by adding a new field to it, the dependency mechanism in Oracle Database flags classes B and C as invalid. Before you use any of these classes again, Oracle Database attempts to resolve them again and recompile, if necessary. Note that classes can be recompiled only if source is present on the server.
The dependency system enables you to rely on Oracle Database to manage dependencies between classes, to recompile, and to resolve automatically. You must force compilation and resolution yourself only if you are developing and you want to find problems early. The loadjava utility also provides the facilities for forcing compilation and resolution if you do not want to allow the dependency management facilities to perform this for you.
Many Java classes contain references to other classes, which is the essence of reusing code. A conventional Java virtual machine searches for classes, ZIP, and JAR files within the directories specified in the CLASSPATH. In contrast, the OracleJVM searches database schemas for class objects. With Oracle Database, you load all Java classes within the database, so you might need to specify where to find the dependent classes for your Java class within the database.
All classes loaded within the database are referred to as class schema objects and are loaded within certain schemas. All JVM classes, such as java.lang.*, are loaded within PUBLIC. If your classes depend upon other classes you have defined, you will probably load them all within your own schema. For example, if your schema is SCOTT, the database resolver (the database replacement for CLASSPATH) searches the SCOTT schema before PUBLIC. The listing of schemas to search is known as a resolver spec. Resolver specs are per-class, whereas in a classic Java virtual machine, CLASSPATH is global to all classes.
When locating and resolving the interclass dependencies for classes, the resolver marks each class as valid or invalid, depending on whether all interdependent classes are located. If the class that you load contains a reference to a class that is not found within the appropriate schemas, the class is listed as invalid. Unsuccessful resolution at runtime produces a "class not found" exception. Furthermore, runtime resolution can fail for lack of database resources if the tree of classes is very large.
|
Note: As with the Java compiler, loadjava resolves references to classes, but not to resources. Be sure to correctly load the resource files that your classes need. |
For each interclass reference in a class, the resolver searches the schemas specified by the resolver spec for a valid class schema object that satisfies the reference. If all references are resolved, the resolver marks the class valid. A class that has never been resolved, or has been resolved unsuccessfully, is marked invalid. A class that depends on a schema object that becomes invalid is also marked invalid.
To make searching for dependent classes easier, Oracle Database provides a default resolver and resolver spec that searches first the definer's schema and then PUBLIC. This covers most of the classes loaded within the database. However, if you are accessing classes within a schema other than your own or PUBLIC, you must define your own resolver spec.
loadjava -resolve
loadjava -resolve -resolver "((* SCOTT)(* OTHER)(* PUBLIC))"
The -resolver option specifies the objects to search within the schemas defined. In the example above, all class schema objects are searched within SCOTT, OTHER, and PUBLIC. However, if you wanted to search for only a certain class or group of classes within the schema, you could narrow the scope for the search. For example, to search only for the classes "my/gui/*" within the OTHER schema, you would define the resolver spec as follows:
loadjava -resolve -resolver '((* SCOTT) ("my/gui/*" OTHER) (* PUBLIC))' <pre>
The first parameter within the resolver spec is for the class schema object; the second parameter defines the schema within which to search for these class schema objects.
You can specify a special option within a resolver spec that allows an unresolved reference to a non-existent class. Sometimes, internal classes are never used within a product. For example, some ISVs do not remove all references to internal test classes from the JAR file before shipping. In a normal Java environment, this is not a problem, because as long as the methods are not called, the Sun Microsystems JVM ignores them. However, the Oracle Database resolver tries to resolve all classes referenced within the JAR file--even unused classes. If the reference cannot be validated, the classes within the JAR file are marked as invalid.
To ignore references, you can specify the "-" wildcard within the resolver spec. The following example specifies that any references to classes within "my/gui" are to be allowed, even if it is not present within the resolver spec schema list.
loadjava -resolve -resolver '((* SCOTT) (* PUBLIC) ("my/gui/*" -))'
In addition, you can define that all classes not found are to be ignored. Without the wildcard, if a dependent class is not found within one of the schemas, your class is listed as invalid and cannot be run. However, this is also dangerous, because if there is a dependent class on a used class, you mark a class as valid that can never run without the dependent class. In this case, you will receive an exception at runtime.
To ignore all classes not found within SCOTT or PUBLIC, specify the following resolver spec:
loadjava -resolve -resolver "((* SCOTT) (* PUBLIC) (* -))"
If you later intend to load the non-existent classes that were causing you to use such a resolver in the first place, you should not use a resolver containing the "-." Instead, include all referenced classes in the schema before resolving.
|
Note: An alternative mechanism for dealing with non-existent classes is with the -gemissing option of loadjava. This option causes loadjava to create and load definitions of classes that are referenced, but not defined. For more details, see "loadjava". |
According to the JVM specification, .class files are subject to verification before the class they define is available in a JVM. In OracleJVM, the verification process occurs at class resolution. The resolver might find one of the following problems and issue the appropriate Oracle error code:
The resolver also issues warnings, as defined below:
This type of resolver marks your class valid regardless of whether classes it references are present. Because of inheritance and interfaces, you may want to write valid Java methods that use an instance of a class as if it were an instance of a superclass or of a specific interface. When the method being verified uses a reference to class A as if it were a reference to class B, the resolver must check that A either extends or implements B. For example, consider the potentially valid method below, whose signature implies a return of an instance of B, but whose body returns an instance of A:
B myMethod(A a) { return a; }
The method is valid only if A extends B, or A implements the interface B. If A or B have been resolved using a "-" term, the resolver does not know that this method is safe. It will replace the bytecodes of myMethod with bytecodes that throw an Exception if myMethod is ever called.
The resolver ensures that the class definitions of A and B are found and resolved properly if they are present in the schemas they specifically identify. The only time you might consider using the alternative resolver is if you must load an existing JAR file containing classes that reference other non-system classes that are not included in the JAR file.
For more information on class resolution and loading your classes within the database, see Chapter 11, "Schema Object Tools".
This section gives an overview of loading your classes into the database using the loadjava tool. You can also execute loadjava within your SQL. See Chapter 11, "Schema Object Tools" for complete information on loadjava.
Unlike a conventional Java virtual machine, which compiles and loads from files, the OracleJVM compiles and loads from database schema objects.
You must load all classes or resources into the database to be used by other classes within the database. In addition, at load time, you define who can execute your classes within the database.
The loadjava tool performs the following for each type of file:
The dropjava tool performs the reverse of the loadjava tool: it deletes schema objects that correspond to Java files. Always use dropjava to delete a Java schema object created with loadjava. Dropping with SQL DDL commands will not update auxiliary data maintained by loadjava and dropjava. You can also execute dropjava from within SQL commands.
|
Note: More options for loadjava are available. However, this section discusses only the major options. See Chapter 11, "Schema Object Tools" for complete information on loadjava and dropjava. |
You must abide by certain rules, which are detailed in the following sections, when loading classes into the database:
After loading, you can access the USER_OBJECTS view in your database schema to verify that your classes and resources loaded properly. For more information, see "Checking Java Uploads".
You cannot have two different definitions for the same class. This rule affects you in two ways:
Oracle Database tracks whether you loaded a class file or a source file. If you wish to update the class, you must load the same type of file that you originally loaded. If you wish to update the other type, you must drop the first before loading the second. For example, if you loaded x.java as the source for class y, to load x.class, you must first drop x.java.
You must have the following SQL database privileges to load classes:
The loadjava tool accepts .class, .java, .properties, .ser, .jar, or .zip files. The JAR or ZIP files can contain source, class, and data files. When you pass loadjava a JAR or ZIP file, loadjava opens the archive and loads its members individually. There is no JAR or ZIP schema object. If the JAR or ZIP content has not changed since the last time it was loaded, it is not reloaded; therefore, there is little performance penalty for loading JAR or ZIP files. In fact, loading JAR or ZIP files is the simplest way to use loadjava.
|
Note: Oracle Database does not reload a class if it has not changed since the last load. However, you can force a class to be reloaded through the loadjava -force option. |
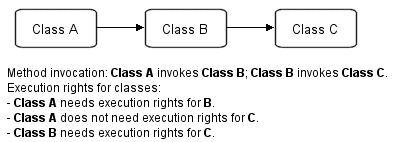
If you load all classes within your own schema and do not reference any class outside of your schema, you already have execution rights. You have the privileges necessary for your objects to invoke other objects loaded in the same schema. That is, the ability for class A to invoke class B. Class A must be given the right to invoke class B.
The classes that define a Java application are stored within Oracle Database under the SQL schema of their owner. By default, classes that reside in one user's schema are not executable by other users, because of security concerns. You can allow other users (schemas) the right to execute your class through the loadjava -grant option. You can grant execution rights to a certain user or schema. You cannot grant execution rights to a role, which includes the super-user DBA role. The setting of execution rights is the same as used to grant or revoke privileges in SQL DDL statements.
Text description of the illustration exeright.gif
For information on JVM security permissions, see Chapter 10, "Oracle Database Java Application Performance".
During execution of Java or PL/SQL, there is always a current user. Initially, this is the user who creates the session.
Invoker's and definer's rights is a SQL concept that is used dynamically when executing SQL, PL/SQL, or JDBC. The current user controls the interpretation of SQL and determines privileges. For example, if a table is referenced by a simple name, it is assumed that the table belongs in the user's schema. In addition, the privileges that are checked when resources are requested are based on the privileges granted to the current user.
In addition, for Java stored procedures, the call specifications use a PL/SQL wrapper. So, you could specify definer's rights on either the call specification or on the Java class itself. If either is redefined to definer's rights, then the called method executes under the user that deployed the Java class.
By default, Java stored procedures execute without changing the current user--that is, with the privileges of their invoker, not their definer. Invoker-rights procedures are not bound to a particular schema. Their unqualified references to schema objects (such as database tables) are resolved in the schema of the current user, not the definer.
On the other hand, definer-rights procedures are bound to the schema in which they reside. They execute with the privileges of their definer, and their unqualified references to schema objects are resolved in the schema of the definer.
Invoker-rights procedures let you reuse code and centralize application logic. They are especially useful in applications that store data in different schemas. In such cases, multiple users can manage their own data using a single code base.
Consider a company that uses a definer-rights procedure to analyze sales. To provide local sales statistics, the procedure analyze must access sales tables that reside at each regional site. To do so, the procedure must also reside at each regional site. This causes a maintenance problem.
To solve the problem, the company installs an invoker-rights (IR) version of the procedure analyze at headquarters. Now, as Figure 2-4 shows, all regional sites can use the same procedure to query their own sales tables.
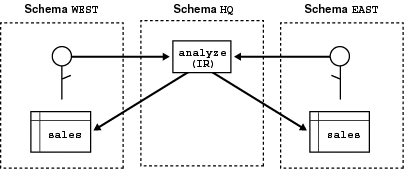
Text description of the illustration invoker_.gif
Occasionally, you might want to override the default invoker-rights behavior. Suppose headquarters would like the procedure analyze to calculate sales commissions and update a central payroll table. That presents a problem because invokers of analyze should not have direct access to the payroll table, which stores employee salaries and other sensitive data. As Figure 2-5 shows, the solution is to have procedure analyze call the definer-rights (DR) procedure calcComm, which, in turn, updates the payroll table.
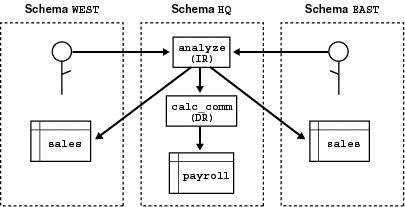
Text description of the illustration controll.gif
To override the default invoker-rights behavior, specify the loadjava option -definer, which is similar to the UNIX facility setuid, except that -definer applies to individual classes, not whole programs. Alternatively, you can execute the SQL DDL that changes the AUTHID of the current user.
Different definers can have different privileges, and applications can consist of many classes. So, use the option -definer carefully, making sure that classes have only the privileges they need.
You can query the database view USER_OBJECTS to obtain information about schema objects--including Java sources, classes, and resources--that you own. This allows you, for example, to verify that sources, classes, or resources that you load are properly stored into schema objects.
Columns in USER_OBJECTS include those contained in Table 2-8 below.
An OBJECT_NAME in USER_OBJECTS is the short name. The full name is stored as a short name if it exceeds 31 characters. See "Shortened Class Names" for more information on full and short names.
If the server uses a short name for a schema object, you can use the LONGNAME() routine of the server DBMS_JAVA package to receive it from a query in full name format, without having to know the short name format or the conversion rules.
SQL> SELECT dbms_java.longname(object_name) FROM user_objects WHERE object_type='JAVA SOURCE';
This routine shows you the Java source schema objects in full name format. Where no short name is used, no conversion occurs, because the short name and full name are identical.
You can use the SHORTNAME() routine of the DBMS_JAVA package to use a full name as a query criterion, without having to know whether it was converted to a short name in the database.
SQL*Plus> SELECT object_type FROM user_objects WHERE object_name=dbms_java.shortname('known_fullname');
This routine shows you the OBJECT_TYPE of the schema object of the specified full name. This presumes that the full name is representable in the database character set.
SQL> select * from javasnm; SHORT LONGNAME ---------------------------------------------------------------------- /78e6d350_BinaryExceptionHandl sun/tools/java/BinaryExceptionHandler /b6c774bb_ClassDeclaration sun/tools/java/ClassDeclaration /af5a8ef3_JarVerifierStream1 sun/tools/jar/JarVerifierStream$1
STATUS is a character string that indicates the validity of a Java schema object. A source schema object is VALID if it compiled successfully; a class schema object is VALID if it was resolved successfully. A resource schema object is always VALID, because resources are not resolved.
The following SQL*Plus script accesses the USER_OBJECTS view to display information about uploaded Java sources, classes, and resources.
COL object_name format a30 COL object_type format a15 SELECT object_name, object_type, status FROM user_objects WHERE object_type IN ('JAVA SOURCE', 'JAVA CLASS', 'JAVA RESOURCE') ORDER BY object_type, object_name;
You can optionally use wildcards in querying USER_OBJECTS, as in the following example.
SELECT object_name, object_type, status FROM user_objects WHERE object_name LIKE '%Alerter';
This routine finds any OBJECT_NAME entries that end with the characters: Alerter.
Oracle Database enables clients and SQL to invoke Java methods that are loaded within the database, once published. You publish either the object itself or individual methods. If you write a Java stored procedure that you intend to invoke with a trigger, directly or indirectly in SQL DML or in PL/SQL, you must publish individual methods within the class. Specify how to access it through a call specification. Java programs consist of many methods in many classes; however, only a few static methods are typically exposed with call specifications. See Chapter 6, "Publishing Java Classes With Call Specs" for more details.
Oracle Database furnishes all core Java class libraries on the server, including those associated with presentation of the user interfaces java.awt and java.applet. It is, however, inappropriate for code executing in the server to attempt to materialize or display a user interface in the server. Users running applications in the OracleJVM should not be expected--nor allowed--to interact with or depend on the display and input hardware of the server on which Oracle Database is running.
To address compatibility on platforms that do not support a display, keyboard, or mouse, Java 1.4 outlines "Headless AWT" support. The Headless AWT API introduces a new public runtime exception class, java.awt.HeadlessException. The constructors of the Applet class, all heavy-weight components, and many of the methods in the Toolkit and GraphicsEnvironment classes, that rely on the native display devices are changed to throw the HeadlessException if the platform does not support a display. In Oracle Database, user interfaces are supported only on client applications. Accordingly, the OracleJVM is a "Headless Platform" and throws a HeadlessException if those methods are called.
Most AWT computation that does not involve accessing the underlying native display or input devices is allowed in Headless AWT. In fact, Headless AWT is quite powerful as it allows programmers access to fonts, imaging, printing, and color and ICC manipulation. For example, applications running in the OracleJVM can parse, manipulate, and write out images as long as they do not try to physically display it in the server. The Sun reference JVM implementation can be invoked in Headless mode (by supplying the property -Djava.awt.headless=true) and run with the same Headless AWT restrictions as the OracleJVM does. The OracleJVM fully complies with the Java Compatibility Kit (JCK) with respect to Headless AWT. See the following Web page for more information on Headless Support in J2SE 1.4:
http://java.sun.com/j2se/1.4/docs/guide/awt/AWTChanges.html#headless
The OracleJVM takes a similar approach for sound support to how it handles AWT. Applications in the OracleJVM are not allowed to access the underlying sound system for purposes of sound playback or recording. Instead, the system sound resources appear to be unavailable in a manner consistent with the sound API specification of the methods that are trying to access the resources. For example, methods in javax.sound.midi.MidiSystem that attempt to access the underlying system sound resources throw the checked exception MidiUnavailableException to signal that the system is unavailable. However, similar to Oracle Database Headless AWT support, Oracle Database supports the APIs that allow sound file manipulation free of the native sound devices. The OracleJVM also fully complies with the JCK when it implements the sound API.
Each Java source, class, and resource is stored in its own schema object in the server. The name of the schema object is derived from the fully qualified name, which includes relevant path or package information. Dots are replaced by slashes. These fully qualified names (with slashes)--used for loaded sources, loaded classes, loaded resources, generated classes, and generated resources--are referred to in this chapter as schema object full names.
Schema object names, however, have a maximum of only 31 characters, and all characters must be legal and convertible to characters in the database character set. If any full name is longer than 31 characters or contains illegal or non-convertible characters, the Oracle Database server converts the full name to a short name to employ as the name of the schema object, keeping track of both names and how to convert between them. If the full name is 31 characters or less and has no illegal or inconvertible characters, then the full name is used as the schema object name.
Because Java classes and methods can have names exceeding the maximum SQL identifier length, Oracle Database uses abbreviated names internally for SQL access. Oracle Database provides a method within the DBMS_JAVA package for retrieving the original Java class name for any truncated name.
FUNCTION longname (shortname VARCHAR2) RETURN VARCHAR2
This function returns the longname from a Java schema object. An example is to print the fully qualified name of classes that are invalid for some reason.
select dbms_java.longname (object_name) from user_objects where object_type = 'JAVA CLASS' and status = 'INVALID';
In addition, you can specify a full name to the database by using the shortname() routine of the DBMS_JAVA package, which takes a full name as input and returns the corresponding short name. This is useful when verifying that your classes loaded by querying the USER_OBJECTS view.
FUNCTION shortname (longname VARCHAR2) RETURN VARCHAR2
Refer to Chapter 8, "Java Stored Procedures Application Example" for a detailed example of the use of this function and ways to determine which Java schema objects are present on the server.
The Java Language Specification provides the following description of Class.forName():
Given the fully-qualified name of a class, this method attempts to locate, load, and link the class. If it succeeds, a reference to the Class object for the class is returned. If it fails, a ClassNotFoundException is thrown.
Class lookup is always on behalf of a referencing class through a ClassLoader. The difference between the JDK implementation and the OracleJVM implementation is the method on which the class is found:
You can receive unexpected results if you try to locate a class with an unexpected resolver. For example, if a class X in schema X requests a class Y in schema Y to look up class Z, you can experience an error if you expected class X's resolver to be used. Because class Y is performing the lookup, the resolver associated with class Y is used to locate class Z. In summary, if the class exists in another schema and you specified different resolvers for different classes--as would happen by default if they are in different schemas-- you might not find the class.
You can solve this resolver problem as follows:
Oracle Database uses resolvers for locating classes within schemas. Every class has a specified resolver associated with it and each class can have a different resolver associated with it. Thus, the locating of classes is dependent on the definition of the associated resolver. The ClassLoader knows which resolver to use, based upon the class that is specified. When you supply a ClassLoader to Class.forName(), your class is looked up in the schemas defined within the resolver of the class. The syntax for this variant of Class.forName is as follows:
Class forName (String name, boolean initialize, ClassLoader loader);
The following examples show how to supply the class loader of either the current class instance or the calling class instance.
You can retrieve the class loader of any instance through the Class.getClassLoader method. The following example retrieves the class loader of the class represented by instance x.
Class c1 = Class.forName (x.whatClass(), true, x.getClass().getClassLoader());
You can retrieve the class of the instance that invoked the executing method through the oracle.aurora.vm.OracleRuntime.getCallerClass method. Once you retrieve the class, invoke the Class.getClassLoader method on the returned class. The following example retrieves the class of the instance that invoked the workForCaller method. Then, its class loader is retrieved and supplied to the Class.forName method. Thus, the resolver used for looking up the class is the resolver of the calling class.
void workForCaller() { <pre>ClassLoader c1 = oracle.aurora.vm.OracleRuntime.getCallerClass().getClassLoader(); ... Class c = Class.forName (name, true, c1);
You can resolve the problem of where to find the class by either supplying the resolver, which knows the schemas to search, or by supplying the schema in which the class is loaded. If you know in which schema the class is loaded, you can use the classForNameAndSchema method. Oracle Database provides a method in the DbmsJava class, which takes in both the name of the class and the schema in which the class resides. This method locates the class within the designated schema.
The following example shows how you can save the schema and class names in the save method. Both names are retrieved, and the class is located using the DbmsJava.classForNameAndSchema method.
import oracle.aurora.rdbms.ClassHandle; import oracle.aurora.rdbms.Schema; import oracle.aurora.rdbms.DbmsJava; void save (Class c1) { <pre>ClassHandle handle = ClassHandle.lookup(c1); Schema schema = handle.schema(); writeNmae (schema.getName()); writeName (c1.getName());} Class restore() {
String schemaName = readName(); String className = readName(); return DbmsJava.classForNameAndSchema (schemaName, className);}
You can supply a single String, containing both the schema and class names, to the oracle.aurora.util.ClassForName.lookupClass method. When invoked, this method locates the class in the specified schema. The string must be in the following format:
"<schema>:<class>"
For example, to locate com.package.myclass in schema SCOTT, execute the following:
oracle.aurora.util.ClassForName.lookupClass("SCOTT:com.package.myclass");
|
Note: You must use uppercase characters for the schema name. In this case, the schema name is case-sensitive. |
When you de-serialize a class, part of the operation is to lookup a class based on a name. In order to ensure that the lookup is successful, the serialized object must contain both the class and schema names.
Oracle Database provides the following classes for serializing and de-serializing objects:
This class extends java.io.ObjectOutputStream and adds schema names in the appropriate places.
This class extends java.io.ObjectInputStream and reads streams written by DbmsObjectOutputStream. You can use this class in any environment. If used within Oracle Database, the schema names are read out and used when performing the class lookup. If used on a client, the schema names are ignored.
The following example shows several methods for looking up a class.
import oracle.aurora.vm.OracleRuntime; import oracle.aurora.rdbms.Schema; import oracle.aurora.rdbms.DbmsJava; public class ForName { private Class from; /* Supply an explicit class to the constructor */ public ForName(Class from) { this.from = from; } /* Use the class of the code containing the "new ForName()" */ public ForName() { from = OracleRuntime.getCallerClass(); } /* lookup relative to Class supplied to constructor */ public Class lookupWithClassLoader(String name) throws ClassNotFoundException { /* A ClassLoader uses the resolver associated with the class*/ return Class.forName(name, true, from.getClassLoader()); } /* In case the schema containing the class is known */ static Class lookupWithSchema(String name, String schema) { Schema s = Schema.lookup(schema); return DbmsJava.classForNameAndSchema(name, s); } }
Operating system resources are a limited commodity on any computer. Because Java is targeted at providing a computing platform as well as a programming language, it contains platform-independent classes and frameworks for accessing platform-specific resources. The Java class methods access operating system resources through the JVM. Java has potential problems with this model, because programmers rely on the garbage collector to manage all resources, when all that the garbage collector manages is Java objects, not the operating system resources that the Java object holds on to.
In addition, when you use shared servers, your operating system resources, which are contained within Java objects, can be invalidated if they are maintained across calls within a session. For further details, see "Operating System Resources Affected Across Calls".
The following sections discusses these potential problems:
In general, your operating system resources contain the following:
| Operating System Resources | Description |
|---|---|
|
memory |
Oracle Database manages memory internally, allocating memory as you create new objects and freeing objects as you no longer need them. The language and class libraries do not support a direct means to allocate and free memory. "Automated Storage Management With Garbage Collection" discusses garbage collection. |
|
files and sockets |
Java contains classes that represent file or socket resources. Instances of these classes hold on to your operating system's file or socket constructs, such as file handles. |
|
threads |
Threads are discouraged within the OracleJVM because of scalability issues. However, you can have a multi-threaded application within the database. "Threading in Oracle Database" discusses in detail the OracleJVM threading model. |
By default, a Java user does not have direct access to most operating system resources. A system administrator may give permission to a user to access these resources by modifying the JVM security restrictions. The JVM security enforced upon system resources conforms to Java 2 security. See "Java 2 Security" for more information.
You access operating system resources using the standard core Java classes and methods. Once you access a resource, the time that it remains active (usable) varies according to the type of resource. Memory is garbage collected as described in "Automated Storage Management With Garbage Collection". Files, threads, and sockets persist across calls when you use a dedicated mode server. In shared server mode, files, threads, and sockets terminate when the call ends. For more information, see "Operating System Resources Affected Across Calls".
Imagine that memory is divided into two realms: Java object memory and operating system constructs. The Java object memory realm contains all objects and variables. Operating system constructs include resources that the operating system allocates to the object when it asks. These resources include files, sockets, and so on.
Basic programming rules dictate that you close all memory--both Java objects and operating system constructs. Java programmers incorrectly assume that all memory is freed by the garbage collector. The garbage collector was created to collect all unused Java object memory. However, it does not close any operating system constructs. All operating system constructs must be closed by the program before the Java object is collected.
For example, whenever an object opens a file, the operating system creates the file and gives the object a file handle. If the file is not closed, the operating system will hold the file handle construct open until the call ends or JVM exits. This can cause you to run out of these constructs earlier than necessary. There are a finite number of handles within each operating system. To guarantee that you do not run out of handles, close your resources before exiting the method. This includes closing the streams attached to your sockets. You should close the streams attached to the socket before closing the socket.
So why not expand the garbage collector to close all operating system constructs? For performance reasons, the garbage collector cannot examine each object to see if it contains a handle. Thus, the garbage collector collects Java objects and variables, but does not issue the appropriate operating system methods for freeing any handles.
Example 2-4 shows how you should close the operating system constructs.
public static void addFile(String[] newFile) { File inFile = new File(newFile); FileReader in = new FileReader(inFile); int i; while ((i = in.read()) != -1) out.write(i); /*closing the file, which frees up the operating system file handle*/ in.close(); }
If you do not close the in file, eventually the File object will be garbage collected. However, even if the File object is garbage collected, the operating system still believes that the file is in use, because it was not closed.
TheOracleJVM implements a non-preemptive threading model. With this model, the JVM runs all Java threads on a single operating system thread. It schedules them in a round-robin fashion and switches between them only when they block. Blocking occurs when you, for example, invoke the Thread.yield() method or wait on a network socket by invoking mySocket.read().
| Advantages of the Oracle Database Threading Model |
Disadvantages |
|---|---|
Oracle chose this model because any Java application written on a single-processor system works identical to one written on a multi-processor system. Also, the lack of concurrency among Java threads is not an issue, because OracleJVM is embedded in the database, which provides a higher degree of concurrency than any conventional JVM.
There is no need to use threads within the application logic because the Oracle server preemptively schedules the session JVMs. If you must support hundreds or thousands of simultaneous transactions, start each one in its own JVM. This is exactly what happens when you create a session in the OracleJVM. The normal transactional capabilities of the Oracle database server accomplish coordination and data transfer between the JVMs. This is not a scalability issue, because in contrast to the 6 MB-8 MB memory footprint of the typical Java virtual machine, the Oracle server can create thousands of JVMs, with each one taking less than 40 KB.
Threading is managed within the OracleJVM by servicing a single thread until it completes or blocks. If the thread blocks, by yielding or waiting on a network socket, the JVM will service another thread. However, if the thread never blocks, it is serviced until completed.
The OracleJVM has added the following features for better performance and thread management:
In the single-threaded execution case, the call ends when one of the following events occurs:
If the initial thread creates and starts other Java threads, the rules about when a call ends are slightly more complicated. In this case, the call ends in one of the following two ways:
In shared server mode, when a call ends because of a return or uncaught exceptions, the OracleJVM throws a ThreadDeathException in all daemon threads. The ThreadDeathException essentially forces threads to stop execution. For other considerations, see "Operating System Resources Affected Across Calls".
In both dedicated and shared server mode, when a call ends because of a call to System.exit() or oracle.aurora.vm.OracleRuntime.exitCall(), the OracleJVM ends the call abruptly and terminates all threads, but does not throw ThreadDeathException.
During the execution of a single call, a Java program can recursively cause more Java code to be executed. For example, your program can issue a SQL query using JDBC that in turn causes a trigger written in Java to be invoked. All the preceding remarks regarding call lifetime apply to the top-most call to Java code, not to the recursive call. For example, a call to System.exit() from within a recursive call will exit the entire top-most call to Java, not just the recursive call.
For sessions that use shared servers, the limitations across calls that applied in previous releases are still present. The reason is that a session that uses a shared server is not guaranteed to connect to the same process on a subsequent database call, and hence the session-specific memory and objects that need to live across calls are saved in the System Global Area. This means that process-specific resources, such as threads, open files and sockets must be cleaned up at the end of each call, and hence will not be available for the next call.
In shared server mode, Oracle Database preserves the state of your Java program between calls by migrating all objects that are reachable from static variables into session space at the end of the call. Session space exists within the client's session to store static variables and objects that exist between calls. OracleJVM performs this migration operation at the end of every call, without any intervention by you.
This migration operation is a memory and performance consideration; thus, you should be aware of what you designate to exist between calls, and keep the static variables and objects to a minimum. If you store objects in static variables needlessly, you impose an unnecessary burden on the memory manager to perform the migration and consume per-session resources. By limiting your static variables to only what is necessary, you help the memory manager and improve your server's performance.
To maximize the number of users who can execute your Java program at the same time, it is important to minimize the footprint of a session. In particular, to achieve maximum scalability, an inactive session should take up as little memory space as possible. A simple technique to minimize footprint is to release large data structures at the end of every call. You can lazily recreate many data structures when you need them again in another call. For this reason, the OracleJVM has a mechanism for calling a specified Java method when a session is about to become inactive, such as at end-of-call time.
This mechanism is the EndOfCallRegistry notification. It enables you to clear static variables at the end of the call and reinitialize the variables using a lazy initialization technique when the next call comes in. You should execute this only if you are concerned about the amount of storage you require the memory manager to store in between calls. It becomes a concern only for more complex stateful server applications you implement in Java.
The decision of whether to null-out data structures at end-of-call and then recreate them for each new call is a typical time and space trade-off. There is some extra time spent in recreating the structure, but you can save significant space by not holding on to the structure between calls. In addition, there is a time consideration, because objects--especially large objects--are more expensive to access after they have been migrated to session space. The penalty results from the differences in representation of session, as opposed to call-space based objects.
Examples of data structures that are candidates for this type of optimization include:
You can register the static variables that you want cleared at the end of the call when the buffer, field, or data structure is created. Within the Oracle-specified oracle.aurora.memoryManager.EndOfCallRegistry class, the registerCallback method takes in an object that implements a Callback object. The registerCallback object stores this object until the end of the call. When end-of-call occurs, OracleJVM invokes the act method within all registered Callback objects. The act method within the Callback object is implemented to clear the user-defined buffer, field, or data structure. Once cleared, the Callback is removed from the registry.
|
Note: If the end of the call is also the end of the session, callbacks are not invoked, because the session space will be cleared anyway. |
The way that you use the EndOfCallRegistry depends on whether you are dealing with objects held in static fields or instance fields.
When the user creates the cache, the Callback object is automatically registered within the getCachedField method. At end-of-call, OracleJVM invokes the registered Callback.act method, which frees the static memory.
import oracle.aurora.memoryManager.Callback; import oracle.aurora.memoryManager.EndOfCallRegistry; class Example { static Object cachedField = null; private static Callback thunk = null; static void clearCachedField() { // clear out both the cached field, and the thunk so they don't // take up session space between calls cachedField = null; thunk = null; } private static Object getCachedField() { if (cachedField == null) { // save thunk in static field so it doesn't get reclaimed // by garbage collector thunk = new Callback () { public void act(Object obj) { Example.clearCachedField(); } }; // register thunk to clear cachedField at end-of-call. EndOfCallRegistry.registerCallback(thunk); // finally, set cached field cachedField = createCachedField(); } return cachedField; } private static Object createCachedField() { .... } }
When the user creates the cache, the Callback object is automatically registered within the getCachedField method. At end-of-call, OracleJVM invokes the registered Callback.act method, which frees the cache.
This approach ensures that the lifetime of the Callback object is identical to the lifetime of the instance, because they are the same object.
import oracle.aurora.memoryManager.Callback; import oracle.aurora.memoryManager.EndOfCallRegistry; class Example2 implements Callback { private Object cachedField = null; public void act(Object obj) { // clear cached field cachedField = null; obj = null; } // our accessor method private static Object getCachedField() { if (cachedField == null) { // if cachedField is not filled in then we need to // register self, and fill it in. EndOfCallRegistry.registerCallback(self); cachedField = createCachedField(); } return cachedField; } private Object createCachedField() { .... } }
A weak table holds the registry of end-of-call callbacks. If either the Callback object or value are not reachable (see JLS section 12.6) from the Java program, both object and value will be dropped from the table. The use of a weak table to hold callbacks also means that registering a callback will not prevent the garbage collector from reclaiming that object. Therefore, you must hold on to the callback yourself if you need it--you cannot rely on the table holding it back.
You can find other ways in which end-of-call notification will be useful to your applications. The following sections give the details for methods within the EndOfCallRegistry class and the Callback interface:
The registerCallback method installs a Callback object within a registry. At the end of the call, OracleJVM invokes the act methods of all registered Callback objects.
You can register your Callback object by itself or with a value object. If you need additional information stored within an object to be passed into act, you can register this object within the value parameter.
public static void registerCallback(Callback thunk, Object value); public static void registerCallback(Callback thunk);
static void runCallbacks()
The JVM calls this method at end-of-call and calls act for every Callback object registered using registerCallback. You should never call this method in your code. It is called at end-of-call, before object migration and before the last finalization step.
Interface oracle.aurora.memoryManager.Callback
Any object you want to register using EndOfCallRegistry.registerCallback implements the Callback interface. This interface can be useful in your application, where you require notification at end-of-call.
public void act(Object value)
You can implement any activity that you require to occur at the end of the call. Normally, this method will contain procedures for clearing any memory that would be saved to session space.
In shared server mode, the OracleJVM closes any open operating system resources at the end of a database call, as shown in the following table:
| Resource | Lifetime |
|---|---|
|
files |
The system closes all files left open when a database call ends. |
|
threads |
All threads are terminated when a call ends. |
|
sockets |
See "Sockets" more information. |
|
objects that depend on operating system resources |
Regardless of the usable lifetime of the object (for example, the defined lifetime for a thread object), the Java object can be valid for the duration of the session. This can occur, for example, if the Java object is stored in a static class variable, or a class variable references it directly or indirectly. If you attempt to use one of these Java objects after its usable lifetime is over, Oracle Database throws an exception. This is true for the following examples: |
You should close resources that are local to a single call when the call ends. However, for static objects that hold on to operating system resources, you must be aware of how these resources are affected after the call ends.
In shared server mode, the OracleJVM automatically closes any open operating system constructs--in Example 2-5, the file handle--when the call ends. This can affect any operating system resources within your Java object. If you have a file opened within a static variable, the file handle is closed at the end of the call for you. So, if you hold on to the File object across calls, the next usage of the file handle throws an exception.
In Example 2-5, class Concat enables multiple files to be written into a single file, outFile. On the first call, outFile is created. The first input file is opened, read, input into outFile, and the call ends. Because outFile is statically defined, it is moved into session space between call invocations. However, the file handle--that is, the FileDescriptor--is closed at the end of the call. The next time you call addFile, you will get an exception.
public class Concat { static File outFile = new File("outme.txt"); FileWriter out = new FileWriter(outFile); public static void addFile(String[] newFile) { File inFile = new File(newFile); FileReader in = new FileReader(inFile); int i; while ((i = in.read()) != -1) out.write(i); in.close(); } }
There is a workaround: to make sure that your handles stay valid, close your files, buffers, and so on, at the end of every call; reopen the resource at the beginning of the next call. Another option is to use the database rather than using operating system resources. For example, try to use database tables rather than a file. Or do not store operating system resources within static objects expected to live across calls; use operating system resources only within objects local to the call.
Example 2-6 shows how you can perform concatenation, as in Example 2-5, without compromising your operating system resources. The addFile method opens the outme.txt file within each call, making sure that anything written into the file is appended to the end. At the end of each call, the file is closed. Two things occur:
public class Concat { public static void addFile(String[] newFile) { /*open the output file each call; make sure the input*/ /*file is written out to the end by making it "append=true"*/ FileWriter out = new FileWriter("outme.txt", TRUE); File inFile = new File(newFile); FileReader in = new FileReader(inFile); int i; while ((i = in.read()) != -1) out.write(i); in.close(); /*close the output file between calls*/ out.close(); } }
Sockets are used in setting up a connection between a client and a server. For each database connection, sockets are used at either end of the connection. Your application does not set up the connection; the connection is set up by the underlying networking protocol: Oracle Net's TTC or IIOP. See "Configuring OracleJVM" for information on how to configure your connection.
You might also wish to set up another connection--for example, connecting to a specified URL from within one of the classes stored within the database. To do so, instantiate sockets for servicing the client and server sides of the connection.
A socket exists at each end of the connection. The server-side of the connection that listens for incoming calls is serviced by a ServerSocket. The client-side of the connection that sends requests is serviced through a Socket. You can use sockets as defined within the JVM with the following restriction: a ServerSocket instance within a shared server cannot exist across calls.
In shared server mode, when a call ends because of a return or uncaught exceptions, the OracleJVM throws a ThreadDeathException in all daemon threads. The ThreadDeathException essentially forces threads to stop execution. Code that depends on threads living across calls does not behave as expected in shared server mode. For example, the value of a static variable that tracks initialization of a thread may become incorrect in subsequent calls because all threads are killed at the end of a database call.
As a specific example, the RMI Server that Sun Microsystems supplies does function in shared server mode; however, it is useful only within the context of a single call. This is because the RMI Server forks daemon threads, which in shared server mode are killed off at the end of call (that is, when all non-daemon threads return). If the RMI server session is reentered in a subsequent call, these daemon threads aren't restarted and the RMI server won't function properly.
|
 Copyright © 1999, 2003 Oracle Corporation All Rights Reserved. |
|

