| Oracle® High Availability Architecture and Best Practices 10g Release 1 (10.1) Part Number B10726-01 |
|





|
View PDF |
| Oracle® High Availability Architecture and Best Practices 10g Release 1 (10.1) Part Number B10726-01 |
|
|
View PDF |
This chapter describes Oracle configuration best practices. It includes the following sections:
| See Also:
Appendix B, "Database SPFILE and Oracle Net Configuration File Samples" for a complete example of database parameter settings |
The practices that are recommended in this section affect the performance, availability, and MTTR of your system. These practices apply to the single-instance database, RAC-only, Data Guard-only, and Maximum Availability architectures described in Chapter 4, "High Availability Architectures". The recommendations in this section are identical for the primary and standby databases when Oracle Data Guard is used. Some of these practices may reduce performance, but they are necessary to reduce or avoid outages. The minimal performance impact is outweighed by the reduced risk of corruption or the performance improvement for recovery.
This section includes the following recommendations:
Maintain two copies of the control file. If a single control file is damaged, then any Oracle instance fails when it attempts to access the damaged or missing control file. If another copy of the current control file is available, then an instance can be easily restarted after copying the good control file to the location of the bad control file. Database recovery is unnecessary.
Set the CONTROL_FILE_RECORD_KEEP_TIME initialization parameter to a value that enables all on-disk backup information to be retained in the control file. Allocate 200 MB for each control file. CONTROL_FILE_RECORD_KEEP_TIME specifies the number of days that records are kept within the control file before becoming a candidate for reuse. Set the CONTROL_FILE_RECORD_KEEP_TIME value to slightly longer than the oldest backup file that you intend to keep on disk, as determined by the size of the flash recovery area. For example, if the flash recovery area is sized to maintain two full backups that are taken every 7 days, as well as daily incremental backups and archived redo log files, then set CONTROL_FILE_RECORD_KEEP_TIME to a value like 21 or 30. Records older than this will be reused. However, the backup metadata will still be available in the RMAN recovery catalog.
All online redo log files should be the same size and configured to switch approximately once an hour during normal activity. They should switch no more frequently than every 20 minutes during peak activity.
There should be a minimum of four online log groups to prevent LGWR from waiting for a group to be available following a log switch. A group may be unavailable because a checkpoint has not yet completed or the group has not yet been archived.
Use Oracle log multiplexing to create multiple redo log members in each redo group. This protects against a failure involving the redo log, such as a disk corruption that exists on both sides of the disk mirror for one of the members, or a user error that accidentally removes a member. If at least one redo log member is available, then the instance can continue to function.
ARCHIVELOG mode enables the database to be backed up while it is online and is necessary to recover the database to a point in time later than what has already been restored.
Architectures that include Oracle Data Guard require that the production database run in ARCHIVELOG mode before a standby database is instantiated. ARCHIVELOG mode is required to maintain a standby database.
| See Also:
Oracle Database Administrator's Guide for more information about using automatic archiving |
By default, Oracle always tests the data blocks that it reads from disk. Enabling data and log block checksums by setting DB_BLOCK_CHECKSUM to TRUE enables Oracle to detect other types of corruption caused by underlying disks, storage systems, or I/O systems. Before a data block is written to disk, a checksum is computed and stored in the block. When the block is subsequently read from disk, the checksum is computed again and compared with the stored checksum. Any difference is treated as a media error and an ORA-1578 error is signaled. Block checksums are always maintained for the SYSTEM tablespace.
In addition to enabling data block checksums, Oracle also calculates a checksum for every redo log block before writing it to the current log. Redo record corruptions are found as soon as the log is archived. Without this option, a corruption in a redo log can go unnoticed until the log is applied to a standby database or until a backup is restored and rolled forward through the log containing the corrupt log block.
RMAN also calculates checksums when taking backups to ensure that all blocks being backed up are validated.
Turning on this feature typically has minimal overhead. Measure the performance impact with your workload on a test system and ensure that the performance impact is acceptable before introducing this feature on an active database.
Enable database block checking by setting DB_BLOCK_CHECKING to TRUE. When block checking is enabled, whenever a block is modified, Oracle verifies that the block is self-consistent. If it is inconsistent, then the block is marked corrupt, an ORA-1578 error is returned, and a trace file is created containing details of the problem. Without block checking enabled, corruptions can go undetected until the block is accessed again. Block checking for the SYSTEM tablespace is always enabled.
Block checking can often prevent memory and data corruption. Turning on this feature typically causes an additional 1 percent to 10 percent overhead, depending on workload. Measure the performance impact on a test system using your workload and ensure that it is acceptable before introducing this feature on an active database.
To ensure that blocks are not corrupted externally to Oracle, use one of the following:
BACKUP command with the VALIDATE optionDBVERIFY utilityANALYZE TABLE tablename VALIDATE STRUCTURE CASCADE SQL statement
Checkpoint activity should be logged to the alert log by setting LOG_CHECKPOINT_TO_ALERT to TRUE. Monitor checkpoint activity to ensure that a current checkpoint completes before the next checkpoint starts.
Fast-start checkpointing refers to the periodic writes by the database writer (DBWn) processes. DBWn processes write changed data blocks from the Oracle buffer cache to disk and advance the thread checkpoint. With fast-start checkpointing, the checkpoint continually advances so that recovery time from instance or node failure occurs predictably.
Oracle Database 10g supports automatic checkpoint tuning which takes advantage of periods of low I/O usage to advance checkpoints and therefore improve availability. Automatic checkpoint tuning is in effect if the FAST_START_MTTR_TARGET database initialization parameter is unset. Observe the following recommendations to take advantage of automatic checkpoint tuning:
FAST_START_MTTR_TARGET to the desired MTTR in seconds.FAST_START_MTTR_TARGET unset to enable automatic checkpoint tuning.FAST_START_MTTR_TARGET=0. Disable fast-start checkpointing only when system I/O capacity is insufficient with fast-start checkpointing enabled and achieving a target MTTR is not important.Enabling fast-start checkpointing increases the average number of writes per transaction that DBWn issues for a given workload (when compared with disabling fast-start checkpointing). However, if the system is not already near or at its maximum I/O capacity, then fast-start checkpointing has a negligible impact on performance. The percentage of additional DBWn writes with very aggressive fast-start checkpointing depends on many factors, including the workload, I/O speed and capacity, CPU speed and capacity, and the performance of previous recoveries.
Monitor the V$MTTR_TARGET_ADVICE view for advisory information and an estimate of the number of additional I/O operations that would occur under different FAST_START_MTTR_TARGET values. You should also test various FAST_START_MTTR_TARGET settings (such as 0, 1, 90, 180, 270, 3600, and unset) under load to determine the runtime impact (for example, the amount of increased DBWn write activity) on a particular system and the instance recovery time achieved with that setting.
If FAST_START_MTTR_TARGET is set to a low value, then fast-start checkpointing is more aggressive, and the average number of writes per transaction that DBWn issues is higher in order to keep the thread checkpoint sufficiently advanced to meet the requested MTTR. Conversely, if FAST_START_MTTR_TARGET is set to a high value, or if automatic checkpoint tuning is in effect (that is, FAST_START_MTTR_TARGET is unset), then fast-start checkpointing in less aggressive, and the average number of writes per transaction that DBWn issues is lower.
Fast-start checkpointing can be explicitly disabled by setting FAST_START_MTTR_TARGET=0. Disabling fast-start checkpointing leads to the fewest average number of writes per transaction for DBWn for a specific workload and configuration, but also results in the highest MTTR.
When you enable fast-start checkpointing, remove or disable (set to 0) the following initialization parameters: LOG_CHECKPOINT_INTERVAL, LOG_CHECKPOINT_TIMEOUT, FAST_START_IO_TARGET.
Set the TIMED_STATISTICS initialization parameter to TRUE to capture Oracle event timing data. This parameter is set to TRUE by default if the STATISTICS_LEVEL database parameter is set to its default value of TYPICAL. Effective data collection and analysis is essential for identifying and correcting system performance problems. Oracle provides several tools that allow a performance engineer to gather information about instance and database performance. Setting TIMED_STATISTICS to TRUE is essential to effectively using the Oracle tools.
See Also:
|
With automatic undo management, the Oracle server effectively and efficiently manages undo space, leading to lower administrative complexity and cost. When Oracle internally manages undo segments, undo block and consistent read contention are eliminated because the size and number of undo segments are automatically adjusted to meet the current workload requirement.
To use automatic undo management, set the following parameters:
UNDO_MANAGEMENT = AUTOUNDO_RETENTION is the desired time in seconds to retain undo data. It must be the same on all instances.UNDO_TABLESPACE should specify a unique undo tablespace for each instance.Advanced object recovery features, such as Flashback Query, Flashback Version Query, Flashback Transaction Query, and Flashback Table, require automatic undo management. These features depend on the UNDO_RETENTION setting. Retention is specified in units of seconds. By default, Oracle automatically tunes undo retention by collecting database use statistics and estimating undo capacity needs. You can affect this automatic tuning by setting the UNDO_RETENTION initialization parameter. The default value of UNDO_RETENTION is 900. You do not need to set this parameter if you want Oracle to tune undo retention. The UNDO_RETENTION value can be changed dynamically at any time by using the ALTER SYSTEM statement.
Setting UNDO_RETENTION does not guarantee that undo data will be retained for the specified period of time. If undo data is needed for transactions, then the UNDO_RETENTION period is reduced so that transactions can receive the necessary undo data.
You can guarantee that unexpired undo data is not overwritten even if it means that future operations that need to generate undo data will fail. This is done by specifying the RETENTION GUARANTEE clause for the undo tablespace when it is created by either the CREATE DATABASE or CREATE UNDO TABLESPACE statement. Alternatively, you can later specify this clause in an ALTER TABLESPACE statement.
With the retention guarantee option, the undo guarantee is preserved even if there is need for DML activity. (DDL statements are still allowed.) If the tablespace is configured with less space than the transaction throughput requires, the following four things will occur in this sequence:
| See Also:
Oracle Database Administrator's Guide for more information about the |
Locally managed tablespaces perform better than dictionary-managed tablespaces, are easier to manage, and eliminate space fragmentation concerns. Locally managed tablespaces use bitmaps stored in the datafile headers and, unlike dictionary managed tablespaces, do not contend for centrally managed resources for space allocations and de-allocations.
Automatic segment space management simplifies space administration tasks, thus reducing the chance of human error. An added benefit is the elimination of performance tuning related to space management. It facilitates management of free space within objects such as tables or indexes, improves space utilization, and provides significantly better performance and scalability with simplified administration. The automatic segment space management feature is available only with permanent locally managed tablespaces.
Temporary tablespaces improve the concurrency of multiple sort operations, reduce sort operation overhead, and avoid data dictionary space management operations altogether. This is a more efficient way of handling temporary segments, from the perspective of both system resource usage and database performance.
A default temporary tablespace should be specified for the entire database to prevent accidental exclusion of the temporary tablespace clause. This can be done at database creation time by using the DEFAULT TEMPORARY TABLESPACE clause of the CREATE DATABASE statement or after database creation by the ALTER DATABASE statement. Using the default temporary tablespace ensures that all disk sorting occurs in a temporary tablespace and that other tablespaces are not mistakenly used for sorting.
Resumable space allocation provides a way to suspend and later resume database operations if there are space allocation failures. The affected operation is suspended instead of the database returning an error. No processes need to be restarted. When the space problem is resolved, the suspended operation is automatically resumed.
Set the RESUMABLE_TIMEOUT initialization parameter to the number of seconds of the retry time.
The flash recovery area is an Oracle-managed directory, file system, or automatic storage management disk group that provides a centralized disk location for backup and recovery files. The flash recovery area is defined by setting the following database initialization parameters:
DB_RECOVERY_FILE_DEST: Default location for the flash recovery areaDB_RECOVERY_FILE_DEST_SIZE: Specifies (in bytes) the hard limit on the total space to be used by target database recovery files created in the recovery area locationThe bigger the flash recovery area, the more beneficial it becomes. The minimum recommended disk limit is the sum of the database size, the size of incremental backups, the size of all archived redo logs that have not been copied to tape, and the size of the flashback logs.
| See Also:
Oracle Database Backup and Recovery Advanced User's Guide and Oracle Database Backup and Recovery Basics for detailed information about sizing the flash recovery area and setting the retention period |
Flashback Database is a revolutionary recovery feature that operates on only the changed data, thereby making the time to correct an error equal to the time to cause the error without recovery time being a function of the database size. You can flash back a database from both RMAN and SQL*Plus with a single command instead of a complex procedure. Flashback Database is similar to conventional point-in-time recovery in its effects, enabling you to return a database to its state at a time in the recent past. However, Flashback Database is much faster than point-in-time recovery, because it does not require restoring datafiles from backup or extensive application of redo data.
To enable Flashback Database, set up a flash recovery area, and set a flashback retention target (DB_FLASHBACK_RETENTION_TARGET initialization parameter), to specify how far back into the past in minutes you want to be able to restore your database using Flashback Database. To enable Flashback Database, execute the ALTER DATABASE FLASHBACK ON statement. It is important to note that the flashback retention target is a target, not an absolute guarantee that Flashback Database will be available. If your flash recovery area is not large enough to hold required files such as archived redo logs and other backups, then flashback logs may be deleted to make room in the flash recovery area for these required files. To determine how far you can flash back at any one time, query the V$FLASHBACK_DATABASE_LOG view. If you have a standby database, then set FLASHBACK_RETENTION_TIME to be the same for both primary and standby databases.
The biggest threat to corporate data comes from employees and contractors with internal access to networks and facilities. Corporate data is one of a company's most valuable assets that can be at grave risk if placed on a system or database that does not have proper security measures in place. A well-defined security policy can help protect your systems from unwanted access and protect sensitive corporate information from sabotage. Proper data protection reduces the chance of outages due to security breeches.
In addition to the "High Availability" section in Chapter 9, "Oracle Security Products and Features", the Oracle Security Overview manual is a high-level guide to technical security solutions for the data security challenge. Consult Part II, "Technical Solutions to Security Risks" of the Oracle Security Overview for an overview of techniques for implementing security best practices. For a much more detailed view of security policies, checklists, guidelines, and features, see the Oracle Database Security Guide
The Database Resource Manager gives database administrators more control over resource management decisions, so that resource allocation can be aligned with the business objectives of an enterprise. The Database Resource Manager provides the ability to prioritize work within the Oracle system. Availability of the database encompasses both its functionality and performance. If the database is available but users are not getting the level of performance they need, then availability and service level objectives are not being met. Application performance, to a large extent, is affected by how resources are distributed among the applications that access the database. The main goal of the Database Resource Manager is to give the Oracle database server more control over resource management decisions, thus circumventing problems resulting from inefficient operating system management and operating system resource managers.
The server parameter file (SPFILE) enables a single, central parameter file to hold all of the database initialization parameters associated with all of the instances associated with a database. This provides a simple, persistent, and robust environment for managing database parameters.
An SPFILE is required when using the Data Guard Broker.
The practices that are recommended in this section affect the performance, availability, and MTTR of your system. These practices build on the single instance database configuration best practices. The practices are identical for the primary and standby databases if they are used with Data Guard in the MAA architecture. Some of these practices may reduce performance levels, but they are necessary to reduce or avoid outages. The minimal performance impact is outweighed by the reduced risk of corruption or the performance improvement for recovery.
The rest of this section includes the following topics:
The listeners should be cross-registered by using the REMOTE_LISTENER parameter so that all listeners know about all services and in which instances the services are running. The listeners should use server-side load balancing, which can be based on session count for connection. The listeners must be listening on the virtual IP addresses and on the cluster alias, when it is available. The listeners must not listen on the hostname. Listening on the hostname will result in disconnected sessions when virtual IPs are relocated automatically back to their owning nodes.
The CLUSTER_INTERCONNECTS initialization parameter should be set only if there is more than one cluster interconnect and the default cluster interconnect does not meet the throughput requirements of the RAC database. When CLUSTER_INTERCONECTS is set to more than one network address, Oracle load-balances across the interfaces. However, there are no automatic failover capabilities employed by Oracle, requiring that all interfaces be available for a properly functioning database environment.
These practices build on the recommendations for configuring the single-instance database. The proper configuration of Oracle Data Guard Redo Apply and SQL Apply is essential to ensuring that all standby databases work properly and perform their roles within service levels after switchovers and failovers. Most Data Guard configuration settings can be made through the Oracle Enterprise Manager. For more advanced, less frequently used Data Guard configuration parameters, the Data Guard Broker command-line interface or SQL*Plus can be used.
Data Guard enables you to use either a physical standby database or a logical standby database or both, depending on the business requirements. A physical standby database provides a physically identical copy of the primary database, with on-disk database structures that are identical to the primary database on a block-for-block basis. The database schema, including indexes, are the same. A physical standby database is kept synchronized with the primary database by applying the redo data received from the primary database.
A logical standby database contains the same logical information as the production database, although the physical organization and structure of the data can be different. It is kept synchronized with the primary database by transforming the data in the redo log files received from the primary database into SQL statements and then executing the SQL statements on the standby database. A logical standby database can be used for other business purposes in addition to disaster recovery requirements.
Table 7-1 can help you determine which type of standby database to use.
| Questions | Recommendations |
|---|---|
|
Run the following query: SELECT DISTINCT OWNER, TABLE_NAME FROM DBA_LOGSTDBY_UNSUPPORTED ORDER BY OWNER, TABLE_NAME; Rows returned - Use a physical standby database or investigate changing to supported datatypes No rows returned - Go to next question | |
|
See Also: "Oracle9i Data Guard: SQL Apply Best Practices" at |
Yes - Evaluate a logical standby database No - Use a physical standby database |
Table 7-2 shows the recommendations for configuration that apply to both logical and physical standby databases and those that apply to only logical and only physical.
| Recommendations for Both Physical and Logical Standby Databases | Recommendations for Physical Standby Databases Only | Recommendations for Logical Standby Databases Only |
|---|---|---|
|
Use Multiplexed Standby Redo Logs and Configure Size Appropriately |
- |
|
|
- |
||
|
- |
||
|
Configure the Database and Listener for Dynamic Service Registration |
- |
|
|
- |
- | |
|
- |
- | |
|
Conduct a Performance Assessment with the Proposed Network Configuration |
- |
- |
|
Use a LAN or MAN for Maximum Availability or Maximum Protection Modes |
- |
- |
|
- |
- | |
|
- |
- | |
|
Use the ASYNC Attribute with a 50 MB Buffer for Maximum Performance Mode |
- |
- |
|
- |
- | |
|
- |
- | |
|
- |
- | |
|
- |
- | |
|
- |
- |
This archiving strategy is based on the following assumptions:
Table 7-3 describes the recommendations for a robust archiving strategy.
| Recommendation | Description |
|---|---|
|
Archiving must be started on the primary database |
Maintaining a standby database requires archiving to be enabled and started on the primary database. SQL> SHUTDOWN IMMEDIATE SQL> STARTUP MOUNT; SQL> ALTER DATABASE ARCHIVELOG; SQL> ALTER DATABASE OPEN; |
|
Remote archiving must be enabled. |
|
|
Use a consistent log format ( |
If the flash recovery is used, then this format is ignored. For example: |
|
Local archiving is done first by the archiver process ( |
Using |
|
Remote archiving should be done to only one standby instance and node for each standby RAC database. |
All production instances archive to one standby destination, using the same net service name. Oracle Net Services connect-time failover is used if you want to automatically switch to the secondary standby host when the primary standby instance has an outage. |
|
The standby archive destination should use the flash recovery area. |
For simplicity, the standby archive destination ( |
|
The logical standby archive destination cannot use the flash recovery area. |
For a logical standby database, |
|
Specify role-based destinations with the |
The See Also: Appendix B, "Database SPFILE and Oracle Net Configuration File Samples" |
The following example illustrates the recommended initialization parameters for a primary database communicating to a physical standby database. There are two instances, SALES1 and SALES2, running in maximum protection mode.
*.DB_RECOVERY_FILE_DEST=/recoveryarea *LOG_ARCHIVE_DEST_1='SERVICE=SALES LGWR SYNC=NOPARALLEL AFFIRM REOPEN=15 MAX_FAILURE=10 VALID_FOR=(ONLINE+LOGFILES, ALL ROLES)' *.LOG_ARCHIVE_DEST_STATE_1='ENABLE' *.STANDBY_ARCHIVE_DEST='USE_DB_RECOVERY_FILE_DEST'
Note the following observations for this example:
PARALLEL attribute is used when there are multiple standby destinations. When SYNC is set to PARALLEL, the LGWR process initiates an I/O operation to each standby destination at the same time. Because there is a single standby destination, the NOPARALLEL option is set to reduce overhead.REOPEN=15 MAX_FAILURE=10 setting denotes that if there is a connection failure, then the connection is reopened after 15 seconds and is retried up to 10 times.VALID_FOR clause is used to designate the role for a destination. When the database is in a physical standby role, remote destination LOG_ARCHIVE_DEST_1 is not used because a physical standby database does not use online log files.The flash recovery area must be accessible to any node within the cluster and use a shared file system technology such as automatic storage management (ASM), a cluster file system, a global file system, or high availability network file system (HA NFS). You can also mount the file system manually to any node within the cluster very quickly. This is necessary for recovery because all archived redo log files must be accessible on all nodes.
On the standby database nodes, recovery from a different node is required when Node 1 fails and cannot be restarted. In that case, any of the existing standby instances residing on a different node can initiate managed recovery. In the worst case, when the standby archived redo log files are inaccessible, the new managed recovery process (MRP) or logical standby process (LSP) on the different node fetches the archived redo log files using the FAL server to retrieve from the production nodes directly.
When configuring hardware vendor shared file system technology, verify the performance and availability implications. Investigate the following issues before adopting this strategy:
Standby redo logs (SRLs) should be used on both sites. Use Oracle log multiplexing to create multiple standby redo log members in each standby redo group. This protects against a failure involving the redo log, such as disk corruption that exists on both sides of the disk mirror for one of the members or a user error that accidentally removed a member.
Use this formula to determine the number of SRLs:
# of SRLs = sum of all production online log groups per thread + number of threads
For example, if a primary database has two instances (threads) and each thread has four online log groups, then there should be ten SRLs. Having one more standby log group for each thread than the number of the online redo log groups for the production database reduces the likelihood that the LGWR for the production instance is blocked because an SRL cannot be allocated on the standby.
The following are additional guidelines for creating SRLs:
ALTER DATABASE ADD STANDBY LOGFILE THREAD 1 GROUP 10 '/dev/vx/rdsk/ha10-dg/DGFUN stbyredo10 01.log' SIZE 50M REUSE;
The remote file server (RFS) process for the standby database writes only to an SRL whose size is identical to the size of an online redo log for the production database. If it cannot find an appropriately sized SRL, then RFS creates an archived redo log file directly instead and logs the following message in the alert log:
No standby redo log files of size <#> blocks available.
When the production database is in FORCE LOGGING mode, all database changes are logged except for those in temporary tablespaces and temporary segments. FORCE LOGGING mode ensures that the standby database remains consistent with the production database. If this is not possible because you require the load performance with NOLOGGING operations, then you must ensure that the corresponding standby datafiles are subsequently synchronized. After completing the nologging operations, a production backup of the affected datafiles needs to replace the corresponding standby datafiles. Before the file transfer, the physical standby database must stop recovery and the logical standby database must temporarily take the affected tablespaces offline.
You can enable force logging immediately by issuing an ALTER DATABASE FORCE LOGGING statement. If you specify FORCE LOGGING, then Oracle waits for all ongoing unlogged operations to finish.
Using real time apply enables the log apply services to apply redo data (physical standby database) or SQL (logical standby database) as it is received without waiting for the current standby redo log file to be archived. This results in faster switchover and failover times because the standby redo log files are applied to the standby database before failover or switchover begins.
For a physical standby database, use the following SQL statement
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT LOGFILE;
For a logical standby database, use the following SQL statement:
ALTER DATABASE START LOGICAL STANDBY APPLY IMMEDIATE;
The setting for the SERVICE attribute of the LOG_ARCHIVE_DEST_2 initialization parameter and the settings for the FAL_SERVER and FAL_CLIENT initialization parameters depend on a proper Oracle Net configuration. For the Oracle Data Guard transport service and the gap resolution feature to work, the SPFILE, listener.ora, tnsnames.ora, and sqlnet.ora files must be consistent.
See Also:
|
The remote archive destination FAL_CLIENT and FAL_SERVER parameters require an Oracle Net service. This service is represented as a net service name entry in the local tnsnames.ora file. Notice that the FAL_SERVER and FAL_CLIENT reference the same Oracle network service name. This is possible because the FAL_SERVER service is defined in the standby tnsnames.ora file, whereas the FAL_CLIENT service is defined in the primary tnsnames.ora file. This works only when you use the Oracle Network Service local naming method. If you are not using the local naming method, then you must have different service names. Furthermore, Oracle recommends using dynamic service registration instead of a static SID list in the listener configuration. To ensure that service registration works properly, the server parameter file should contain the following parameters:
SERVICE_NAMES for the database service nameINSTANCE_NAME for the instance nameLOCAL_LISTENER to specify a nondefault listener addressPMON dynamically registers a database service with the listener. PMON attempts to resolve LOCAL_LISTENER using some naming method. In the case described here, PMON finds the corresponding name in the local tnsnames.ora file.
For example:
SALES1.INSTANCE_NAME='SALES1' SALES2.INSTANCE_NAME='SALES2' *.LOG_ARCHIVE_DEST_2='SERVICE=SALES LGWR SYNC=NOPARALLEL AFFIRM REOPEN=15 MAX_FAILURE=10' *.LOCAL_LISTENER='SALES_lsnr' *.SERVICE_NAMES='SALES' # required for service registration *.FAL_SERVER='SALES' *.FAL_CLIENT='SALES'
The listener.ora file should be identical for each primary and secondary host except for HOST settings. Because service registration is used, there is no need for statically configured information.
The local tnsnames.ora file should contain the net service names and the local listener name translation. To use the same service name on each node, you must use a locally managed tnsnames.ora file for the production and standby databases. On the primary cluster, the tnsnames.ora entry, SERVICE_NAME, should equal the setting of the SERVICE_NAMES SPFILE parameter. If the listener is started after the instance, then service registration does not happen immediately. In this case, issue the ALTER SYSTEM REGISTER statement on the database to instruct the PMON background process to register the instance with the listeners immediately.
Reducing the number of round trips across the network is essential for optimizing the transportation of redo log data to a standby site. With Oracle Net Services it is possible to control data transfer by adjusting the size of the Oracle Net setting for the session data unit (SDU). In a WAN environment, setting the SDU to 32K can improve performance. The SDU parameter designates the size of an Oracle Net buffer before it delivers each buffer to the TCP/IP network layer for transmission across the network. Oracle Net sends the data in the buffer either when requested or when it is full. Oracle internal testing of Oracle Data Guard on a WAN has demonstrated that the maximum setting of 32K (32768) performs best on a WAN. The primary gain in performance when setting the SDU is a result of the reduced number of calls to packet the data.
In addition to setting the SDU parameter, network throughput can often be substantially improved by using the SQLNET.SEND_BUF_SIZE and SQLNET.RECV_BUF_SIZE Oracle Net parameters to increase the size of the network TCP send and receive I/O buffers.
In some situations, a business cannot afford to lose data at any cost. In other situations, the availability of the database may be more important than protecting f data. Some applications require maximum database performance and can tolerate a potential loss of data if a disaster occurs.
Choose one of the following protection modes:
This section includes the following topics:
| See Also:
Oracle Data Guard Concepts and Administration for more information about data protection modes |
To determine the correct data protection mode for your application, ask the questions in Table 7-4.
The default data protection mode is maximum performance mode. After a failover to the standby database, the protection mode automatically changes to maximum performance mode. Switchover operations do not change the protection mode.
To change the data protection mode from maximum performance to maximum availability or maximum protection, perform the following steps:
LGWR SYNC option and a valid net service name during startup. For maximum performance mode, use the LGWR ASYNC option with a valid net service name.SHUTDOWN IMMEDIATE; STARTUP MOUNT EXCLUSIVE;
ALTER DATABASE SET STANDBY TO MAXIMIZE [AVAILABILITY | PROTECTION];
To change the protection mode from maximum protection to maximum performance or maximum availability, use a statement similar to the following:
ALTER DATABASE SET STANDBY TO MAXIMIZE [PERFORMANCE | AVAILABILITY];
See Also:
|
Oracle recommends that you conduct a performance assessment with your proposed network configuration and current (or anticipated) peak redo rate. The network impact between the production and standby databases and the impact on the primary database throughput needs to be understood. Because the network between the production and standby databases is essential for the two databases to remain synchronized, the infrastructure must have the following characteristics:
The required bandwidth of a dedicated network connection is determined by the maximum redo rate of the production database. You also need to account for actual network efficiency. Depending on the data protection mode, there are other recommended practices and performance considerations. Maximum protection mode and maximum availability mode require LGWR SYNC transport. Maximum performance protection mode uses the ASYNC transport option or the archiver (ARCHn) instead of LGWR to transfer the redo. These recommendations were derived from an Oracle internal performance study that measured the impact of network latency on primary database throughput for each Oracle Data Guard transport option: ARCH, LGWR ASYNC, and LGWR SYNC.
| See Also:
|
The network infrastructure between the primary and secondary sites must be able to accommodate the redo traffic because the production database redo data is updating the physical standby database. If your maximum redo traffic at peak load is 8 MB/second, then your network infrastructure must have sufficient bandwidth to handle this load. Furthermore, network latency affects overall throughput and response time for OLTP and batch operations.
When you compare maximum protection mode or maximum availability mode with LGWR SYNC operations with maximum performance mode with LGWR ASYNC operations, measure whether performance or throughput will be degraded due to the incurred latency. You should also check whether the new throughput and response time are within your application performance requirements. Distance and the network configuration directly influence latency, while high latency may slow down your potential transaction throughput and increase response time. The network configuration, number of repeaters, the overhead of protocol conversions, and the number of routers also affect the overall network latency and transaction response time.
Maximum availability mode or maximum protection mode require the Oracle Data Guard transport service to use the LGWR SYNC transport option. Network latency is an additional overhead for each LGWR SYNC I/O operation. Figure 7-1 shows that LGWR SYNC writes both locally to the online redo log and remotely through the network to the RFS process to the standby redo logs.
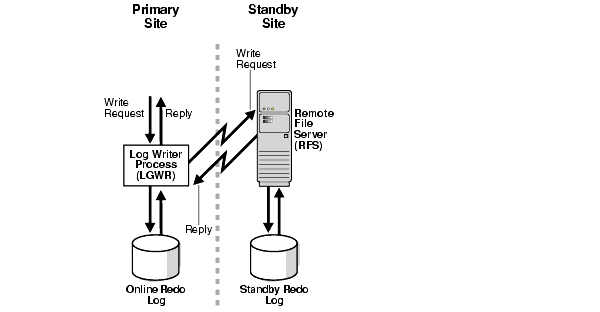
Text description of the illustration maxav005.gif
The following formulas emphasize that the remote write is always slower than the local write and is the limiting factor when LGWR synchronous writes are occurring.
Local write = local write I/O time Remote write = network round trip time (RTT) + local write I/O time (on standby machine)
Using an example in which the network round trip time (RTT) is 20 milliseconds and LGWR synchronous write is configured, every transaction commit time increases by 20 milliseconds. This overhead impacts response time and may affect primary database throughput. Because of the additional overhead incurred by the RTT, a local area network (LAN) or a metropolitan area network (MAN) with an RTT less than or equal to 10 milliseconds should be used for applications that cannot tolerate a change in performance or response time. Whether to use a LAN or MAN depends on the results of the performance assessment.
With only one remote standby destination within a LAN, with sufficient bandwidth and low latency, Oracle recommends the LGWR SYNC=NOPARALLEL AFFIRM option for the best performance with maximum data protection capabilities. When no data loss is required and there is only one remote archive destination, SYNC=NOPARALLEL performs better than SYNC=PARALLEL (the default) with a single standby destination.
If SYNC=PARALLEL is used, then the network I/O is initiated asynchronously, so that I/O to multiple destinations can be initiated in parallel. However, after the I/O is initiated, LGWR waits for each I/O operation to complete before continuing. This is, in effect, the same as performing multiple synchronous I/O operations simultaneously. If the Data Guard configuration has more than one standby database, then use a cascading standby architecture to minimize overhead to the primary database. If business requirements stipulate that the production database must transfer to multiple standby databases, then set SYNC=PARALLEL.
See Also:
|
The ARCH attribute of the LOG_ARCHIVE_DEST_n initialization parameter provides the greatest performance throughput but the greatest data loss potential. ARCH does not affect primary performance when latency increases as long as the redo logs are configured correctly as described in "Configure the Size of Redo Log Files and Groups Appropriately". This is recommended for maximum performance data protection mode and is the default.
The effects of latency on primary throughput are detailed in the following white paper.
| See Also:
"Oracle9i Data Guard: Primary Site and Network Configuration Best Practices" at |
The largest LGWR ASYNC buffer of 50 MB (ASYNC=102400) performs best in a WAN. In LAN tests, different asynchronous buffer sizes did not impact the primary database throughput. Using the maximum buffer size also increases the chance of avoiding timeout messages that result from an "async buffer full" condition in a WAN.
If the network buffer becomes full and remains full for 5 seconds, then the transport times out and converts to the ARCH transport. This condition indicates that the network to the standby destination cannot keep up with the redo generation rate on the primary database. This indicated in the alert log by the following message:
'Timing out on NetServer %d prod=%d,cons=%d,threshold=%d"
This message indicates that the standby destination configured with the LGWR ASYNC attributes encountered an "async buffer full" condition. When this occurs, log transport services automatically stop using the network server process to transmit the redo data and convert to using the archiver process (ARCn) until a log switch occurs. The next log transmission reverts to the ASYNC transport. This change occurs automatically. Using the largest asynchronous network buffer, 30MB, increases the chance of avoiding the transport converting to ARCH and potentially losing more data.
Figure 7-2 shows the architecture when the standby protection mode is set to maximum performance with LGWR ASYNC configuration. The LGWR request is buffered if sufficient space is available in the network buffer. If the production database fails and is inaccessible, then the data in the network buffer is lost, which usually means seconds of data loss in high OLTP applications.
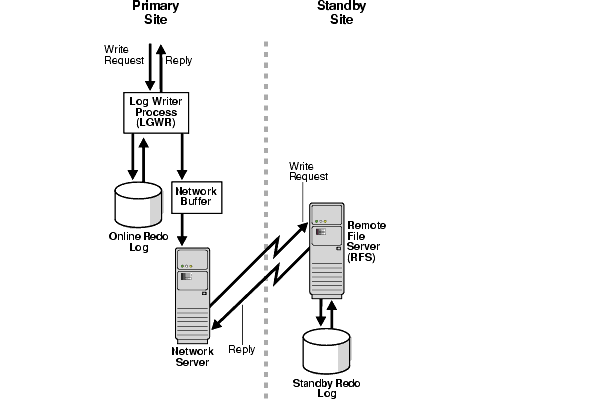
Text description of the illustration maxav006.gif
Evaluate SSH port forwarding with compression for maximum performance mode over a high-latency WAN (RTT greater than 100 milliseconds). Coupled with using LGWR ASYNC, the maximum buffer size, SSH with compression reduces the chance of receiving an "async buffer full" timeout. It also reduces network traffic.
See Also:
|
Setting LOG_ARCHIVE_LOCAL_FIRST to TRUE enables the archiver processes to archive the local online redo log files on the primary database before transmitting the redo data to remote standby destinations. This is especially useful when the network to the standby databases is slow.
This is the default setting for LOG_ARCHIVE_LOCAL_FIRST.
Because a lack of security can directly affect availability, Data Guard provides a secure environment and prevents tampering with redo data as it is being transferred to the standby database. To enable secure transmission of redo data, set up every database in the Data Guard configuration to use a password file, and set the password for the SYS user identically on every system. The following is a summary of steps needed for each database in the Data Guard configuration:
REMOTE_LOGIN_PASSWORDFILE=[EXCLUSIVE | SHARED] initialization parameter on each instance.After you have performed these steps to set up security on every database in the Data Guard configuration, Data Guard transmits redo data only after the appropriate authentication checks using SYS credentials are successful. This authentication can be performed even if Oracle Advanced Security is not installed and provides some level of security when shipping redo data. To further protect redo data (for example, to encrypt redo data or to compute an integrity checksum value for redo traffic over the network to disallow redo tampering on the network), Oracle recommends that you install and use Oracle Advanced Security.
See Also:
|
Specify a unique name for the standby database. The name does not change even if the primary and standby databases reverse roles. The DB_UNIQUE_NAME parameter defaults to the value of the DB_NAME parameter.
Specify the DG_CONFIG attribute of the LOG_ARCHIVE_CONFIG initialization parameter so that it lists the DB_UNIQUE_NAME for the primary database and each standby database in the Data Guard configuration. By default, this parameter enables the primary database to send redo data to remote destinations and enables standby databases to receive redo data. The DG_CONFIG attribute must be set to enable the dynamic addition of a standby database to a Data Guard configuration that has a RAC primary database running in either maximum protection or maximum availability mode.
The following recommendation applies only to the physical standby database:
To use Oracle Data Guard with a physical standby database or to use any media recovery operation effectively, you need to tune your database recovery.
| See Also:
"Oracle9i Media Recovery Best Practices" at |
The following recommendations apply only to the logical standby database:
Use supplemental logging and primary key constraints on all production tables.
If your application ensures that the rows in a table are unique, then you can create a disabled primary key RELY constraint on the table. This avoids the overhead of maintaining a primary key on the primary database. To create a disabled RELY constraint on a primary database table, use the ALTER TABLE statement with a RELY DISABLE clause.
To improve the performance of SQL Apply, add an index to the columns that uniquely identify the row on the logical standby database. Failure to do this results in full table scans.
If the logical standby database is being used to remove reporting or decision support operations from the primary database, then you should probably reserve some of the parallel query slaves for such operations. Because the SQL Apply process by default uses all the parallel query slaves, setting the MAX_SERVERS initialization parameter enables a specified number of parallel query slaves to be reserved.
Table 7-5 shows examples of MAX_SERVERS values.
It is recommended that MAX_SERVERS be set initially to the larger of the following values: 9 or 3 plus 3 times CPU.
Increase the PARALLEL_MAX_SERVERS initialization parameter by the larger of 9 or 3 times CPU on both the primary and standby instances:
PARALLEL_MAX_SERVERS=current value + max(9, 3 +(3 x CPU))
The PARALLEL_MAX_SERVERS initialization parameter specifies the maximum number of parallel query processes that can be created on the database instance. With the exception of the coordinator process, all the processes that constitute the SQL Apply engine are created from the pool of parallel query processes. The SQL Apply engine, by default, uses all the parallel query processes available on the database instance. This behavior can be overridden by using the logical standby parameters
It is recommended that PARALLEL_MAX_SERVERS be increased by the value of MAX_SERVERS.
The logical standby database supports the following methods of data application:
FULL or READ_ONLY transaction consistency.TRANSACTION_CONSISTENCY to NONE.If the logical standby database will be used for reporting or decision support operations, then:
FULL.READ_ONLY.Database objects that do not need to be replicated to the standby database should be skipped by using the DBMS_LOGSTDBY.SKIP procedure. Skipping such objects reduces the processing of the the SQL Apply engine. Consider this recommendation in a decision support environment.
This section recommends configuration practices in addition to the ones that are discussed for the single-instance database, RAC, and Data Guard. These practices are recommended when MAA is employed (RAC and Data Guard are used on both sites).
This section includes the following topics:
In an MAA environment, the standby database uses RAC, and multiple standby instances are associated with the same standby database. Having multiple standby instances is not the same as having multiple standby databases. Only one instance can have the managed recovery process (MRP) or the logical standby apply process (LSP). The standby instance with the MRP or LSP is called the primary standby instance. All other standby instances are called secondary standby instances.
Having multiple standby instances for the same database on the cluster provides the following benefits:
Data Guard connect-time failover occurs when a connection request is forwarded to another listener if the connection fails. Connect-time failover is enabled by service registration, because the listener knows which available Oracle instance provides the requested service.
The following is an Oracle Net connection descriptor in the tnsnames.ora file:
sales.us.acme.com= (DESCRIPTION= (ADDRESS_LIST= (ADDRESS=(PROTOCOL=tcp)(HOST=sales1-server)(PORT=1521)) (ADDRESS=(PROTOCOL=tcp)(HOST=sales2-server)(PORT=1521))) (CONNECT_DATA= (SERVICE_NAME=sales.us.acme.com)))
Note that the SALES net service name contains multiple address lists (two because it is a two-node cluster) for the production and standby clusters. The second address list enables connect-time failover if the first connection fails. This works for all protection modes.
To add a network protocol address to an existing net service name or database service, use either Oracle Enterprise Manager or Oracle Net Manager.
While it is prudent that every database have a good backup, recovery using a backup is not always the fastest solution. Other available Oracle technologies, such as RAC, Data Guard, and flashback technology often provide faster means of recovering from an outage than restoring from backups.
A good backup and recovery strategy is still vital to the overall high availability solution and ensures that specific outages are recovered from in an acceptable amount of time. The following topics are included in this section:
See Also:
|
Recovery Manager (RMAN) uses server sessions to perform backup and recovery operations and stores metadata about backups in a repository. RMAN offers many advantages over typical user-managed backup methods, such as the ability to do online database backups without placing tablespaces in backup mode; support for incremental backups; data block integrity checks during backup and restore operations; and the ability to test backups and restores without actually performing the operation. RMAN automates backup and recovery, whereas the user-managed method requires you to keep track of all database files and backups. For example, instead of requiring you to locate backups for each datafile, copy them to the correct place using operating system commands, and choose which logs to apply; RMAN manages these tasks automatically. There are also capabilities of Oracle recovery that are only available when using RMAN, such as block media recovery.
Most production database unscheduled outages are either handled automatically by various database components or are resolved by using another technology to restore a backup. For example, some outages are handled best by using Flashback Database or the standby database. However, there are situations that require using database backups, including the following:
Perform regular backups.
During initial set-up of a standby database, a backup of the production database is required at the secondary site to create the initial standby database.
When a data failure, which includes block corruption and media failure, occurs in an environment that does not include Data Guard, the only method of recovery is using an existing backup. Even with Data Guard, the most efficient means of recovering from data failure may be restoring and recovering the affected object from an existing backup.
A double failure scenario affects the availability of both the production and standby databases. The only resolution of this situation is to re-create the production database from an available backup, then re-create the standby database. An example of a double failure scenario is a site outage at the secondary site, which eliminates fault tolerance, followed by a media failure on the production database. Some multiple failures, or more appropriately disasters (such as a primary site outage followed by a secondary site outage) may require the use of backups that exist in an offsite location, so developing and following a process to deliver and maintain backup tapes at an offsite location is necessary to restore service in the most dire of circumstances.
Some businesses require the ability to maintain long-term backups that may be needed years into the future. By using RMAN with the KEEP option, it is possible to retain backups that are exempt from the retention policy and never expire, providing the capability to restore and recover the database to any desired point in time. It is important that a recovery catalog be used for the RMAN repository so that backup metadata is not lost due to lack of space, which may occur when using the target database control file for the RMAN repository.
RMAN automatically manages the backup metadata in the control file of the database that is being backed up. To protect and keep backup metadata for long periods of time, the RMAN repository, usually referred to as a recovery catalog, is created in a separate database. There are many advantages of using a recovery catalog, including the ability to store backup information long-term, the ability to store metadata for multiple databases, and the ability to restore an available backup on to another system. In addition, if you are using only the target database control file to house the repository, the control file, with its limited maximum size, may not be large enough to hold all desired backup metadata. If the control file is too small to hold additional backup metadata, then existing backup information is overwritten, making it difficult to restore and recover using those backups.
RMAN can be configured to automatically back up the control file and server parameter file (SPFILE) whenever the database structure metadata in the control file changes and whenever a backup record is added. The autobackup enables RMAN to recover the database even if the current control file, catalog, and SPFILE are lost. The RMAN autobackup feature is enabled with the CONFIGURE CONTROLFILE AUTOBACKUP ON statement.
Oracle's incrementally updated backups feature enables you to create an image copy of a datafile, then regularly create incremental backups of the database and apply them to that image copy. The image copy is updated with all changes up through the SCN at which the incremental backup was taken. RMAN can use the resulting updated datafile in media recovery just as it would use a full image copy taken at that SCN, without the overhead of performing a full image copy of the database every day. A backup strategy based on incrementally updated backups can help minimize MTTR for media recovery.
Oracle's change tracking feature for incremental backups improves incremental backup performance by recording changed blocks in each datafile in a change tracking file. If change tracking is enabled, then RMAN uses the change tracking file to identify changed blocks for incremental backup, thus avoiding the need to scan every block in the datafile.
Using automatic disk-based backup and recovery, you can create a flash recovery area, which automates management of backup-related files. Choose a location on disk and an upper bound for storage space and set a retention policy that governs how long backup files are needed for recovery. Oracle manages the storage used for backup, archived redo logs, and other recovery-related files for your database within that space. Files no longer needed are eligible for deletion when RMAN needs to reclaim space for new files.
Use the BACKUP RECOVERY FILE DESTINATION RMAN command to move disk backups created in the flash recovery area to tape. Tape backups are used for offsite and long-term storage and are used to handle certain outage scenarios.
The backup retention policy is the rule set regarding which backups must be retained (on disk or other backup media) to meet recovery and other requirements. It may be safe to delete a specific backup because it is old enough to be superseded by more recent backups or because it has been stored on tape. You may also need to retain a specific backup on disk for other reasons such as archival requirements. A backup that is no longer needed to satisfy the backup retention policy is said to be obsolete.
Backup retention policy can be based on redundancy or a recovery window. In a redundancy-based retention policy, you specify a number n such that you always keep at least n distinct backups of each file in your database. In a recovery window-based retention policy, you specify a time interval in the past (for example, one week or one month) and keep all backups required to let you perform point-in-time recovery to any point during that window.
Frequent backups are essential for any recovery scheme. Base the frequency of backups on the rate or frequency of database changes such as:
The more frequently your database is updated, the more often you should perform database backups. If database updates are relatively infrequent, then you can make whole database backups infrequently and supplement them with incremental backups, which will be relatively small because few blocks have changed.
Configuring the size of the flash recovery area properly enables fast recovery from user error with Flashback Database and fast recovery from data failure with file or block media recovery from disk. The appropriate size of the flash recovery area depends on the following: retention policy, backup frequency, size of the database, rate and number of changes to the database. Specific formulas for determining the proper size of the flash recovery area for different backup scenarios are provided in Oracle Database Backup and Recovery Basics.
Take backups at the primary and secondary sites. The advantages of this practice are as follows:
Consider a scenario in which backups are done only at the secondary site. Suppose there is a site outage at the secondary site where the estimated time to recover is three days. The primary site is completely vulnerable to an outage that is typically resolved by a failover, also to any outage that could be resolved by having a local backup (such as a data failure outage resolved by block media recovery). In this scenario, a production database outage can be resolved only by physically shipping the off-site tape backups that were taken at the standby site. If primary site backups were available, then restoring locally would be an available option in place of the failover than cannot be done. Data may be lost, but having primary site backups significantly shortens the MTTR.
Another undesirable approach is to start taking primary site backups at the time that there is a secondary site outage. However, this approach should be avoided because it is introducing new processes and procedures at a time when the environment is already under duress and the impact of a mistake by staff will be magnified. Also, it is not a time to learn that backups cannot be taken at the primary site.
In addition, primary site disk backups are necessary to ensure a reasonable MTTR when using RMAN file or block media recovery. Without a local on-disk backup, a backup taken at the standby site must be restored to the primary site, significantly lengthening the MTTR for this type of outage.
During backups, use the target database control file as the RMAN repository and resynchronize afterward with the RMAN RESYNC CATALOG command.
When creating backups to disk or tape, use the target database control file as the RMAN repository so that the ability to back up or the success of the backup does not depend on the availability of the RMAN catalog in the manageability database. This is accomplished by running RMAN with the NOCATALOG option. After the backup is complete, the new backup information stored in the target database control file can be resynchronized with the recovery catalog using the RESYNC CATALOG command.
Using the BACKUP VALIDATE RMAN command, database files should be checked regularly for block corruptions that have not yet been reported by a user session or by normal backup operations. RMAN scans the specified files and verifies content-checking for physical and logical errors but does not actually perform the backup or recovery operation. Oracle records the address of the corrupt block and the type of corruption in the control file. Access these records through the V$DATABASE_BLOCK_CORRUPTION view, which can be used by RMAN block media recovery.
If BLOCK CHANGE TRACKING is enabled, then do not use the INCREMENTAL LEVEL option with BACKUP VALIDATE to ensure that all data blocks are read and verified.
To detect all types of corruption that are possible to detect:
MAXCORRUPT optionNOCHECKSUM optionCHECK LOGICAL optionComplete, successful, and tested backups are fundamental to the success of any recovery. Create test plans for the different outage types. Start with the most common outage types and progress to the least probable. Issuing backup procedures does not ensure that the backups are successful; they must be rehearsed. Monitor the backup procedure for errors, and validate backups by testing your recovery procedures periodically. Also, validate the ability to do backups and restores by using the RMAN commands BACKUP VALIDATE and RESTORE... VALIDATE commands.
The Oracle Cluster Registry (OCR) contains cluster and database configuration information for RAC and Cluster Ready Services (CRS), such as the cluster database node list, CRS application resource profiles, and Event Manager (EVM) authorizations. Using the ocrconfig tool, there are two methods of copying OCR content and using the content for recovery. The first method uses automatically generated physical OCR file copies. The second method uses manually created logical OCR export files. The backup file created with ocrconfig should be backed as part of the operating system backup using standard operating system or third-party tools.
In any high availability architecture, client and mid-tier applications can be redirected to available services within a Real Application Cluster and with some customization to a Data Guard or replicated database. This redirection can usually be transparent and can be used to reduce or eliminate both planned and unplanned downtime to the client or mid-tier application.
Services are prerequisites for fast, transparent application failover. When you create services in RAC, you can assign the services to instances for preferred (normal) and available (recovery) processing. When an instance to which you have assigned a service becomes unavailable, RAC can reconnect users connected to that instance to an available instance without service interruptions. Clients and mid-tier applications make connection requests by specifying a service using a global name. The connection information must be aware of all potential production instances or databases that can publish that service. Services enable you to model and deploy both planned and unplanned operations for any type of high availability or disaster recovery scenario.
To respond to changes in the cluster database, RAC's Cluster Ready Services (CRS), event system, and service callouts can be used to notify clients and mid-tier applications automatically. Event notifications can be configured to initiate recovery processing after failures to eliminate network timeouts and to provide end-to-end control over essential resources. These rapid notifications are done automatically from RAC to JDBC clients through JDBC fast connection failover. However, RAC provides a robust callout and event system that enables the user to customize specialized callouts to respond to database UP and DOWN events. Use these callouts to notify middle-tier applications to interrupt existing problematic connections and redirect new connections to available resources.
For disaster recovery, the new production database can also be configured to publish the production service while stopping the services on the old production database. Again, callouts are required to notify the mid-tier applications.
To configure for fast application failover, follow these recommendations for middle-tier applications and clients:
Follow this recommendation for all databases:
Follow these recommendation for RAC:
Follow these recommendations for Data Guard, replicated, or distributed environments:
Clients and mid-tier applications make connection requests by specifying a service using a global name. The connection information must be aware of all potential production instances or databases that are capable of publishing that service. Furthermore, these connection descriptors should ideally be stored in an LDAP or Oracle Name server for ease of maintenance and administration.
This section includes three sample Oracle Net connection descriptors. Use the PROD_RAC connection descriptor in Example 7-1when there is no standby database available or if DNS site failover is deployed.
The PROD_RAC_DG connection descriptor in Example 7-2 has an address list that contains all production RAC instances and the Data Guard standby instances. This example can be used in the case of a production database outage when the hardware cluster is still available. It helps you avoid TCP/IP timeouts.
When the entire hardware cluster fails, the connection needs to be manually adjusted to point to the standby database using the connection descriptor provided in Example 7-3.
For disaster recovery, client-side DNS failover or site failover is recommended over listing both production instances and standby database instances.
PROD_RAC= (DESCRIPTION = (ADDRESS_LIST = (LOAD_BALANCE=on) (ADDRESS = (PROTOCOL = TCP)(HOST = RAC_INSTANCE1)(PORT = 1520)) (ADDRESS = (PROTOCOL = TCP)(HOST = RAC_INSTANCE2)(PORT = 1520)) (ADDRESS = (PROTOCOL = TCP)(HOST = RAC_INSTANCE3)(PORT = 1520)) (ADDRESS = (PROTOCOL = TCP)(HOST = RAC_INSTANCE4)(PORT = 1520)) (CONNECT_DATA = (SERVICE_NAME = MAA_PROD)))
PROD_RAC_DG= (DESCRIPTION = (ADDRESS_LIST = (LOAD_BALANCE=on) (ADDRESS = (PROTOCOL = TCP)(HOST = RAC_INSTANCE1)(PORT = 1520)) (ADDRESS = (PROTOCOL = TCP)(HOST = RAC_INSTANCE2)(PORT = 1520)) (ADDRESS = (PROTOCOL = TCP)(HOST = RAC_INSTANCE3)(PORT = 1520)) (ADDRESS = (PROTOCOL = TCP)(HOST = RAC_INSTANCE4)(PORT = 1520)) (ADDRESS = (PROTOCOL = TCP)(HOST = DG_INSTANCE1)(PORT = 1520)) (ADDRESS = (PROTOCOL = TCP)(HOST = DG_INSTANCE2)(PORT = 1520))) (CONNECT_DATA = (SERVICE_NAME = MAA_PROD)))
PROD_DR= (DESCRIPTION = (ADDRESS_LIST = (LOAD_BALANCE=on) (ADDRESS = (PROTOCOL = TCP)(HOST = DG_INSTANCE1)(PORT = 1520)) (ADDRESS = (PROTOCOL = TCP)(HOST = DG_INSTANCE2)(PORT = 1520))) (CONNECT_DATA = (SERVICE_NAME = MAA_PROD)))
Ideally, the middle-tier applications and clients should use the automatic RAC availability notifications and events. Applications that use Oracle Database 10g JDBC fast connection failover subscribe to these events automatically. Other applications may need to configure these service callouts and modify the applications to react to them.
If you cannot use RAC notification or if RAC is not deployed, then use Transparent Application Failover (TAF). When Oracle Call Interface (OCI) client applications are used, Transparent Application Failover (TAF) can be configured to transparently fail over connections between an application server and a database server.
OCI client applications can take advantage of automatic reconnection after failover and callback functions that help to automate state recovery. They can also replay interrupted SELECT statements and callback functions that help to automate state recovery. The Oracle JDBC and ODBC drivers also support automatic database reconnection and replay of interrupted SELECT statements without the need for any additional application coding.
The TAF configuration is specified in the connect string that clients use to connect to the database.
The following sample TAF connection descriptor is used to describe the impact of TAF and how to use each component.
PROD= (DESCRIPTION = (FAILOVER=on) (ADDRESS_LIST = (LOAD_BALANCE=on) (ADDRESS = (PROTOCOL = TCP)(HOST = RAC_INSTANCE1)(PORT = 1520)) (ADDRESS = (PROTOCOL = TCP)(HOST = RAC_INSTANCE2)(PORT = 1520)) (ADDRESS = (PROTOCOL = TCP)(HOST = RAC_INSTANCE3)(PORT = 1520)) (ADDRESS = (PROTOCOL = TCP)(HOST = RAC_INSTANCE4)(PORT = 1520)) (ADDRESS = (PROTOCOL = TCP)(HOST = DG_INSTANCE1)(PORT = 1520)) (ADDRESS = (PROTOCOL = TCP)(HOST = DG_INSTANCE2)(PORT = 1520))) (CONNECT_DATA = (SERVICE_NAME = MAA_PROD) (FAILOVER_MODE = (BACKUP=PROD_BACKUP)(TYPE=SESSION)(METHOD=BASIC) (RETRIES=12)(DELAY=5)))) PROD_BACKUP= (DESCRIPTION = (FAILOVER=on) (ADDRESS_LIST = (LOAD_BALANCE=on) (ADDRESS = (PROTOCOL = TCP)(HOST = RAC_INSTANCE1)(PORT = 1520)) (ADDRESS = (PROTOCOL = TCP)(HOST = RAC_INSTANCE2)(PORT = 1520)) (ADDRESS = (PROTOCOL = TCP)(HOST = RAC_INSTANCE3)(PORT = 1520)) (ADDRESS = (PROTOCOL = TCP)(HOST = RAC_INSTANCE4)(PORT = 1520)) (ADDRESS = (PROTOCOL = TCP)(HOST = DG_INSTANCE1)(PORT = 1520)) (ADDRESS = (PROTOCOL = TCP)(HOST = DG_INSTANCE2)(PORT = 1520))) (CONNECT_DATA = (SERVICE_NAME = MAA_PROD) (FAILOVER_MODE = (BACKUP=PROD)(TYPE=SESSION)(METHOD=BASIC) (RETRIES=12)(DELAY=5))))
New connections use the address list and connect to the first available listener that has the service (MAA_PROD) registered. This is true for both instance and listener failure. If there is an attempt to connect to a failed node, then a TCP/IP timeout occurs. Retries and delay have no effect on new connections because new connections attempt the address list only once.
Existing connections use the backup connection descriptor and wait the number of seconds specified by DELAY between each iteration. After attempting all addresses in the backup connection descriptor, the client waits the number of seconds specified by DELAY before attempting the address list again. The client retries the address list up to the number of times specified by RETRIES. If the service is not available anywhere after the number of seconds that is equal to RETRIES times DELAY, then the client receives an ORA-3113 error. The maximum switchover or failover times should be less than RETRIES*DELAY if you want automatic client failover to a disaster recovery site.
LOAD_BALANCE sets the client-side load balancing. When it is set to ON, the client randomly selects an address from the address list. If a listener has multiple instances registered with it that offer the same service, then the listener can balance client requests between the instances based on the load on the instances at that time.
Set FAILOVER to ON. The client fails through the address list if one or more of the services, instances, listeners, or nodes on the list is down or not available.
The service name is published by the database to the listener.
This parameter determines how many times an existing connection retries the addresses in the BACKUP list or after a failover. This parameter has no effect on new connections. New clients go through the address list only once.
This parameter determines the number of seconds the client waits between each retry. After going through the address list, the client waits for the number of seconds specified by DELAY before retrying. There is no delay between individual addresses in the address list. The delay applies only after the whole list has been traversed.
With RAC, TCP/IP timeouts due to an unavailable node in a cluster are avoided because RAC manages a Virtual Internet Protocol (VIP) and cluster alias. However, TCP/IP timeouts cannot be avoided when the entire cluster or non-RAC host is not available. To avoid this TCP/IP timeout, the customer should do one of the following:
The customized callout should interrupt existing connections and redirect new connections with a new connection descriptor that does not contain the unavailable nodes or clusters.
Adjusting TCP/IP parameters may have other application and system impact, so always use caution. However, the following TCP/IP parameters were modified on a Solaris platform to reduce overall TCP/IP timeout intervals in Oracle testing:
Check your operating system platform documentation for similar parameters.
Within RAC, use the Database Configuration Assistant (DBCA), Server Control (SRVCTL), or the DBMS_SERVICE PL/SQL package to create services. Then use the DBCA or Enterprise Manager to administer them. If this is a non-RAC environment, then set the SERVICE_NAME database initialization parameter.
CRS supports services and the workload management framework that maintains continuous availability of the services. CRS also supports the other RAC resources such as the database, the database cluster aliases, and the resources that are local to every node that supports RAC.
Node resources include the virtual internet protocol (VIP) address for the node, the Global Services Daemon, the Enterprise Manager Agent, and the Oracle Net listeners. These resources are automatically started when CRS starts with the node and CRS automatically restarts them if they fail.
Configure service callouts to notify middle-tier applications and clients about UP, DOWN, and NOT_RESTARTING events. RAC automatically notifies JDBC clients through JDBC fast connection failover without any adjustments. In the rare case that the entire RAC cluster fails, a separate notification and callout is required to notify the middle-tier applications to connect to a disaster recovery or secondary database.
If the middle-tier application or clients are not JDBC clients, then you must use RAC's event management and service callout facilities to configure a customized callout. The callout needs to notify the middle-tier application to do the following:
Interrupting existing connections helps avoid long TCP/IP timeout delays. Redirecting new connections to available production instances or nodes may require passing a new connection descriptor that does not include any inaccessible hosts so that TCP/IP timeouts can be avoided.
When RAC and Enterprise Manager are integrated, standby or nonproduction services can be published automatically. If the standby database is not managed by Enterprise Manager or is not part of a RAC environment, then you can manually alter the SERVICE_NAME database initialization parameter to be a nonproduction service. For example:
SQL> ALTER SYSTEM SET SERVICE_NAME='STANDBY';
When RAC and Enterprise Manager are integrated, production services can be published automatically. If the new production database is not managed by Enterprise Manager or is not part of a RAC environment, then you can manually alter the SERVICE_NAME database initialization parameter to be set to different production services. For example:
SQL> ALTER SYSTEM SET SERVICE_NAME='PROD_SVC1, PROD_SVC2, PROD_SVC3';
PROD_SVC1 can be SALES or HR, for example.
|
 Copyright © 2003 Oracle Corporation All Rights Reserved. |
|

